 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning to Reason for Hallucination Span Detection
Oct 02, 2025



Large language models (LLMs) often generate hallucinations -- unsupported content that undermines reliability. While most prior works frame hallucination detection as a binary task, many real-world applications require identifying hallucinated spans, which is a multi-step decision making process. This naturally raises the question of whether explicit reasoning can help the complex task of detecting hallucination spans. To answer this question, we first evaluate pretrained models with and without Chain-of-Thought (CoT) reasoning, and show that CoT reasoning has the potential to generate at least one correct answer when sampled multiple times. Motivated by this, we propose RL4HS, a reinforcement learning framework that incentivizes reasoning with a span-level reward function. RL4HS builds on Group Relative Policy Optimization and introduces Class-Aware Policy Optimization to mitigate reward imbalance issue. Experiments on the RAGTruth benchmark (summarization, question answering, data-to-text) show that RL4HS surpasses pretrained reasoning models and supervised fine-tuning, demonstrating the necessity of reinforcement learning with span-level rewards for detecting hallucination spans.
Synthetic Visual Genome
Jun 09, 2025Reasoning over visual relationships-spatial, functional, interactional, social, etc.-is considered to be a fundamental component of human cognition. Yet, despite the major advances in visual comprehension in multimodal language models (MLMs), precise reasoning over relationships and their generations remains a challenge. We introduce ROBIN: an MLM instruction-tuned with densely annotated relationships capable of constructing high-quality dense scene graphs at scale. To train ROBIN, we curate SVG, a synthetic scene graph dataset by completing the missing relations of selected objects in existing scene graphs using a teacher MLM and a carefully designed filtering process to ensure high-quality. To generate more accurate and rich scene graphs at scale for any image, we introduce SG-EDIT: a self-distillation framework where GPT-4o further refines ROBIN's predicted scene graphs by removing unlikely relations and/or suggesting relevant ones. In total, our dataset contains 146K images and 5.6M relationships for 2.6M objects. Results show that our ROBIN-3B model, despite being trained on less than 3 million instances, outperforms similar-size models trained on over 300 million instances on relationship understanding benchmarks, and even surpasses larger models up to 13B parameters. Notably, it achieves state-of-the-art performance in referring expression comprehension with a score of 88.9, surpassing the previous best of 87.4. Our results suggest that training on the refined scene graph data is crucial to maintaining high performance across diverse visual reasoning task.
FocalLens: Instruction Tuning Enables Zero-Shot Conditional Image Representations
Apr 11, 2025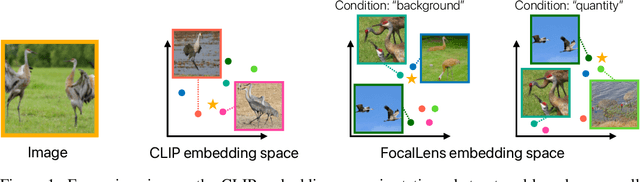
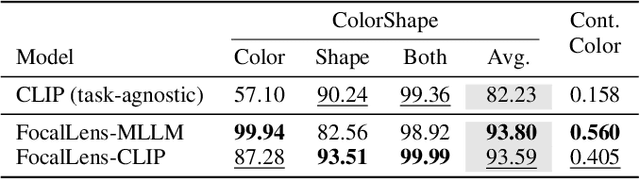
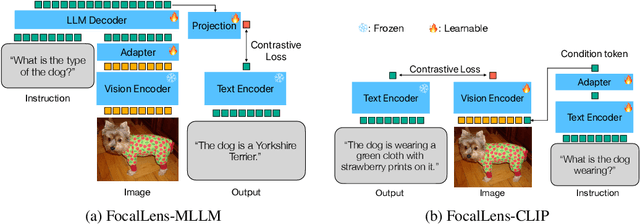
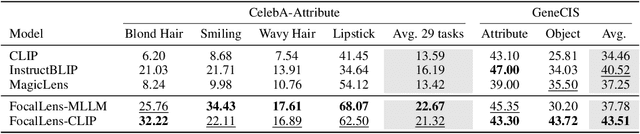
Visual understanding is inherently contextual -- what we focus on in an image depends on the task at hand. For instance, given an image of a person holding a bouquet of flowers, we may focus on either the person such as their clothing, or the type of flowers, depending on the context of interest. Yet, most existing image encoding paradigms represent an image as a fixed, generic feature vector, overlooking the potential needs of prioritizing varying visual information for different downstream use cases. In this work, we introduce FocalLens, a conditional visual encoding method that produces different representations for the same image based on the context of interest, expressed flexibly through natural language. We leverage vision instruction tuning data and contrastively finetune a pretrained vision encoder to take natural language instructions as additional inputs for producing conditional image representations. Extensive experiments validate that conditional image representation from FocalLens better pronounce the visual features of interest compared to generic features produced by standard vision encoders like CLIP. In addition, we show FocalLens further leads to performance improvements on a range of downstream tasks including image-image retrieval, image classification, and image-text retrieval, with an average gain of 5 and 10 points on the challenging SugarCrepe and MMVP-VLM benchmarks, respectively.
REALEDIT: Reddit Edits As a Large-scale Empirical Dataset for Image Transformations
Feb 05, 2025



Existing image editing models struggle to meet real-world demands. Despite excelling in academic benchmarks, they have yet to be widely adopted for real user needs. Datasets that power these models use artificial edits, lacking the scale and ecological validity necessary to address the true diversity of user requests. We introduce REALEDIT, a large-scale image editing dataset with authentic user requests and human-made edits sourced from Reddit. REALEDIT includes a test set of 9300 examples to evaluate models on real user requests. Our results show that existing models fall short on these tasks, highlighting the need for realistic training data. To address this, we introduce 48K training examples and train our REALEDIT model, achieving substantial gains - outperforming competitors by up to 165 Elo points in human judgment and 92 percent relative improvement on the automated VIEScore metric. We deploy our model on Reddit, testing it on new requests, and receive positive feedback. Beyond image editing, we explore REALEDIT's potential in detecting edited images by partnering with a deepfake detection non-profit. Finetuning their model on REALEDIT data improves its F1-score by 14 percentage points, underscoring the dataset's value for broad applications.
NVILA: Efficient Frontier Visual Language Models
Dec 05, 2024



Visual language models (VLMs) have made significant advances in accuracy in recent years. However, their efficiency has received much less attention. This paper introduces NVILA, a family of open VLMs designed to optimize both efficiency and accuracy. Building on top of VILA, we improve its model architecture by first scaling up the spatial and temporal resolutions, and then compressing visual tokens. This "scale-then-compress" approach enables NVILA to efficiently process high-resolution images and long videos. We also conduct a systematic investigation to enhance the efficiency of NVILA throughout its entire lifecycle, from training and fine-tuning to deployment. NVILA matches or surpasses the accuracy of many leading open and proprietary VLMs across a wide range of image and video benchmarks. At the same time, it reduces training costs by 4.5X, fine-tuning memory usage by 3.4X, pre-filling latency by 1.6-2.2X, and decoding latency by 1.2-2.8X. We will soon make our code and models available to facilitate reproducibility.
Perception Tokens Enhance Visual Reasoning in Multimodal Language Models
Dec 04, 2024Multimodal language models (MLMs) still face challenges in fundamental visual perception tasks where specialized models excel. Tasks requiring reasoning about 3D structures benefit from depth estimation, and reasoning about 2D object instances benefits from object detection. Yet, MLMs can not produce intermediate depth or boxes to reason over. Finetuning MLMs on relevant data doesn't generalize well and outsourcing computation to specialized vision tools is too compute-intensive and memory-inefficient. To address this, we introduce Perception Tokens, intrinsic image representations designed to assist reasoning tasks where language is insufficient. Perception tokens act as auxiliary reasoning tokens, akin to chain-of-thought prompts in language models. For example, in a depth-related task, an MLM augmented with perception tokens can reason by generating a depth map as tokens, enabling it to solve the problem effectively. We propose AURORA, a training method that augments MLMs with perception tokens for improved reasoning over visual inputs. AURORA leverages a VQVAE to transform intermediate image representations, such as depth maps into a tokenized format and bounding box tokens, which is then used in a multi-task training framework. AURORA achieves notable improvements across counting benchmarks: +10.8% on BLINK, +11.3% on CVBench, and +8.3% on SEED-Bench, outperforming finetuning approaches in generalization across datasets. It also improves on relative depth: over +6% on BLINK. With perception tokens, AURORA expands the scope of MLMs beyond language-based reasoning, paving the way for more effective visual reasoning capabilities.
Is C4 Dataset Optimal for Pruning? An Investigation of Calibration Data for LLM Pruning
Oct 09, 2024



Network pruning has emerged as a potential solution to make LLMs cheaper to deploy. However, existing LLM pruning approaches universally rely on the C4 dataset as the calibration data for calculating pruning scores, leaving its optimality unexplored. In this study, we evaluate the choice of calibration data on LLM pruning, across a wide range of datasets that are most commonly used in LLM training and evaluation, including four pertaining datasets as well as three categories of downstream tasks encompassing nine datasets. Each downstream dataset is prompted with In-Context Learning (ICL) and Chain-of-Thought (CoT), respectively. Besides the already intriguing observation that the choice of calibration data significantly impacts the performance of pruned LLMs, our results also uncover several subtle and often unexpected findings, summarized as follows: (1) C4 is not the optimal choice for LLM pruning, even among commonly used pre-training datasets; (2) arithmetic datasets, when used as calibration data, performs on par or even better than pre-training datasets; (3) pruning with downstream datasets does not necessarily help the corresponding downstream task, compared to pre-training data; (4) ICL is widely beneficial to all data categories, whereas CoT is only useful on certain tasks. Our findings shed light on the importance of carefully selecting calibration data for LLM pruning and pave the way for more efficient deployment of these powerful models in real-world applications. We release our code at: https://github.com/abx393/llm-pruning-calibration-data.
The Hard Positive Truth about Vision-Language Compositionality
Sep 26, 2024Several benchmarks have concluded that our best vision-language models (e.g., CLIP) are lacking in compositionality. Given an image, these benchmarks probe a model's ability to identify its associated caption amongst a set of compositional distractors. In response, a surge of recent proposals show improvements by finetuning CLIP with distractors as hard negatives. Our investigations reveal that these improvements have, in fact, been significantly overstated -- because existing benchmarks do not probe whether finetuned vision-language models remain invariant to hard positives. By curating an evaluation dataset with 112,382 hard negatives and hard positives, we uncover that including hard positives decreases CLIP's performance by 12.9%, while humans perform effortlessly at 99%. CLIP finetuned with hard negatives results in an even larger decrease, up to 38.7%. With this finding, we then produce a 1,775,259 image-text training set with both hard negative and hard positive captions. By training with both, we see improvements on existing benchmarks while simultaneously improving performance on hard positives, indicating a more robust improvement in compositionality. Our work suggests the need for future research to rigorously test and improve CLIP's understanding of semantic relationships between related "positive" concepts.
Graph-Based Captioning: Enhancing Visual Descriptions by Interconnecting Region Captions
Jul 09, 2024



Humans describe complex scenes with compositionality, using simple text descriptions enriched with links and relationships. While vision-language research has aimed to develop models with compositional understanding capabilities, this is not reflected yet in existing datasets which, for the most part, still use plain text to describe images. In this work, we propose a new annotation strategy, graph-based captioning (GBC) that describes an image using a labelled graph structure, with nodes of various types. The nodes in GBC are created using, in a first stage, object detection and dense captioning tools nested recursively to uncover and describe entity nodes, further linked together in a second stage by highlighting, using new types of nodes, compositions and relations among entities. Since all GBC nodes hold plain text descriptions, GBC retains the flexibility found in natural language, but can also encode hierarchical information in its edges. We demonstrate that GBC can be produced automatically, using off-the-shelf multimodal LLMs and open-vocabulary detection models, by building a new dataset, GBC10M, gathering GBC annotations for about 10M images of the CC12M dataset. We use GBC10M to showcase the wealth of node captions uncovered by GBC, as measured with CLIP training. We show that using GBC nodes' annotations -- notably those stored in composition and relation nodes -- results in significant performance boost on downstream models when compared to other dataset formats. To further explore the opportunities provided by GBC, we also propose a new attention mechanism that can leverage the entire GBC graph, with encouraging experimental results that show the extra benefits of incorporating the graph structure. Our datasets are released at \url{https://huggingface.co/graph-based-captions}.
Lookback Lens: Detecting and Mitigating Contextual Hallucinations in Large Language Models Using Only Attention Maps
Jul 09, 2024When asked to summarize articles or answer questions given a passage, large language models (LLMs) can hallucinate details and respond with unsubstantiated answers that are inaccurate with respect to the input context. This paper describes a simple approach for detecting such contextual hallucinations. We hypothesize that contextual hallucinations are related to the extent to which an LLM attends to information in the provided context versus its own generations. Based on this intuition, we propose a simple hallucination detection model whose input features are given by the ratio of attention weights on the context versus newly generated tokens (for each attention head). We find that a linear classifier based on these lookback ratio features is as effective as a richer detector that utilizes the entire hidden states of an LLM or a text-based entailment model. The lookback ratio-based detector -- Lookback Lens -- is found to transfer across tasks and even models, allowing a detector that is trained on a 7B model to be applied (without retraining) to a larger 13B model. We further apply this detector to mitigate contextual hallucinations, and find that a simple classifier-guided decoding approach is able to reduce the amount of hallucination, for example by 9.6% in the XSum summarization task.