 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWhich Way Did It Move? Diagnosing and Overcoming Directional Motion Blindness in Video-LLMs
May 21, 2026Video Large Language Models (Video-LLMs) have made rapid progress on temporal video understanding, yet many fail at a basic perceptual primitive: signed image-plane motion direction. On simple videos of a single object moving left, right, up, or down, most Video-LLMs perform near chance, with above-chance cases largely attributable to prediction biases rather than genuine direction understanding. We call this failure directional motion blindness. We localize the failure by tracing motion direction information through the Video-LLM pipeline. Motion direction remains linearly accessible from the vision encoder, projector, and LLM hidden states, but the readout fails to bind this signal to the correct verbal answer option, revealing a direction binding gap. Although synthetic motion direction instruction tuning reduces this gap on the source domain, motion direction concept vector analysis shows that visual complexity weakens the signal magnitude and limits out-of-domain generalization. We introduce MoDirect, a dataset family for motion direction instruction tuning and evaluation, and DeltaDirect, a diagnosis-driven, projector-level objective that predicts normalized 2-D motion vectors from adjacent-frame feature deltas. On MoDirect-SynBench, instruction tuning with DeltaDirect improves motion direction accuracy from 25.9% to 85.4%. On MoDirect-RealBench, DeltaDirect improves real-world motion direction accuracy by 21.9 points over the vanilla baseline without real-world tuning data, while preserving standard video-understanding performance. Code: https://github.com/KHU-VLL/DeltaDirect
Seeing Beyond the Scene: Analyzing and Mitigating Background Bias in Action Recognition
Dec 17, 2025



Human action recognition models often rely on background cues rather than human movement and pose to make predictions, a behavior known as background bias. We present a systematic analysis of background bias across classification models, contrastive text-image pretrained models, and Video Large Language Models (VLLM) and find that all exhibit a strong tendency to default to background reasoning. Next, we propose mitigation strategies for classification models and show that incorporating segmented human input effectively decreases background bias by 3.78%. Finally, we explore manual and automated prompt tuning for VLLMs, demonstrating that prompt design can steer predictions towards human-focused reasoning by 9.85%.
Unifying Specialized Visual Encoders for Video Language Models
Jan 02, 2025



The recent advent of Large Language Models (LLMs) has ushered sophisticated reasoning capabilities into the realm of video through Video Large Language Models (VideoLLMs). However, VideoLLMs currently rely on a single vision encoder for all of their visual processing, which limits the amount and type of visual information that can be conveyed to the LLM. Our method, MERV, Multi-Encoder Representation of Videos, instead leverages multiple frozen visual encoders to create a unified representation of a video, providing the VideoLLM with a comprehensive set of specialized visual knowledge. Spatio-temporally aligning the features from each encoder allows us to tackle a wider range of open-ended and multiple-choice video understanding questions and outperform prior state-of-the-art works. MERV is up to 3.7% better in accuracy than Video-LLaVA across the standard suite video understanding benchmarks, while also having a better Video-ChatGPT score. We also improve upon SeViLA, the previous best on zero-shot Perception Test accuracy, by 2.2%. MERV introduces minimal extra parameters and trains faster than equivalent single-encoder methods while parallelizing the visual processing. Finally, we provide qualitative evidence that MERV successfully captures domain knowledge from each of its encoders. Our results offer promising directions in utilizing multiple vision encoders for comprehensive video understanding.
A Sparse Bayesian Learning for Diagnosis of Nonstationary and Spatially Correlated Faults with Application to Multistation Assembly Systems
Oct 20, 2023Sensor technology developments provide a basis for effective fault diagnosis in manufacturing systems. However, the limited number of sensors due to physical constraints or undue costs hinders the accurate diagnosis in the actual process. In addition, time-varying operational conditions that generate nonstationary process faults and the correlation information in the process require to consider for accurate fault diagnosis in the manufacturing systems. This article proposes a novel fault diagnosis method: clustering spatially correlated sparse Bayesian learning (CSSBL), and explicitly demonstrates its applicability in a multistation assembly system that is vulnerable to the above challenges. Specifically, the method is based on a practical assumption that it will likely have a few process faults (sparse). In addition, the hierarchical structure of CSSBL has several parameterized prior distributions to address the above challenges. As posterior distributions of process faults do not have closed form, this paper derives approximate posterior distributions through Variational Bayes inference. The proposed method's efficacy is provided through numerical and real-world case studies utilizing an actual autobody assembly system. The generalizability of the proposed method allows the technique to be applied in fault diagnosis in other domains, including communication and healthcare systems.
Imbalanced Data Classification via Generative Adversarial Network with Application to Anomaly Detection in Additive Manufacturing Process
Nov 09, 2022Supervised classification methods have been widely utilized for the quality assurance of the advanced manufacturing process, such as additive manufacturing (AM) for anomaly (defects) detection. However, since abnormal states (with defects) occur much less frequently than normal ones (without defects) in the manufacturing process, the number of sensor data samples collected from a normal state outweighs that from an abnormal state. This issue causes imbalanced training data for classification models, thus deteriorating the performance of detecting abnormal states in the process. It is beneficial to generate effective artificial sample data for the abnormal states to make a more balanced training set. To achieve this goal, this paper proposes a novel data augmentation method based on a generative adversarial network (GAN) using additive manufacturing process image sensor data. The novelty of our approach is that a standard GAN and classifier are jointly optimized with techniques to stabilize the learning process of standard GAN. The diverse and high-quality generated samples provide balanced training data to the classifier. The iterative optimization between GAN and classifier provides the high-performance classifier. The effectiveness of the proposed method is validated by both open-source data and real-world case studies in polymer and metal AM processes.
Reinforcement Learning-based Defect Mitigation for Quality Assurance of Additive Manufacturing
Oct 28, 2022



Additive Manufacturing (AM) is a powerful technology that produces complex 3D geometries using various materials in a layer-by-layer fashion. However, quality assurance is the main challenge in AM industry due to the possible time-varying processing conditions during AM process. Notably, new defects may occur during printing, which cannot be mitigated by offline analysis tools that focus on existing defects. This challenge motivates this work to develop online learning-based methods to deal with the new defects during printing. Since AM typically fabricates a small number of customized products, this paper aims to create an online learning-based strategy to mitigate the new defects in AM process while minimizing the number of samples needed. The proposed method is based on model-free Reinforcement Learning (RL). It is called Continual G-learning since it transfers several sources of prior knowledge to reduce the needed training samples in the AM process. Offline knowledge is obtained from literature, while online knowledge is learned during printing. The proposed method develops a new algorithm for learning the optimal defect mitigation strategies proven the best performance when utilizing both knowledge sources. Numerical and real-world case studies in a fused filament fabrication (FFF) platform are performed and demonstrate the effectiveness of the proposed method.
A Novel Sparse Bayesian Learning and Its Application to Fault Diagnosis for Multistation Assembly Systems
Oct 28, 2022This paper addresses the problem of fault diagnosis in multistation assembly systems. Fault diagnosis is to identify process faults that cause the excessive dimensional variation of the product using dimensional measurements. For such problems, the challenge is solving an underdetermined system caused by a common phenomenon in practice; namely, the number of measurements is less than that of the process errors. To address this challenge, this paper attempts to solve the following two problems: (1) how to utilize the temporal correlation in the time series data of each process error and (2) how to apply prior knowledge regarding which process errors are more likely to be process faults. A novel sparse Bayesian learning method is proposed to achieve the above objectives. The method consists of three hierarchical layers. The first layer has parameterized prior distribution that exploits the temporal correlation of each process error. Furthermore, the second and third layers achieve the prior distribution representing the prior knowledge of process faults. Then, these prior distributions are updated with the likelihood function of the measurement samples from the process, resulting in the accurate posterior distribution of process faults from an underdetermined system. Since posterior distributions of process faults are intractable, this paper derives approximate posterior distributions via Variational Bayes inference. Numerical and simulation case studies using an actual autobody assembly process are performed to demonstrate the effectiveness of the proposed method.
Self-scalable Tanh (Stan): Faster Convergence and Better Generalization in Physics-informed Neural Networks
Apr 29, 2022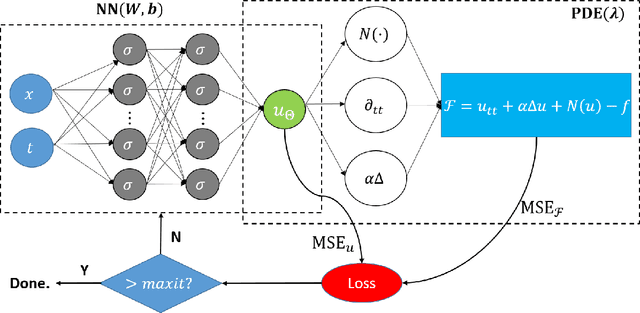
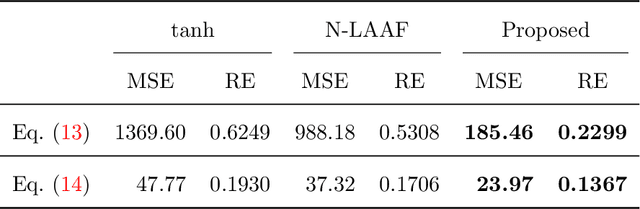
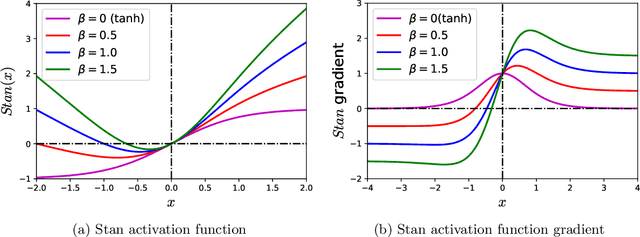
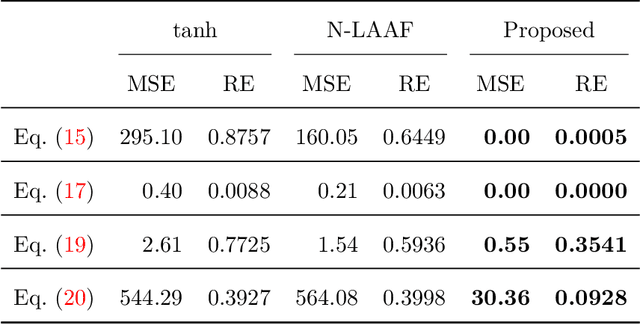
Physics-informed Neural Networks (PINNs) are gaining attention in the engineering and scientific literature for solving a range of differential equations with applications in weather modeling, healthcare, manufacturing, etc. Poor scalability is one of the barriers to utilizing PINNs for many real-world problems. To address this, a Self-scalable tanh (Stan) activation function is proposed for the PINNs. The proposed Stan function is smooth, non-saturating, and has a trainable parameter. During training, it can allow easy flow of gradients to compute the required derivatives and also enable systematic scaling of the input-output mapping. It is shown theoretically that the PINNs with the proposed Stan function have no spurious stationary points when using gradient descent algorithms. The proposed Stan is tested on a number of numerical studies involving general regression problems. It is subsequently used for solving multiple forward problems, which involve second-order derivatives and multiple dimensions, and an inverse problem where the thermal diffusivity of a rod is predicted with heat conduction data. These case studies establish empirically that the Stan activation function can achieve better training and more accurate predictions than the existing activation functions in the literature.
HAA500: Human-Centric Atomic Action Dataset with Curated Videos
Sep 11, 2020
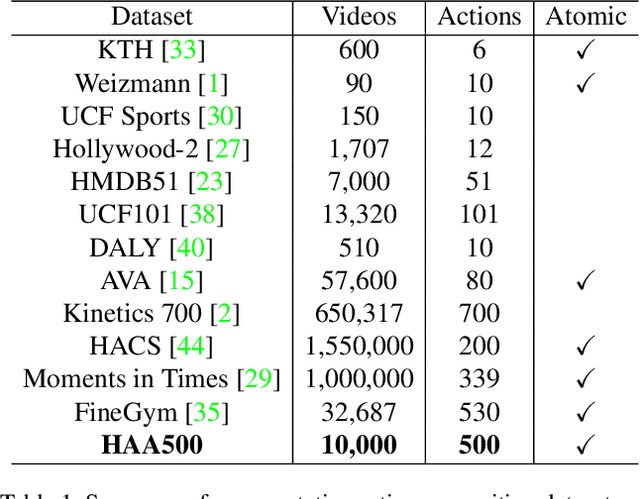
We contribute HAA500, a manually annotated human-centric atomic action dataset for action recognition on 500 classes with over 591k labeled frames. Unlike existing atomic action datasets, where coarse-grained atomic actions were labeled with action-verbs, e.g., "Throw", HAA500 contains fine-grained atomic actions where only consistent actions fall under the same label, e.g., "Baseball Pitching" vs "Free Throw in Basketball", to minimize ambiguities in action classification. HAA500 has been carefully curated to capture the movement of human figures with less spatio-temporal label noises to greatly enhance the training of deep neural networks. The advantages of HAA500 include: 1) human-centric actions with a high average of 69.7% detectable joints for the relevant human poses; 2) each video captures the essential elements of an atomic action without irrelevant frames; 3) fine-grained atomic action classes. Our extensive experiments validate the benefits of human-centric and atomic characteristics of HAA, which enables the trained model to improve prediction by attending to atomic human poses. We detail the HAA500 dataset statistics and collection methodology, and compare quantitatively with existing action recognition datasets.
CascadePSP: Toward Class-Agnostic and Very High-Resolution Segmentation via Global and Local Refinement
May 06, 2020
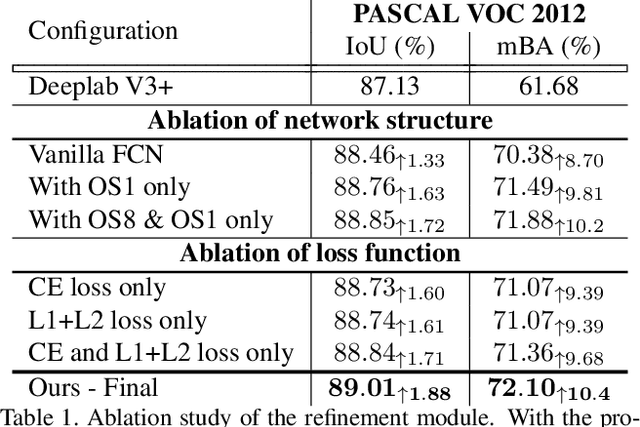
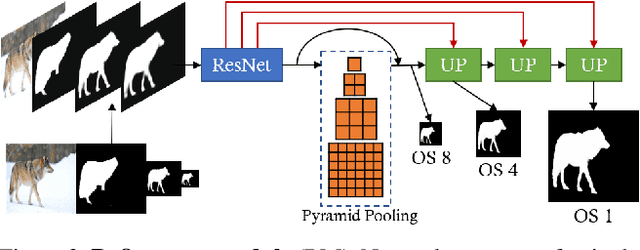
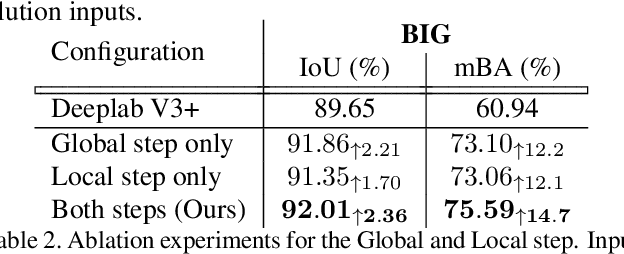
State-of-the-art semantic segmentation methods were almost exclusively trained on images within a fixed resolution range. These segmentations are inaccurate for very high-resolution images since using bicubic upsampling of low-resolution segmentation does not adequately capture high-resolution details along object boundaries. In this paper, we propose a novel approach to address the high-resolution segmentation problem without using any high-resolution training data. The key insight is our CascadePSP network which refines and corrects local boundaries whenever possible. Although our network is trained with low-resolution segmentation data, our method is applicable to any resolution even for very high-resolution images larger than 4K. We present quantitative and qualitative studies on different datasets to show that CascadePSP can reveal pixel-accurate segmentation boundaries using our novel refinement module without any finetuning. Thus, our method can be regarded as class-agnostic. Finally, we demonstrate the application of our model to scene parsing in multi-class segmentation.