 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBlitzGS: City-Scale Gaussian Splatting at Lightning Speed
May 13, 2026We present BlitzGS, a distributed 3DGS framework that reduces active Gaussian workload for fast city-scale reconstruction. BlitzGS manages this workload at three coupled levels. At the system level, the framework shards Gaussians across GPUs by index parity rather than spatial blocks. This approach mitigates the cross-block visibility redundancy inherent in spatial partitioning. Furthermore, it distributes each rendering step through a single cross-GPU exchange that routes projected Gaussians to their tile owners. At the model level, scheduled importance-scoring passes shrink the global Gaussian population. During these passes, the framework generates a per-Gaussian visibility weight to bias density-control updates toward contributing primitives and a per-view importance mask for the view-level renderer. At the view level, BlitzGS trims each camera's active set with a distance-based LOD gate to exclude excessively fine primitives for the current frustum and the importance-based culling mask to skip Gaussians with negligible cross-view contribution. On large-scale benchmarks, BlitzGS matches the rendering quality of recent large-scale baselines while delivering an order-of-magnitude speedup, training city-scale scenes in tens of minutes. Our code is available at https: //github.com/AkierRaee/BlitzGS.
GVGS: Gaussian Visibility-Aware Multi-View Geometry for Accurate Surface Reconstruction
Jan 28, 20263D Gaussian Splatting enables efficient optimization and high-quality rendering, yet accurate surface reconstruction remains challenging. Prior methods improve surface reconstruction by refining Gaussian depth estimates, either via multi-view geometric consistency or through monocular depth priors. However, multi-view constraints become unreliable under large geometric discrepancies, while monocular priors suffer from scale ambiguity and local inconsistency, ultimately leading to inaccurate Gaussian depth supervision. To address these limitations, we introduce a Gaussian visibility-aware multi-view geometric consistency constraint that aggregates the visibility of shared Gaussian primitives across views, enabling more accurate and stable geometric supervision. In addition, we propose a progressive quadtree-calibrated Monocular depth constraint that performs block-wise affine calibration from coarse to fine spatial scales, mitigating the scale ambiguity of depth priors while preserving fine-grained surface details. Extensive experiments on DTU and TNT datasets demonstrate consistent improvements in geometric accuracy over prior Gaussian-based and implicit surface reconstruction methods. Codes are available at an anonymous repository: https://github.com/GVGScode/GVGS.
Neural Cone Radiosity for Interactive Global Illumination with Glossy Materials
Sep 09, 2025Modeling of high-frequency outgoing radiance distributions has long been a key challenge in rendering, particularly for glossy material. Such distributions concentrate radiative energy within a narrow lobe and are highly sensitive to changes in view direction. However, existing neural radiosity methods, which primarily rely on positional feature encoding, exhibit notable limitations in capturing these high-frequency, strongly view-dependent radiance distributions. To address this, we propose a highly-efficient approach by reflectance-aware ray cone encoding based on the neural radiosity framework, named neural cone radiosity. The core idea is to employ a pre-filtered multi-resolution hash grid to accurately approximate the glossy BSDF lobe, embedding view-dependent reflectance characteristics directly into the encoding process through continuous spatial aggregation. Our design not only significantly improves the network's ability to model high-frequency reflection distributions but also effectively handles surfaces with a wide range of glossiness levels, from highly glossy to low-gloss finishes. Meanwhile, our method reduces the network's burden in fitting complex radiance distributions, allowing the overall architecture to remain compact and efficient. Comprehensive experimental results demonstrate that our method consistently produces high-quality, noise-free renderings in real time under various glossiness conditions, and delivers superior fidelity and realism compared to baseline approaches.
Geometry-Aware Global Feature Aggregation for Real-Time Indirect Illumination
Aug 12, 2025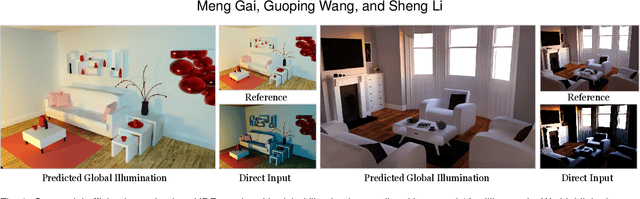
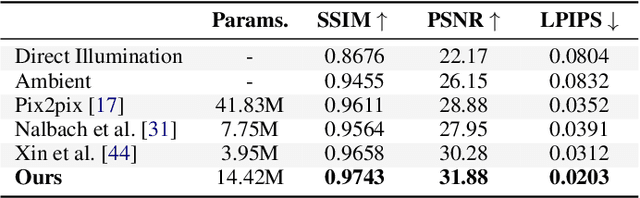
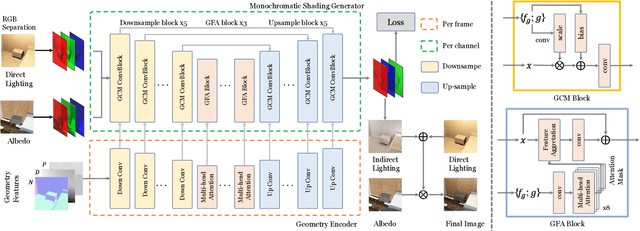

Real-time rendering with global illumination is crucial to afford the user realistic experience in virtual environments. We present a learning-based estimator to predict diffuse indirect illumination in screen space, which then is combined with direct illumination to synthesize globally-illuminated high dynamic range (HDR) results. Our approach tackles the challenges of capturing long-range/long-distance indirect illumination when employing neural networks and is generalized to handle complex lighting and scenarios. From the neural network thinking of the solver to the rendering equation, we present a novel network architecture to predict indirect illumination. Our network is equipped with a modified attention mechanism that aggregates global information guided by spacial geometry features, as well as a monochromatic design that encodes each color channel individually. We conducted extensive evaluations, and the experimental results demonstrate our superiority over previous learning-based techniques. Our approach excels at handling complex lighting such as varying-colored lighting and environment lighting. It can successfully capture distant indirect illumination and simulates the interreflections between textured surfaces well (i.e., color bleeding effects); it can also effectively handle new scenes that are not present in the training dataset.
Vertex Features for Neural Global Illumination
Aug 11, 2025Recent research on learnable neural representations has been widely adopted in the field of 3D scene reconstruction and neural rendering applications. However, traditional feature grid representations often suffer from substantial memory footprint, posing a significant bottleneck for modern parallel computing hardware. In this paper, we present neural vertex features, a generalized formulation of learnable representation for neural rendering tasks involving explicit mesh surfaces. Instead of uniformly distributing neural features throughout 3D space, our method stores learnable features directly at mesh vertices, leveraging the underlying geometry as a compact and structured representation for neural processing. This not only optimizes memory efficiency, but also improves feature representation by aligning compactly with the surface using task-specific geometric priors. We validate our neural representation across diverse neural rendering tasks, with a specific emphasis on neural radiosity. Experimental results demonstrate that our method reduces memory consumption to only one-fifth (or even less) of grid-based representations, while maintaining comparable rendering quality and lowering inference overhead.
NAT: Neural Acoustic Transfer for Interactive Scenes in Real Time
Jun 06, 2025



Previous acoustic transfer methods rely on extensive precomputation and storage of data to enable real-time interaction and auditory feedback. However, these methods struggle with complex scenes, especially when dynamic changes in object position, material, and size significantly alter sound effects. These continuous variations lead to fluctuating acoustic transfer distributions, making it challenging to represent with basic data structures and render efficiently in real time. To address this challenge, we present Neural Acoustic Transfer, a novel approach that utilizes an implicit neural representation to encode precomputed acoustic transfer and its variations, allowing for real-time prediction of sound fields under varying conditions. To efficiently generate the training data required for the neural acoustic field, we developed a fast Monte-Carlo-based boundary element method (BEM) approximation for general scenarios with smooth Neumann conditions. Additionally, we implemented a GPU-accelerated version of standard BEM for scenarios requiring higher precision. These methods provide the necessary training data, enabling our neural network to accurately model the sound radiation space. We demonstrate our method's numerical accuracy and runtime efficiency (within several milliseconds for 30s audio) through comprehensive validation and comparisons in diverse acoustic transfer scenarios. Our approach allows for efficient and accurate modeling of sound behavior in dynamically changing environments, which can benefit a wide range of interactive applications such as virtual reality, augmented reality, and advanced audio production.
HUG: Hierarchical Urban Gaussian Splatting with Block-Based Reconstruction
Apr 23, 2025As urban 3D scenes become increasingly complex and the demand for high-quality rendering grows, efficient scene reconstruction and rendering techniques become crucial. We present HUG, a novel approach to address inefficiencies in handling large-scale urban environments and intricate details based on 3D Gaussian splatting. Our method optimizes data partitioning and the reconstruction pipeline by incorporating a hierarchical neural Gaussian representation. We employ an enhanced block-based reconstruction pipeline focusing on improving reconstruction quality within each block and reducing the need for redundant training regions around block boundaries. By integrating neural Gaussian representation with a hierarchical architecture, we achieve high-quality scene rendering at a low computational cost. This is demonstrated by our state-of-the-art results on public benchmarks, which prove the effectiveness and advantages in large-scale urban scene representation.
SAIP-Net: Enhancing Remote Sensing Image Segmentation via Spectral Adaptive Information Propagation
Apr 23, 2025



Semantic segmentation of remote sensing imagery demands precise spatial boundaries and robust intra-class consistency, challenging conventional hierarchical models. To address limitations arising from spatial domain feature fusion and insufficient receptive fields, this paper introduces SAIP-Net, a novel frequency-aware segmentation framework that leverages Spectral Adaptive Information Propagation. SAIP-Net employs adaptive frequency filtering and multi-scale receptive field enhancement to effectively suppress intra-class feature inconsistencies and sharpen boundary lines. Comprehensive experiments demonstrate significant performance improvements over state-of-the-art methods, highlighting the effectiveness of spectral-adaptive strategies combined with expanded receptive fields for remote sensing image segmentation.
Instance-Adaptive Keypoint Learning with Local-to-Global Geometric Aggregation for Category-Level Object Pose Estimation
Apr 21, 2025



Category-level object pose estimation aims to predict the 6D pose and size of previously unseen instances from predefined categories, requiring strong generalization across diverse object instances. Although many previous methods attempt to mitigate intra-class variations, they often struggle with instances exhibiting complex geometries or significant deviations from canonical shapes. To address this challenge, we propose INKL-Pose, a novel category-level object pose estimation framework that enables INstance-adaptive Keypoint Learning with local-to-global geometric aggregation. Specifically, our approach first predicts semantically consistent and geometric informative keypoints through an Instance-Adaptive Keypoint Generator, then refines them with: (1) a Local Keypoint Feature Aggregator capturing fine-grained geometries, and (2) a Global Keypoint Feature Aggregator using bidirectional Mamba for structural consistency. To enable bidirectional modeling in Mamba, we introduce a Feature Sequence Flipping strategy that preserves spatial coherence while constructing backward feature sequences. Additionally, we design a surface loss and a separation loss to enforce uniform coverage and spatial diversity in keypoint distribution. The generated keypoints are finally mapped to a canonical space for regressing the object's 6D pose and size. Extensive experiments on CAMERA25, REAL275, and HouseCat6D demonstrate that INKL-Pose achieves state-of-the-art performance and significantly outperforms existing methods.
Neural-Polyptych: Content Controllable Painting Recreation for Diverse Genres
Sep 29, 2024



To bridge the gap between artists and non-specialists, we present a unified framework, Neural-Polyptych, to facilitate the creation of expansive, high-resolution paintings by seamlessly incorporating interactive hand-drawn sketches with fragments from original paintings. We have designed a multi-scale GAN-based architecture to decompose the generation process into two parts, each responsible for identifying global and local features. To enhance the fidelity of semantic details generated from users' sketched outlines, we introduce a Correspondence Attention module utilizing our Reference Bank strategy. This ensures the creation of high-quality, intricately detailed elements within the artwork. The final result is achieved by carefully blending these local elements while preserving coherent global consistency. Consequently, this methodology enables the production of digital paintings at megapixel scale, accommodating diverse artistic expressions and enabling users to recreate content in a controlled manner. We validate our approach to diverse genres of both Eastern and Western paintings. Applications such as large painting extension, texture shuffling, genre switching, mural art restoration, and recomposition can be successfully based on our framework.