 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFine-Grained Scene Graph Generation with Data Transfer
Mar 22, 2022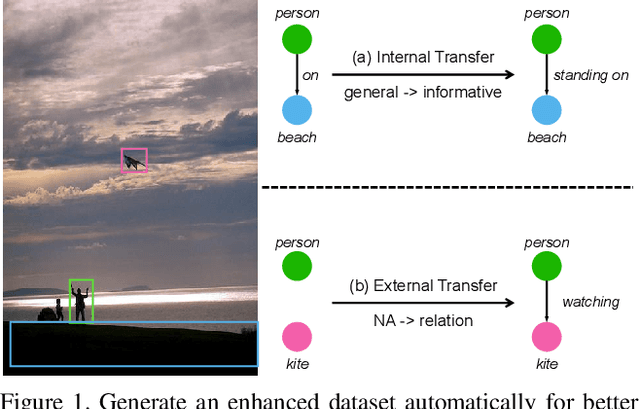
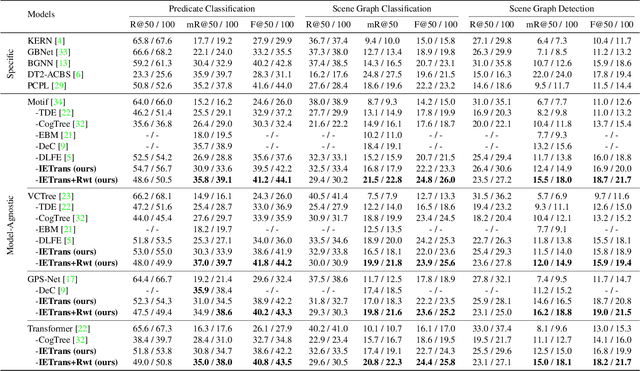
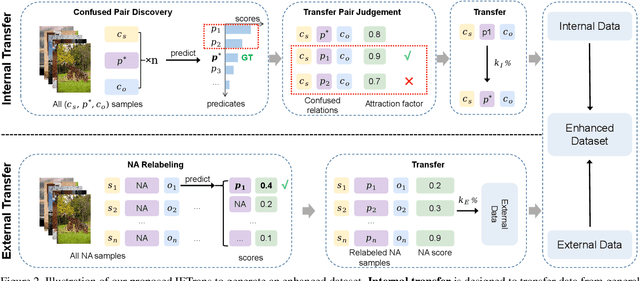
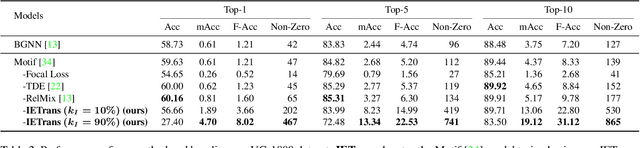
Scene graph generation (SGG) aims to extract (subject, predicate, object) triplets in images. Recent works have made a steady progress on SGG, and provide useful tools for high-level vision and language understanding. However, due to the data distribution problems including long-tail distribution and semantic ambiguity, the predictions of current SGG models tend to collapse to several frequent but uninformative predicates (e.g., \textit{on}, \textit{at}), which limits practical application of these models in downstream tasks. To deal with the problems above, we propose a novel Internal and External Data Transfer (IETrans) method, which can be applied in a play-and-plug fashion and expanded to large SGG with 1,807 predicate classes. Our IETrans tries to relieve the data distribution problem by automatically creating an enhanced dataset that provides more sufficient and coherent annotations for all predicates. By training on the transferred dataset, a Neural Motif model doubles the macro performance while maintaining competitive micro performance. The data and code for this paper are publicly available at \url{https://github.com/waxnkw/IETrans-SGG.pytorch}
Structure-Aware Flow Generation for Human Body Reshaping
Mar 11, 2022
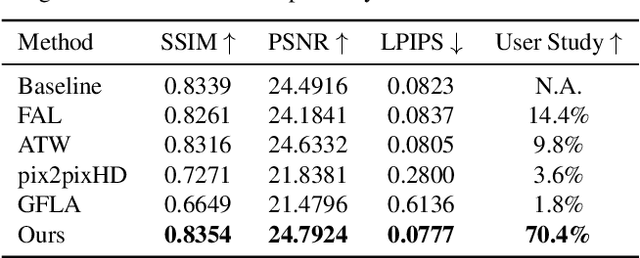
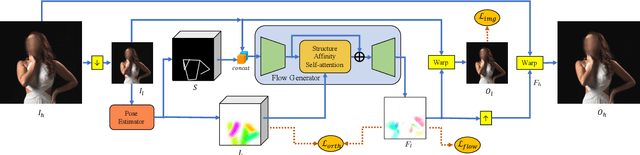
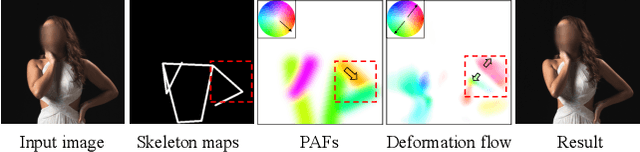
Body reshaping is an important procedure in portrait photo retouching. Due to the complicated structure and multifarious appearance of human bodies, existing methods either fall back on the 3D domain via body morphable model or resort to keypoint-based image deformation, leading to inefficiency and unsatisfied visual quality. In this paper, we address these limitations by formulating an end-to-end flow generation architecture under the guidance of body structural priors, including skeletons and Part Affinity Fields, and achieve unprecedentedly controllable performance under arbitrary poses and garments. A compositional attention mechanism is introduced for capturing both visual perceptual correlations and structural associations of the human body to reinforce the manipulation consistency among related parts. For a comprehensive evaluation, we construct the first large-scale body reshaping dataset, namely BR-5K, which contains 5,000 portrait photos as well as professionally retouched targets. Extensive experiments demonstrate that our approach significantly outperforms existing state-of-the-art methods in terms of visual performance, controllability, and efficiency. The dataset is available at our website: https://github.com/JianqiangRen/FlowBasedBodyReshaping.
Optimizing Random Mixup with Gaussian Differential Privacy
Feb 14, 2022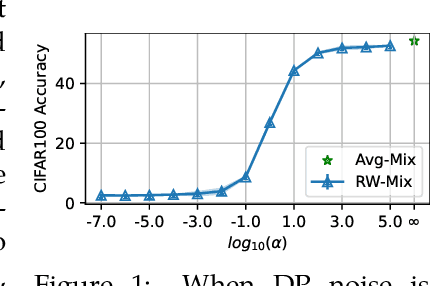



Differentially private data release receives rising attention in machine learning community. Recently, an algorithm called DPMix is proposed to release high-dimensional data after a random mixup of degree $m$ with differential privacy. However, limited theoretical justifications are given about the "sweet spot $m$" phenomenon, and directly applying DPMix to image data suffers from severe loss of utility. In this paper, we revisit random mixup with recent progress on differential privacy. In theory, equipped with Gaussian Differential Privacy with Poisson subsampling, a tight closed form analysis is presented that enables a quantitative characterization of optimal mixup $m^*$ based on linear regression models. In practice, mixup of features, extracted by handcraft or pre-trained neural networks such as self-supervised learning without labels, is adopted to significantly boost the performance with privacy protection. We name it as Differentially Private Feature Mixup (DPFMix). Experiments on MNIST, CIFAR10/100 are conducted to demonstrate its remarkable utility improvement and protection against attacks.
CUGE: A Chinese Language Understanding and Generation Evaluation Benchmark
Dec 27, 2021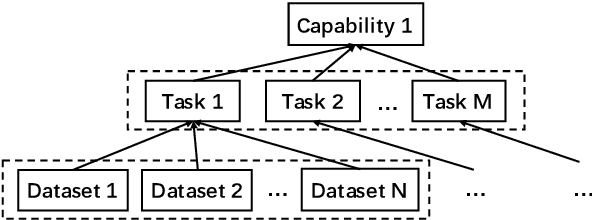
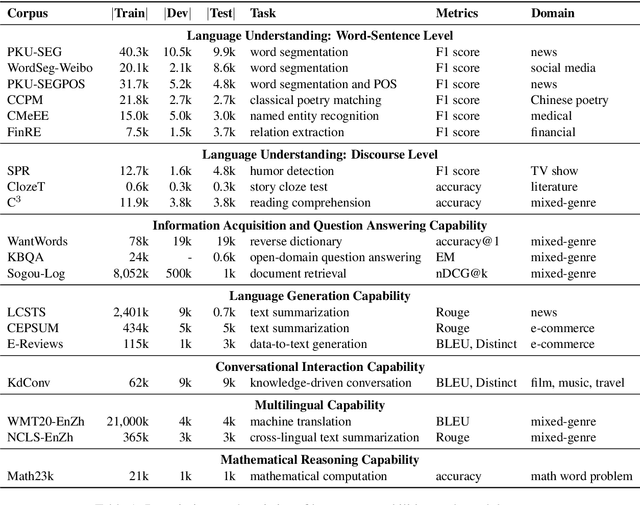

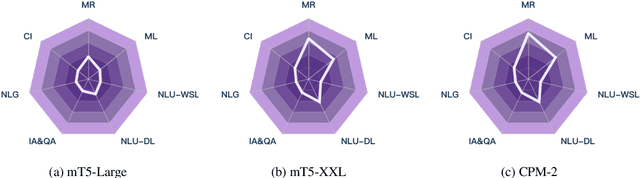
Realizing general-purpose language intelligence has been a longstanding goal for natural language processing, where standard evaluation benchmarks play a fundamental and guiding role. We argue that for general-purpose language intelligence evaluation, the benchmark itself needs to be comprehensive and systematic. To this end, we propose CUGE, a Chinese Language Understanding and Generation Evaluation benchmark with the following features: (1) Hierarchical benchmark framework, where datasets are principally selected and organized with a language capability-task-dataset hierarchy. (2) Multi-level scoring strategy, where different levels of model performance are provided based on the hierarchical framework. To facilitate CUGE, we provide a public leaderboard that can be customized to support flexible model judging criteria. Evaluation results on representative pre-trained language models indicate ample room for improvement towards general-purpose language intelligence. CUGE is publicly available at cuge.baai.ac.cn.
Generalization Bounds for Stochastic Gradient Langevin Dynamics: A Unified View via Information Leakage Analysis
Dec 14, 2021

Recently, generalization bounds of the non-convex empirical risk minimization paradigm using Stochastic Gradient Langevin Dynamics (SGLD) have been extensively studied. Several theoretical frameworks have been presented to study this problem from different perspectives, such as information theory and stability. In this paper, we present a unified view from privacy leakage analysis to investigate the generalization bounds of SGLD, along with a theoretical framework for re-deriving previous results in a succinct manner. Aside from theoretical findings, we conduct various numerical studies to empirically assess the information leakage issue of SGLD. Additionally, our theoretical and empirical results provide explanations for prior works that study the membership privacy of SGLD.
Backdoor Attack through Frequency Domain
Nov 30, 2021


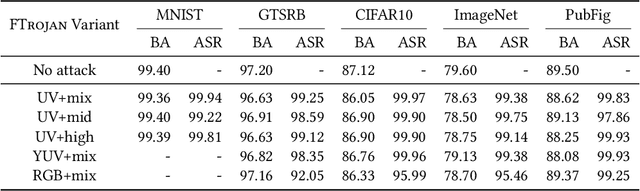
Backdoor attacks have been shown to be a serious threat against deep learning systems such as biometric authentication and autonomous driving. An effective backdoor attack could enforce the model misbehave under certain predefined conditions, i.e., triggers, but behave normally otherwise. However, the triggers of existing attacks are directly injected in the pixel space, which tend to be detectable by existing defenses and visually identifiable at both training and inference stages. In this paper, we propose a new backdoor attack FTROJAN through trojaning the frequency domain. The key intuition is that triggering perturbations in the frequency domain correspond to small pixel-wise perturbations dispersed across the entire image, breaking the underlying assumptions of existing defenses and making the poisoning images visually indistinguishable from clean ones. We evaluate FTROJAN in several datasets and tasks showing that it achieves a high attack success rate without significantly degrading the prediction accuracy on benign inputs. Moreover, the poisoning images are nearly invisible and retain high perceptual quality. We also evaluate FTROJAN against state-of-the-art defenses as well as several adaptive defenses that are designed on the frequency domain. The results show that FTROJAN can robustly elude or significantly degenerate the performance of these defenses.
CPT: Colorful Prompt Tuning for Pre-trained Vision-Language Models
Oct 08, 2021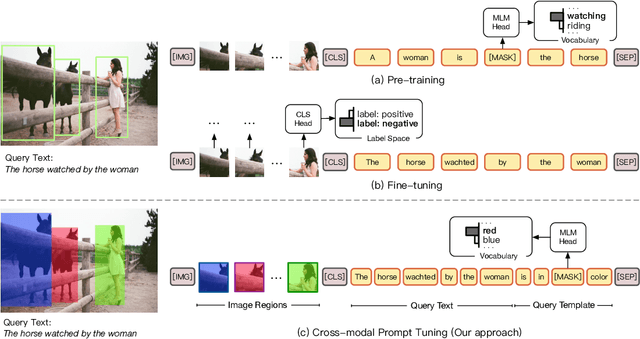
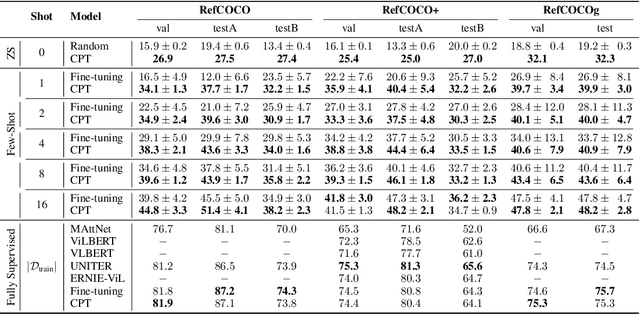
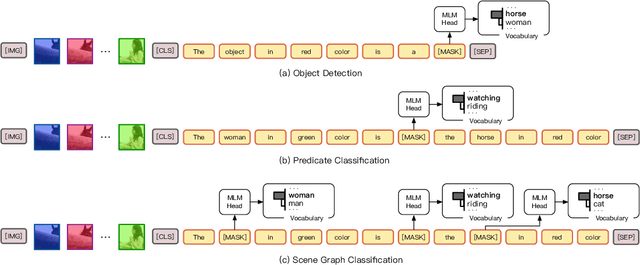
Pre-Trained Vision-Language Models (VL-PTMs) have shown promising capabilities in grounding natural language in image data, facilitating a broad variety of cross-modal tasks. However, we note that there exists a significant gap between the objective forms of model pre-training and fine-tuning, resulting in a need for large amounts of labeled data to stimulate the visual grounding capability of VL-PTMs for downstream tasks. To address the challenge, we present Cross-modal Prompt Tuning (CPT, alternatively, Colorful Prompt Tuning), a novel paradigm for tuning VL-PTMs, which reformulates visual grounding into a fill-in-the-blank problem with color-based co-referential markers in image and text, maximally mitigating the gap. In this way, CPT enables strong few-shot and even zero-shot visual grounding capabilities of VL-PTMs. Comprehensive experimental results show that the prompt-tuned VL-PTMs outperform their fine-tuned counterparts by a large margin (e.g., 17.3% absolute accuracy improvement, and 73.8% relative standard deviation reduction on average with one shot in RefCOCO evaluation). All the data and codes will be available to facilitate future research.
Federated Deep Learning with Bayesian Privacy
Sep 27, 2021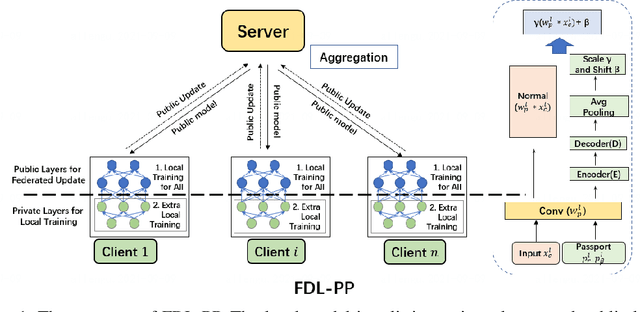
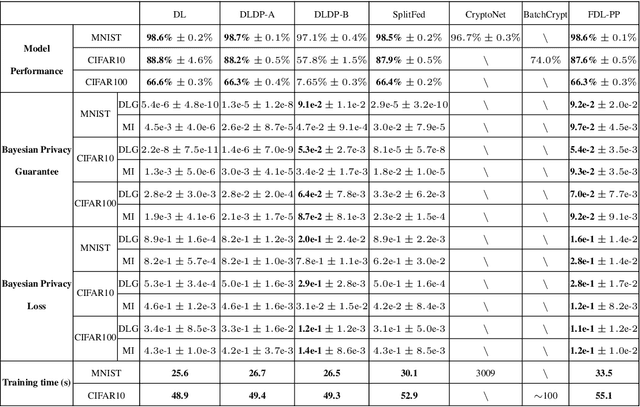
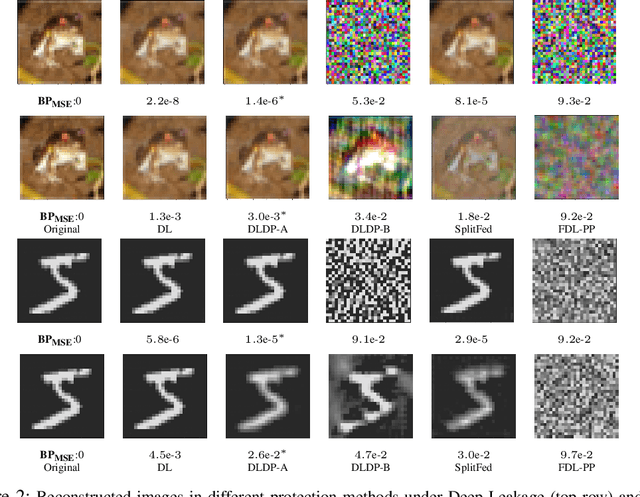
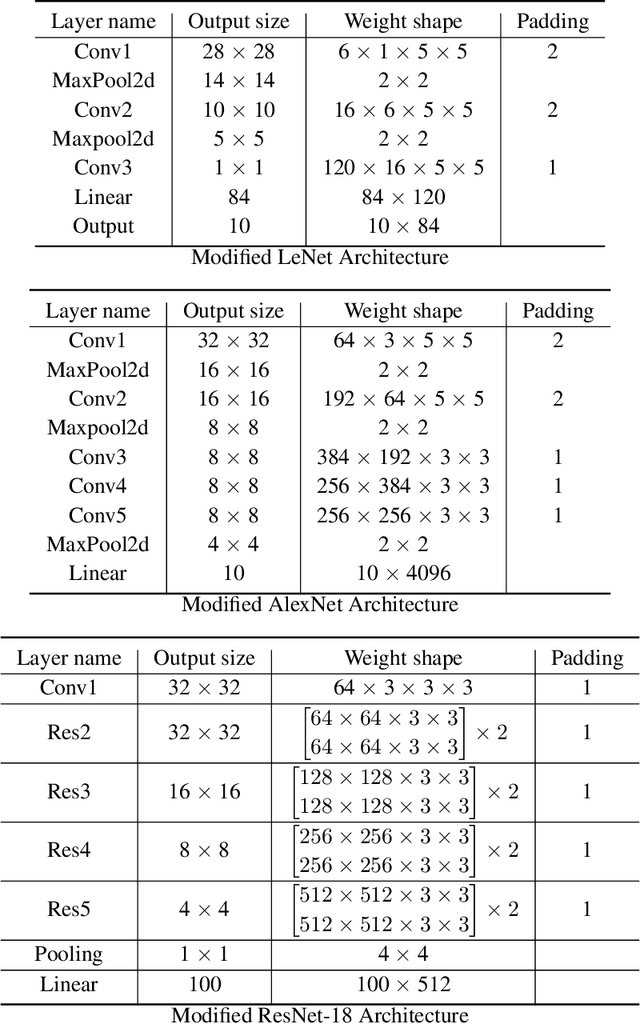
Federated learning (FL) aims to protect data privacy by cooperatively learning a model without sharing private data among users. For Federated Learning of Deep Neural Network with billions of model parameters, existing privacy-preserving solutions are unsatisfactory. Homomorphic encryption (HE) based methods provide secure privacy protections but suffer from extremely high computational and communication overheads rendering it almost useless in practice . Deep learning with Differential Privacy (DP) was implemented as a practical learning algorithm at a manageable cost in complexity. However, DP is vulnerable to aggressive Bayesian restoration attacks as disclosed in the literature and demonstrated in experimental results of this work. To address the aforementioned perplexity, we propose a novel Bayesian Privacy (BP) framework which enables Bayesian restoration attacks to be formulated as the probability of reconstructing private data from observed public information. Specifically, the proposed BP framework accurately quantifies privacy loss by Kullback-Leibler (KL) Divergence between the prior distribution about the privacy data and the posterior distribution of restoration private data conditioning on exposed information}. To our best knowledge, this Bayesian Privacy analysis is the first to provides theoretical justification of secure privacy-preserving capabilities against Bayesian restoration attacks. As a concrete use case, we demonstrate that a novel federated deep learning method using private passport layers is able to simultaneously achieve high model performance, privacy-preserving capability and low computational complexity. Theoretical analysis is in accordance with empirical measurements of information leakage extensively experimented with a variety of DNN networks on image classification MNIST, CIFAR10, and CIFAR100 datasets.
A Note on Learning Rare Events in Molecular Dynamics using LSTM and Transformer
Jul 14, 2021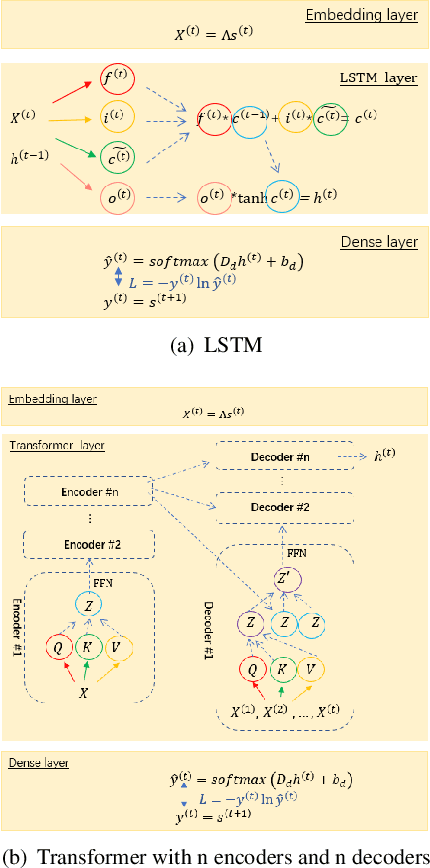
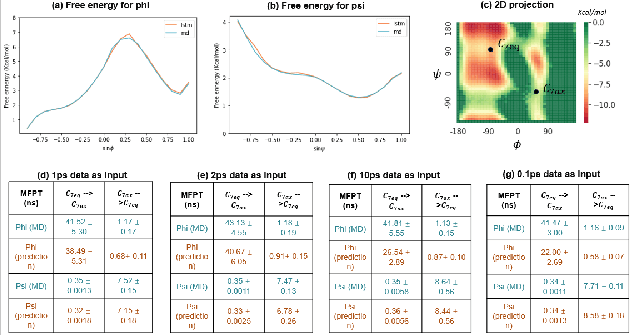
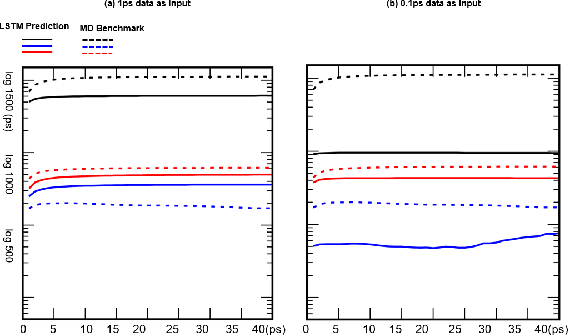
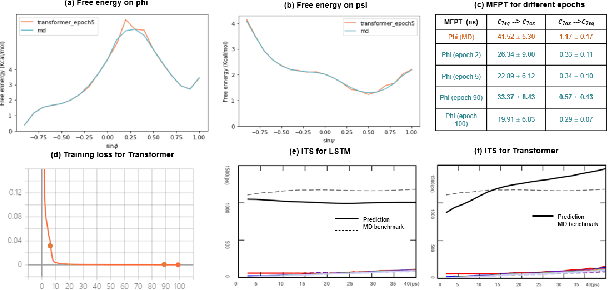
Recurrent neural networks for language models like long short-term memory (LSTM) have been utilized as a tool for modeling and predicting long term dynamics of complex stochastic molecular systems. Recently successful examples on learning slow dynamics by LSTM are given with simulation data of low dimensional reaction coordinate. However, in this report we show that the following three key factors significantly affect the performance of language model learning, namely dimensionality of reaction coordinates, temporal resolution and state partition. When applying recurrent neural networks to molecular dynamics simulation trajectories of high dimensionality, we find that rare events corresponding to the slow dynamics might be obscured by other faster dynamics of the system, and cannot be efficiently learned. Under such conditions, we find that coarse graining the conformational space into metastable states and removing recrossing events when estimating transition probabilities between states could greatly help improve the accuracy of slow dynamics learning in molecular dynamics. Moreover, we also explore other models like Transformer, which do not show superior performance than LSTM in overcoming these issues. Therefore, to learn rare events of slow molecular dynamics by LSTM and Transformer, it is critical to choose proper temporal resolution (i.e., saving intervals of MD simulation trajectories) and state partition in high resolution data, since deep neural network models might not automatically disentangle slow dynamics from fast dynamics when both are present in data influencing each other.
CPM-2: Large-scale Cost-effective Pre-trained Language Models
Jun 24, 2021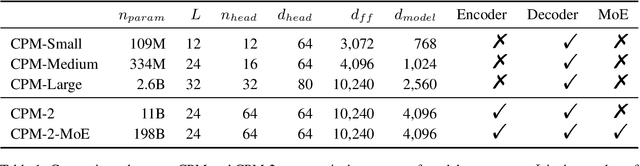
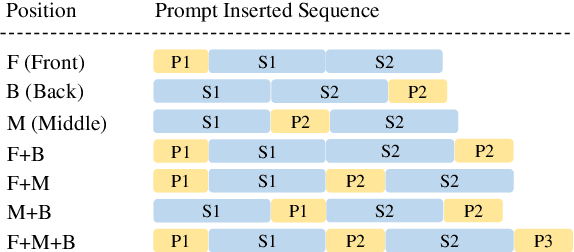

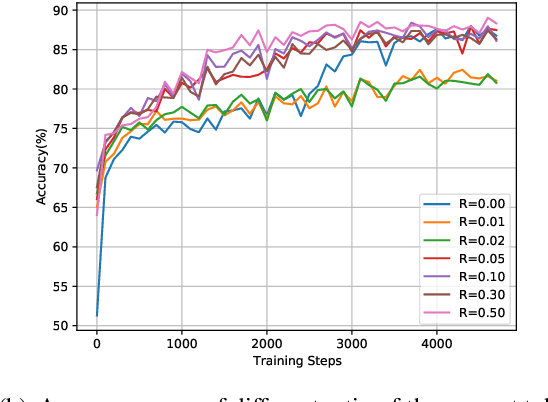
In recent years, the size of pre-trained language models (PLMs) has grown by leaps and bounds. However, efficiency issues of these large-scale PLMs limit their utilization in real-world scenarios. We present a suite of cost-effective techniques for the use of PLMs to deal with the efficiency issues of pre-training, fine-tuning, and inference. (1) We introduce knowledge inheritance to accelerate the pre-training process by exploiting existing PLMs instead of training models from scratch. (2) We explore the best practice of prompt tuning with large-scale PLMs. Compared with conventional fine-tuning, prompt tuning significantly reduces the number of task-specific parameters. (3) We implement a new inference toolkit, namely InfMoE, for using large-scale PLMs with limited computational resources. Based on our cost-effective pipeline, we pre-train two models: an encoder-decoder bilingual model with 11 billion parameters (CPM-2) and its corresponding MoE version with 198 billion parameters. In our experiments, we compare CPM-2 with mT5 on downstream tasks. Experimental results show that CPM-2 has excellent general language intelligence. Moreover, we validate the efficiency of InfMoE when conducting inference of large-scale models having tens of billions of parameters on a single GPU. All source code and model parameters are available at https://github.com/TsinghuaAI/CPM.