 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGroup Collaborative Learning for Co-Salient Object Detection
Mar 15, 2021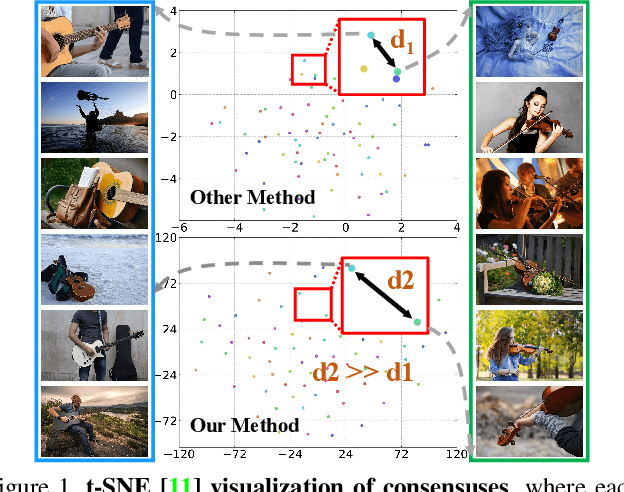

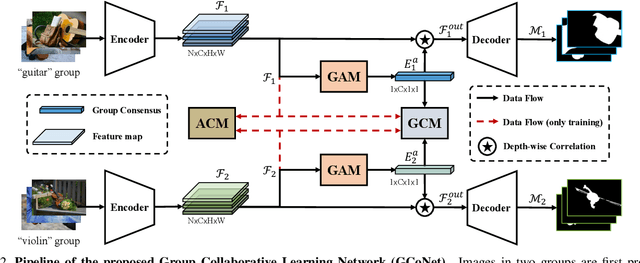
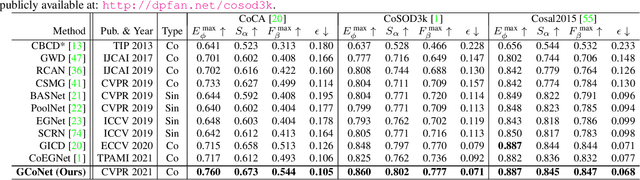
We present a novel group collaborative learning framework (GCoNet) capable of detecting co-salient objects in real time (16ms), by simultaneously mining consensus representations at group level based on the two necessary criteria: 1) intra-group compactness to better formulate the consistency among co-salient objects by capturing their inherent shared attributes using our novel group affinity module; 2) inter-group separability to effectively suppress the influence of noisy objects on the output by introducing our new group collaborating module conditioning the inconsistent consensus. To learn a better embedding space without extra computational overhead, we explicitly employ auxiliary classification supervision. Extensive experiments on three challenging benchmarks, i.e., CoCA, CoSOD3k, and Cosal2015, demonstrate that our simple GCoNet outperforms 10 cutting-edge models and achieves the new state-of-the-art. We demonstrate this paper's new technical contributions on a number of important downstream computer vision applications including content aware co-segmentation, co-localization based automatic thumbnails, etc.
PRIN/SPRIN: On Extracting Point-wise Rotation Invariant Features
Feb 24, 2021
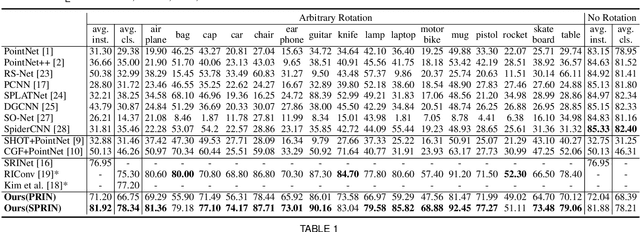

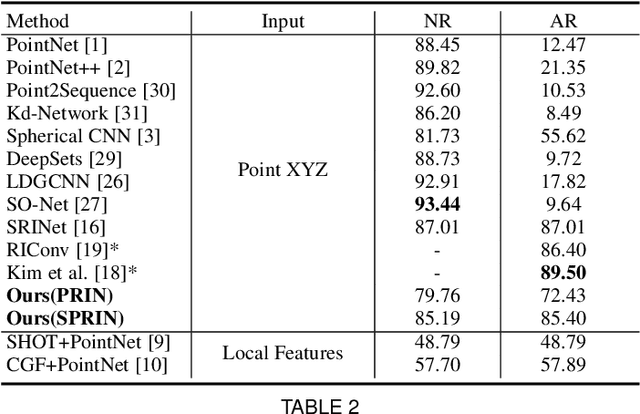
Point cloud analysis without pose priors is very challenging in real applications, as the orientations of point clouds are often unknown. In this paper, we propose a brand new point-set learning framework PRIN, namely, Point-wise Rotation Invariant Network, focusing on rotation invariant feature extraction in point clouds analysis. We construct spherical signals by Density Aware Adaptive Sampling to deal with distorted point distributions in spherical space. Spherical Voxel Convolution and Point Re-sampling are proposed to extract rotation invariant features for each point. In addition, we extend PRIN to a sparse version called SPRIN, which directly operates on sparse point clouds. Both PRIN and SPRIN can be applied to tasks ranging from object classification, part segmentation, to 3D feature matching and label alignment. Results show that, on the dataset with randomly rotated point clouds, SPRIN demonstrates better performance than state-of-the-art methods without any data augmentation. We also provide thorough theoretical proof and analysis for point-wise rotation invariance achieved by our methods. Our code is available on https://github.com/qq456cvb/SPRIN.
Semi-Supervised Few-Shot Atomic Action Recognition
Nov 17, 2020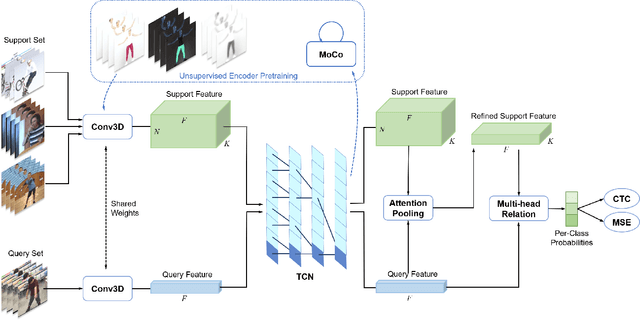
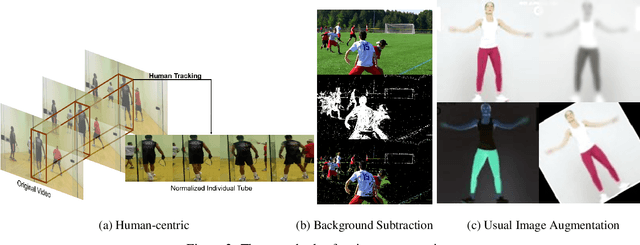
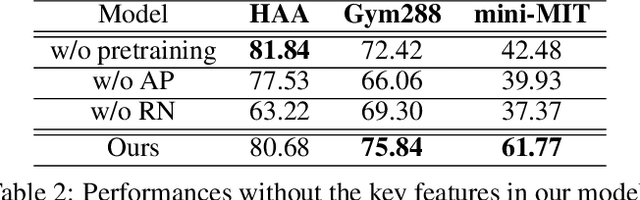
Despite excellent progress has been made, the performance on action recognition still heavily relies on specific datasets, which are difficult to extend new action classes due to labor-intensive labeling. Moreover, the high diversity in Spatio-temporal appearance requires robust and representative action feature aggregation and attention. To address the above issues, we focus on atomic actions and propose a novel model for semi-supervised few-shot atomic action recognition. Our model features unsupervised and contrastive video embedding, loose action alignment, multi-head feature comparison, and attention-based aggregation, together of which enables action recognition with only a few training examples through extracting more representative features and allowing flexibility in spatial and temporal alignment and variations in the action. Experiments show that our model can attain high accuracy on representative atomic action datasets outperforming their respective state-of-the-art classification accuracy in full supervision setting.
HAA500: Human-Centric Atomic Action Dataset with Curated Videos
Sep 11, 2020
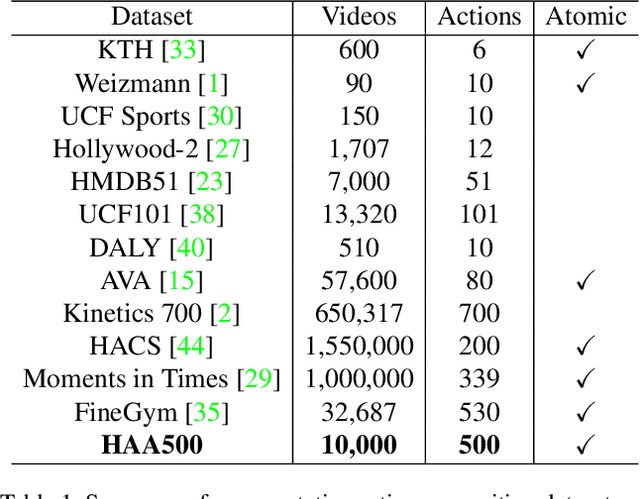
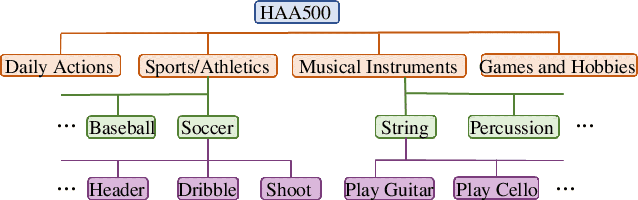
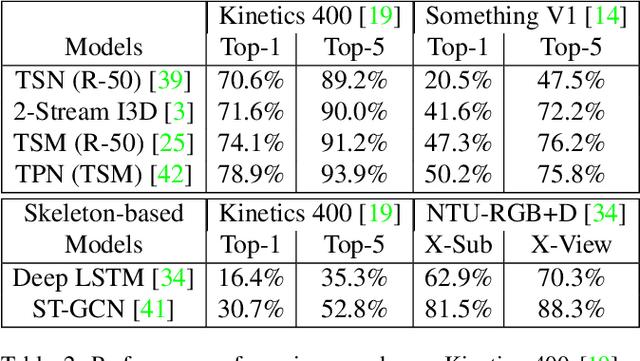
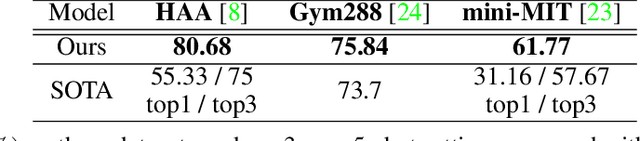
We contribute HAA500, a manually annotated human-centric atomic action dataset for action recognition on 500 classes with over 591k labeled frames. Unlike existing atomic action datasets, where coarse-grained atomic actions were labeled with action-verbs, e.g., "Throw", HAA500 contains fine-grained atomic actions where only consistent actions fall under the same label, e.g., "Baseball Pitching" vs "Free Throw in Basketball", to minimize ambiguities in action classification. HAA500 has been carefully curated to capture the movement of human figures with less spatio-temporal label noises to greatly enhance the training of deep neural networks. The advantages of HAA500 include: 1) human-centric actions with a high average of 69.7% detectable joints for the relevant human poses; 2) each video captures the essential elements of an atomic action without irrelevant frames; 3) fine-grained atomic action classes. Our extensive experiments validate the benefits of human-centric and atomic characteristics of HAA, which enables the trained model to improve prediction by attending to atomic human poses. We detail the HAA500 dataset statistics and collection methodology, and compare quantitatively with existing action recognition datasets.
Pose-Guided High-Resolution Appearance Transfer via Progressive Training
Aug 27, 2020
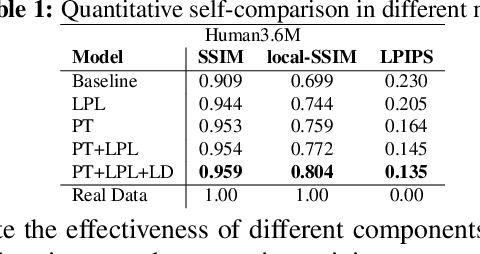
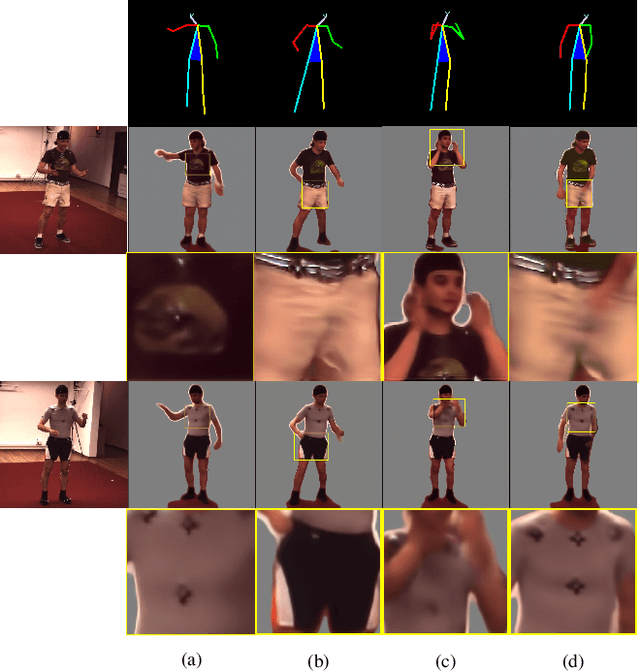
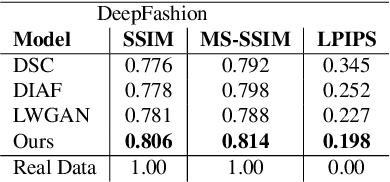
We propose a novel pose-guided appearance transfer network for transferring a given reference appearance to a target pose in unprecedented image resolution (1024 * 1024), given respectively an image of the reference and target person. No 3D model is used. Instead, our network utilizes dense local descriptors including local perceptual loss and local discriminators to refine details, which is trained progressively in a coarse-to-fine manner to produce the high-resolution output to faithfully preserve complex appearance of garment textures and geometry, while hallucinating seamlessly the transferred appearances including those with dis-occlusion. Our progressive encoder-decoder architecture can learn the reference appearance inherent in the input image at multiple scales. Extensive experimental results on the Human3.6M dataset, the DeepFashion dataset, and our dataset collected from YouTube show that our model produces high-quality images, which can be further utilized in useful applications such as garment transfer between people and pose-guided human video generation.
GSNet: Joint Vehicle Pose and Shape Reconstruction with Geometrical and Scene-aware Supervision
Jul 26, 2020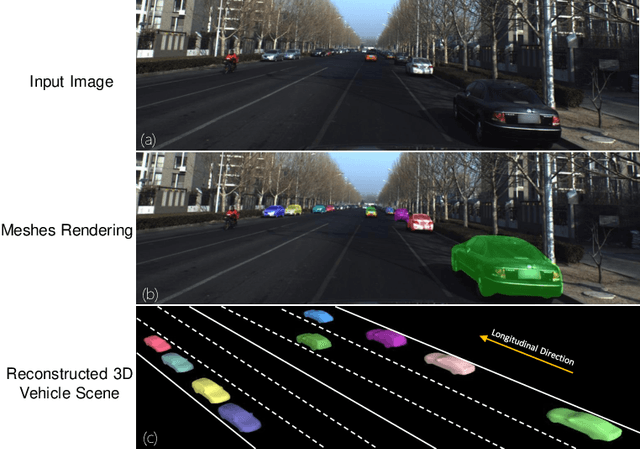

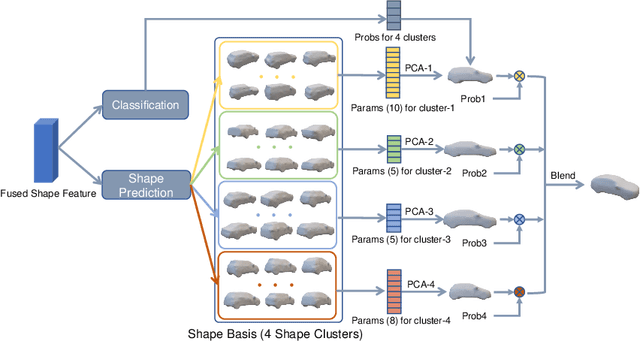

We present a novel end-to-end framework named as GSNet (Geometric and Scene-aware Network), which jointly estimates 6DoF poses and reconstructs detailed 3D car shapes from single urban street view. GSNet utilizes a unique four-way feature extraction and fusion scheme and directly regresses 6DoF poses and shapes in a single forward pass. Extensive experiments show that our diverse feature extraction and fusion scheme can greatly improve model performance. Based on a divide-and-conquer 3D shape representation strategy, GSNet reconstructs 3D vehicle shape with great detail (1352 vertices and 2700 faces). This dense mesh representation further leads us to consider geometrical consistency and scene context, and inspires a new multi-objective loss function to regularize network training, which in turn improves the accuracy of 6D pose estimation and validates the merit of jointly performing both tasks. We evaluate GSNet on the largest multi-task ApolloCar3D benchmark and achieve state-of-the-art performance both quantitatively and qualitatively. Project page is available at https://lkeab.github.io/gsnet/.
Fully Convolutional Networks for Continuous Sign Language Recognition
Jul 24, 2020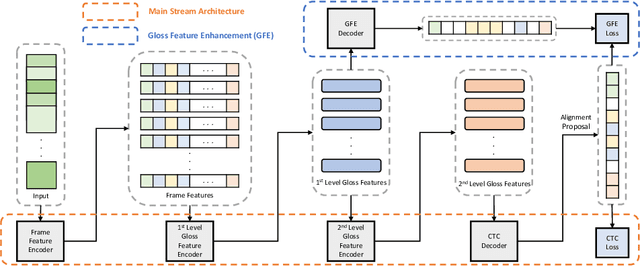
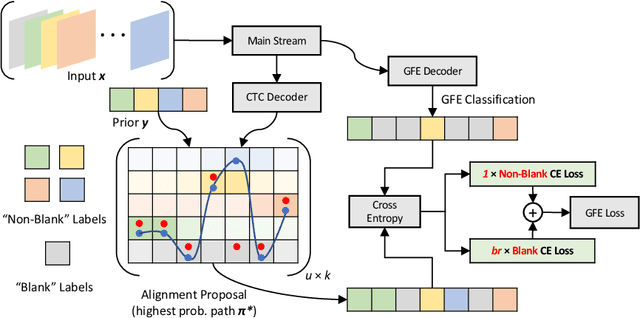
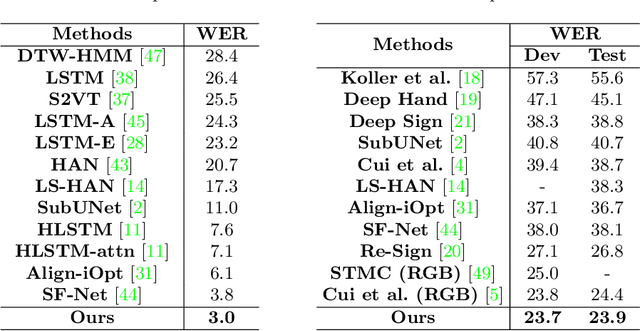
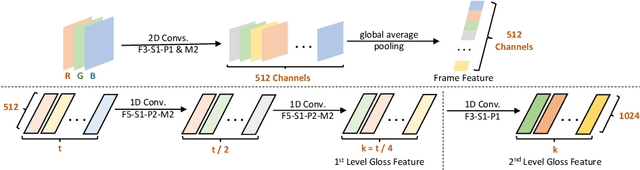
Continuous sign language recognition (SLR) is a challenging task that requires learning on both spatial and temporal dimensions of signing frame sequences. Most recent work accomplishes this by using CNN and RNN hybrid networks. However, training these networks is generally non-trivial, and most of them fail in learning unseen sequence patterns, causing an unsatisfactory performance for online recognition. In this paper, we propose a fully convolutional network (FCN) for online SLR to concurrently learn spatial and temporal features from weakly annotated video sequences with only sentence-level annotations given. A gloss feature enhancement (GFE) module is introduced in the proposed network to enforce better sequence alignment learning. The proposed network is end-to-end trainable without any pre-training. We conduct experiments on two large scale SLR datasets. Experiments show that our method for continuous SLR is effective and performs well in online recognition.
Commonality-Parsing Network across Shape and Appearance for Partially Supervised Instance Segmentation
Jul 24, 2020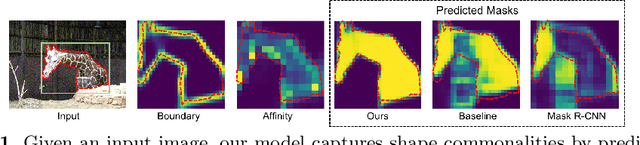
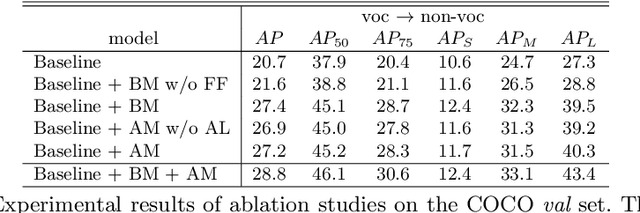
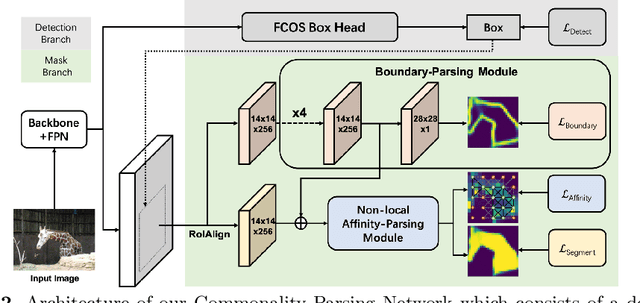
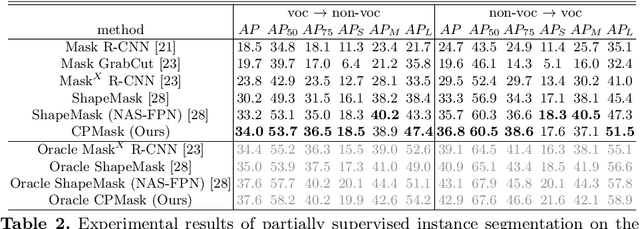
Partially supervised instance segmentation aims to perform learning on limited mask-annotated categories of data thus eliminating expensive and exhaustive mask annotation. The learned models are expected to be generalizable to novel categories. Existing methods either learn a transfer function from detection to segmentation, or cluster shape priors for segmenting novel categories. We propose to learn the underlying class-agnostic commonalities that can be generalized from mask-annotated categories to novel categories. Specifically, we parse two types of commonalities: 1) shape commonalities which are learned by performing supervised learning on instance boundary prediction; and 2) appearance commonalities which are captured by modeling pairwise affinities among pixels of feature maps to optimize the separability between instance and the background. Incorporating both the shape and appearance commonalities, our model significantly outperforms the state-of-the-art methods on both partially supervised setting and few-shot setting for instance segmentation on COCO dataset.
Dense Hybrid Recurrent Multi-view Stereo Net with Dynamic Consistency Checking
Jul 21, 2020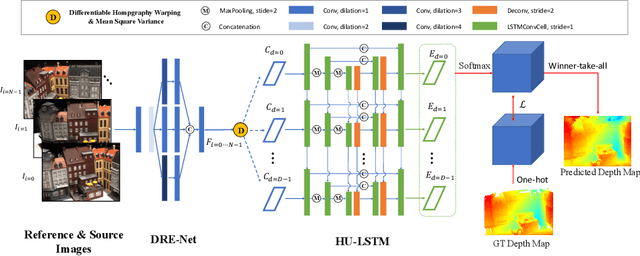
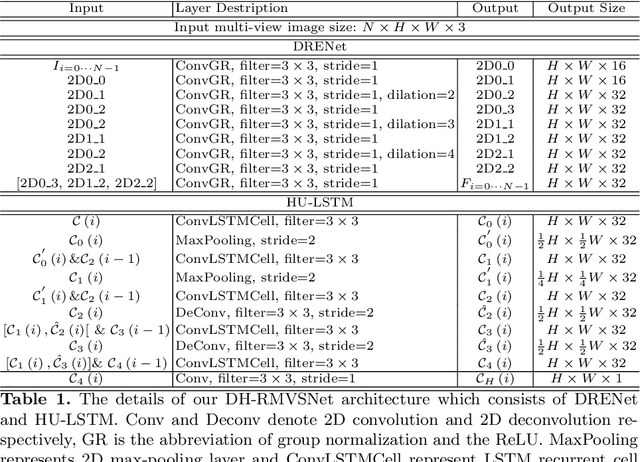
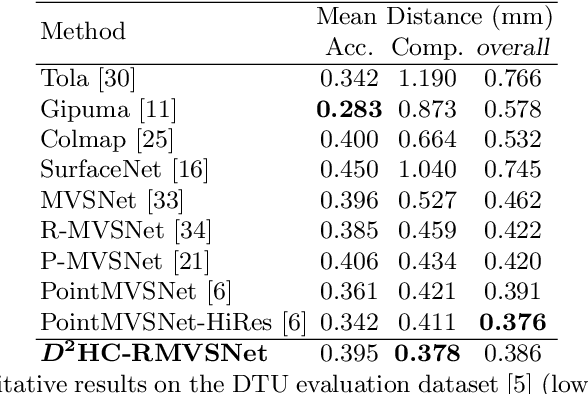

In this paper, we propose an efficient and effective dense hybrid recurrent multi-view stereo net with dynamic consistency checking, namely $D^{2}$HC-RMVSNet, for accurate dense point cloud reconstruction. Our novel hybrid recurrent multi-view stereo net consists of two core modules: 1) a light DRENet (Dense Reception Expanded) module to extract dense feature maps of original size with multi-scale context information, 2) a HU-LSTM (Hybrid U-LSTM) to regularize 3D matching volume into predicted depth map, which efficiently aggregates different scale information by coupling LSTM and U-Net architecture. To further improve the accuracy and completeness of reconstructed point clouds, we leverage a dynamic consistency checking strategy instead of prefixed parameters and strategies widely adopted in existing methods for dense point cloud reconstruction. In doing so, we dynamically aggregate geometric consistency matching error among all the views. Our method ranks \textbf{$1^{st}$} on the complex outdoor \textsl{Tanks and Temples} benchmark over all the methods. Extensive experiments on the in-door DTU dataset show our method exhibits competitive performance to the state-of-the-art method while dramatically reduces memory consumption, which costs only $19.4\%$ of R-MVSNet memory consumption. The codebase is available at \hyperlink{https://github.com/yhw-yhw/D2HC-RMVSNet}{https://github.com/yhw-yhw/D2HC-RMVSNet}.
* Accepted by ECCV2020 as Spotlight
Dive Deeper Into Box for Object Detection
Jul 15, 2020
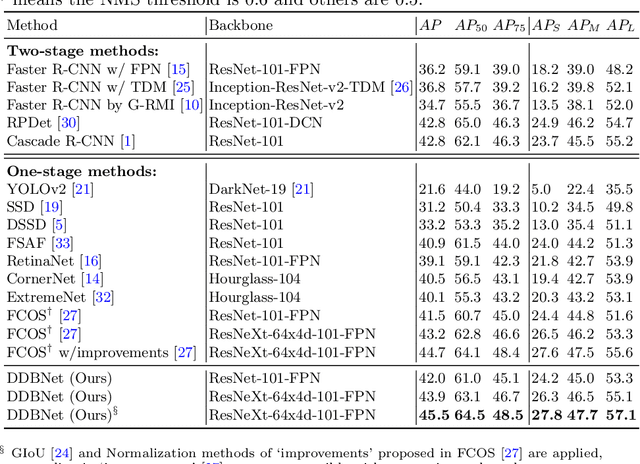

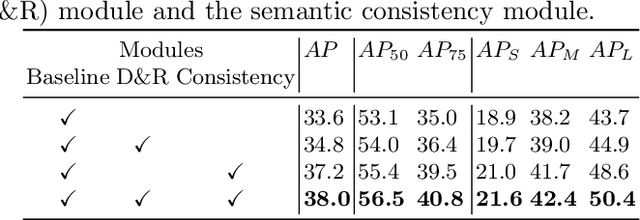
Anchor free methods have defined the new frontier in state-of-the-art object detection researches where accurate bounding box estimation is the key to the success of these methods. However, even the bounding box has the highest confidence score, it is still far from perfect at localization. To this end, we propose a box reorganization method(DDBNet), which can dive deeper into the box for more accurate localization. At the first step, drifted boxes are filtered out because the contents in these boxes are inconsistent with target semantics. Next, the selected boxes are broken into boundaries, and the well-aligned boundaries are searched and grouped into a sort of optimal boxes toward tightening instances more precisely. Experimental results show that our method is effective which leads to state-of-the-art performance for object detection.