 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMedAD-R1: Eliciting Consistent Reasoning in Interpretible Medical Anomaly Detection via Consistency-Reinforced Policy Optimization
Feb 01, 2026Medical Anomaly Detection (MedAD) presents a significant opportunity to enhance diagnostic accuracy using Large Multimodal Models (LMMs) to interpret and answer questions based on medical images. However, the reliance on Supervised Fine-Tuning (SFT) on simplistic and fragmented datasets has hindered the development of models capable of plausible reasoning and robust multimodal generalization. To overcome this, we introduce MedAD-38K, the first large-scale, multi-modal, and multi-center benchmark for MedAD featuring diagnostic Chain-of-Thought (CoT) annotations alongside structured Visual Question-Answering (VQA) pairs. On this foundation, we propose a two-stage training framework. The first stage, Cognitive Injection, uses SFT to instill foundational medical knowledge and align the model with a structured think-then-answer paradigm. Given that standard policy optimization can produce reasoning that is disconnected from the final answer, the second stage incorporates Consistency Group Relative Policy Optimization (Con-GRPO). This novel algorithm incorporates a crucial consistency reward to ensure the generated reasoning process is relevant and logically coherent with the final diagnosis. Our proposed model, MedAD-R1, achieves state-of-the-art (SOTA) performance on the MedAD-38K benchmark, outperforming strong baselines by more than 10\%. This superior performance stems from its ability to generate transparent and logically consistent reasoning pathways, offering a promising approach to enhancing the trustworthiness and interpretability of AI for clinical decision support.
Digital Twin AI: Opportunities and Challenges from Large Language Models to World Models
Jan 04, 2026Digital twins, as precise digital representations of physical systems, have evolved from passive simulation tools into intelligent and autonomous entities through the integration of artificial intelligence technologies. This paper presents a unified four-stage framework that systematically characterizes AI integration across the digital twin lifecycle, spanning modeling, mirroring, intervention, and autonomous management. By synthesizing existing technologies and practices, we distill a unified four-stage framework that systematically characterizes how AI methodologies are embedded across the digital twin lifecycle: (1) modeling the physical twin through physics-based and physics-informed AI approaches, (2) mirroring the physical system into a digital twin with real-time synchronization, (3) intervening in the physical twin through predictive modeling, anomaly detection, and optimization strategies, and (4) achieving autonomous management through large language models, foundation models, and intelligent agents. We analyze the synergy between physics-based modeling and data-driven learning, highlighting the shift from traditional numerical solvers to physics-informed and foundation models for physical systems. Furthermore, we examine how generative AI technologies, including large language models and generative world models, transform digital twins into proactive and self-improving cognitive systems capable of reasoning, communication, and creative scenario generation. Through a cross-domain review spanning eleven application domains, including healthcare, aerospace, smart manufacturing, robotics, and smart cities, we identify common challenges related to scalability, explainability, and trustworthiness, and outline directions for responsible AI-driven digital twin systems.
Better Datasets Start From RefineLab: Automatic Optimization for High-Quality Dataset Refinement
Nov 09, 2025High-quality Question-Answer (QA) datasets are foundational for reliable Large Language Model (LLM) evaluation, yet even expert-crafted datasets exhibit persistent gaps in domain coverage, misaligned difficulty distributions, and factual inconsistencies. The recent surge in generative model-powered datasets has compounded these quality challenges. In this work, we introduce RefineLab, the first LLM-driven framework that automatically refines raw QA textual data into high-quality datasets under a controllable token-budget constraint. RefineLab takes a set of target quality attributes (such as coverage and difficulty balance) as refinement objectives, and performs selective edits within a predefined token budget to ensure practicality and efficiency. In essence, RefineLab addresses a constrained optimization problem: improving the quality of QA samples as much as possible while respecting resource limitations. With a set of available refinement operations (e.g., rephrasing, distractor replacement), RefineLab takes as input the original dataset, a specified set of target quality dimensions, and a token budget, and determines which refinement operations should be applied to each QA sample. This process is guided by an assignment module that selects optimal refinement strategies to maximize overall dataset quality while adhering to the budget constraint. Experiments demonstrate that RefineLab consistently narrows divergence from expert datasets across coverage, difficulty alignment, factual fidelity, and distractor quality. RefineLab pioneers a scalable, customizable path to reproducible dataset design, with broad implications for LLM evaluation.
SPA: Achieving Consensus in LLM Alignment via Self-Priority Optimization
Nov 09, 2025In high-stakes scenarios-such as self-harm, legal, or medical queries-LLMs must be both trustworthy and helpful. However, these goals often conflict. We propose priority alignment, a new alignment paradigm that enforces a strict "trustworthy-before-helpful" ordering: optimization of helpfulness is conditioned on first meeting trustworthy thresholds (e.g., harmlessness or honesty). To realize this, we introduce Self-Priority Alignment (SPA)-a fully unsupervised framework that generates diverse responses, self-evaluates them and refines them by the model itself, and applies dual-criterion denoising to remove inconsistency and control variance. From this, SPA constructs lexicographically ordered preference pairs and fine-tunes the model using an uncertainty-weighted alignment loss that emphasizes high-confidence, high-gap decisions. Experiments across multiple benchmarks show that SPA improves helpfulness without compromising safety, outperforming strong baselines while preserving general capabilities. Our results demonstrate that SPA provides a scalable and interpretable alignment strategy for critical LLM applications.
Generative Models for Synthetic Data: Transforming Data Mining in the GenAI Era
Aug 27, 2025Generative models such as Large Language Models, Diffusion Models, and generative adversarial networks have recently revolutionized the creation of synthetic data, offering scalable solutions to data scarcity, privacy, and annotation challenges in data mining. This tutorial introduces the foundations and latest advances in synthetic data generation, covers key methodologies and practical frameworks, and discusses evaluation strategies and applications. Attendees will gain actionable insights into leveraging generative synthetic data to enhance data mining research and practice. More information can be found on our website: https://syndata4dm.github.io/.
TASE: Token Awareness and Structured Evaluation for Multilingual Language Models
Aug 07, 2025While large language models (LLMs) have demonstrated remarkable performance on high-level semantic tasks, they often struggle with fine-grained, token-level understanding and structural reasoning--capabilities that are essential for applications requiring precision and control. We introduce TASE, a comprehensive benchmark designed to evaluate LLMs' ability to perceive and reason about token-level information across languages. TASE covers 10 tasks under two core categories: token awareness and structural understanding, spanning Chinese, English, and Korean, with a 35,927-instance evaluation set and a scalable synthetic data generation pipeline for training. Tasks include character counting, token alignment, syntactic structure parsing, and length constraint satisfaction. We evaluate over 30 leading commercial and open-source LLMs, including O3, Claude 4, Gemini 2.5 Pro, and DeepSeek-R1, and train a custom Qwen2.5-14B model using the GRPO training method. Results show that human performance significantly outpaces current LLMs, revealing persistent weaknesses in token-level reasoning. TASE sheds light on these limitations and provides a new diagnostic lens for future improvements in low-level language understanding and cross-lingual generalization. Our code and dataset are publicly available at https://github.com/cyzcz/Tase .
AsFT: Anchoring Safety During LLM Fine-Tuning Within Narrow Safety Basin
Jun 11, 2025



Large language models (LLMs) are vulnerable to safety risks during fine-tuning, where small amounts of malicious or harmless data can compromise safeguards. In this paper, building on the concept of alignment direction -- defined by the weight difference between aligned and unaligned models -- we observe that perturbations along this direction preserve model safety. In contrast, perturbations along directions orthogonal to this alignment are strongly linked to harmful direction perturbations, rapidly degrading safety and framing the parameter space as a narrow safety basin. Based on this insight, we propose a methodology for safety fine-tuning called AsFT (Anchoring Safety in Fine-Tuning), which integrates a regularization term into the training objective. This term uses the alignment direction as an anchor to suppress updates in harmful directions, ensuring that fine-tuning is constrained within the narrow safety basin. Extensive experiments on multiple datasets show that AsFT outperforms Safe LoRA, reducing harmful behavior by 7.60 percent, improving model performance by 3.44 percent, and maintaining robust performance across various experimental settings. Code is available at https://github.com/PKU-YuanGroup/AsFT
Track Any Anomalous Object: A Granular Video Anomaly Detection Pipeline
Jun 05, 2025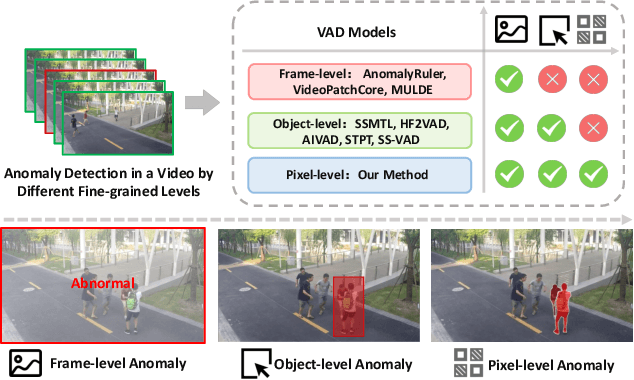
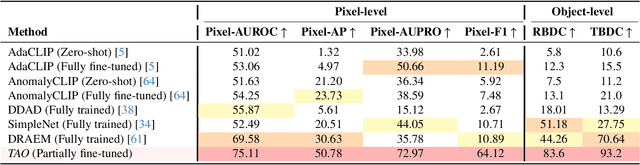
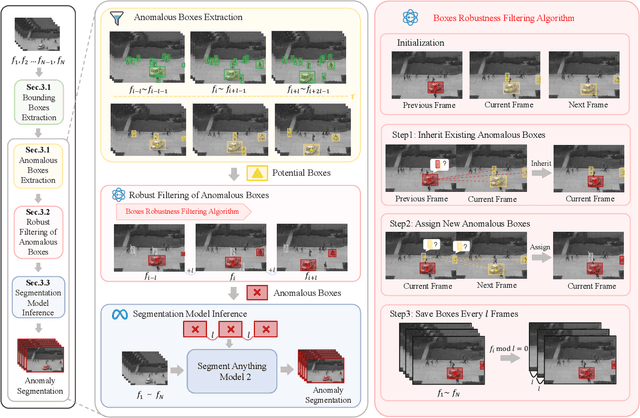
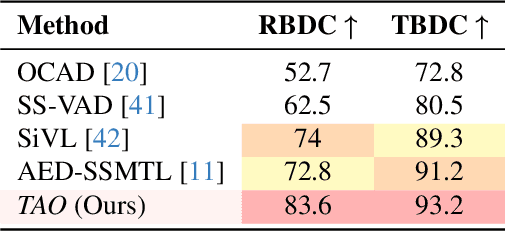
Video anomaly detection (VAD) is crucial in scenarios such as surveillance and autonomous driving, where timely detection of unexpected activities is essential. Although existing methods have primarily focused on detecting anomalous objects in videos -- either by identifying anomalous frames or objects -- they often neglect finer-grained analysis, such as anomalous pixels, which limits their ability to capture a broader range of anomalies. To address this challenge, we propose a new framework called Track Any Anomalous Object (TAO), which introduces a granular video anomaly detection pipeline that, for the first time, integrates the detection of multiple fine-grained anomalous objects into a unified framework. Unlike methods that assign anomaly scores to every pixel, our approach transforms the problem into pixel-level tracking of anomalous objects. By linking anomaly scores to downstream tasks such as segmentation and tracking, our method removes the need for threshold tuning and achieves more precise anomaly localization in long and complex video sequences. Experiments demonstrate that TAO sets new benchmarks in accuracy and robustness. Project page available online.
Dissecting Logical Reasoning in LLMs: A Fine-Grained Evaluation and Supervision Study
Jun 05, 2025Logical reasoning is a core capability for many applications of large language models (LLMs), yet existing benchmarks often rely solely on final-answer accuracy, failing to capture the quality and structure of the reasoning process. We propose FineLogic, a fine-grained evaluation framework that assesses logical reasoning across three dimensions: overall benchmark accuracy, stepwise soundness, and representation-level alignment. In addition, to better understand how reasoning capabilities emerge, we conduct a comprehensive study on the effects of supervision format during fine-tuning. We construct four supervision styles (one natural language and three symbolic variants) and train LLMs under each. Our findings reveal that natural language supervision yields strong generalization even on out-of-distribution and long-context tasks, while symbolic reasoning styles promote more structurally sound and atomic inference chains. Further, our representation-level probing shows that fine-tuning primarily improves reasoning behaviors through step-by-step generation, rather than enhancing shortcut prediction or internalized correctness. Together, our framework and analysis provide a more rigorous and interpretable lens for evaluating and improving logical reasoning in LLMs.
SocialMaze: A Benchmark for Evaluating Social Reasoning in Large Language Models
May 29, 2025



Large language models (LLMs) are increasingly applied to socially grounded tasks, such as online community moderation, media content analysis, and social reasoning games. Success in these contexts depends on a model's social reasoning ability - the capacity to interpret social contexts, infer others' mental states, and assess the truthfulness of presented information. However, there is currently no systematic evaluation framework that comprehensively assesses the social reasoning capabilities of LLMs. Existing efforts often oversimplify real-world scenarios and consist of tasks that are too basic to challenge advanced models. To address this gap, we introduce SocialMaze, a new benchmark specifically designed to evaluate social reasoning. SocialMaze systematically incorporates three core challenges: deep reasoning, dynamic interaction, and information uncertainty. It provides six diverse tasks across three key settings: social reasoning games, daily-life interactions, and digital community platforms. Both automated and human validation are used to ensure data quality. Our evaluation reveals several key insights: models vary substantially in their ability to handle dynamic interactions and integrate temporally evolving information; models with strong chain-of-thought reasoning perform better on tasks requiring deeper inference beyond surface-level cues; and model reasoning degrades significantly under uncertainty. Furthermore, we show that targeted fine-tuning on curated reasoning examples can greatly improve model performance in complex social scenarios. The dataset is publicly available at: https://huggingface.co/datasets/MBZUAI/SocialMaze