 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMultiface: A Dataset for Neural Face Rendering
Jul 22, 2022



Photorealistic avatars of human faces have come a long way in recent years, yet research along this area is limited by a lack of publicly available, high-quality datasets covering both, dense multi-view camera captures, and rich facial expressions of the captured subjects. In this work, we present Multiface, a new multi-view, high-resolution human face dataset collected from 13 identities at Reality Labs Research for neural face rendering. We introduce Mugsy, a large scale multi-camera apparatus to capture high-resolution synchronized videos of a facial performance. The goal of Multiface is to close the gap in accessibility to high quality data in the academic community and to enable research in VR telepresence. Along with the release of the dataset, we conduct ablation studies on the influence of different model architectures toward the model's interpolation capacity of novel viewpoint and expressions. With a conditional VAE model serving as our baseline, we found that adding spatial bias, texture warp field, and residual connections improves performance on novel view synthesis. Our code and data is available at: https://github.com/facebookresearch/multiface
HAA500: Human-Centric Atomic Action Dataset with Curated Videos
Sep 11, 2020
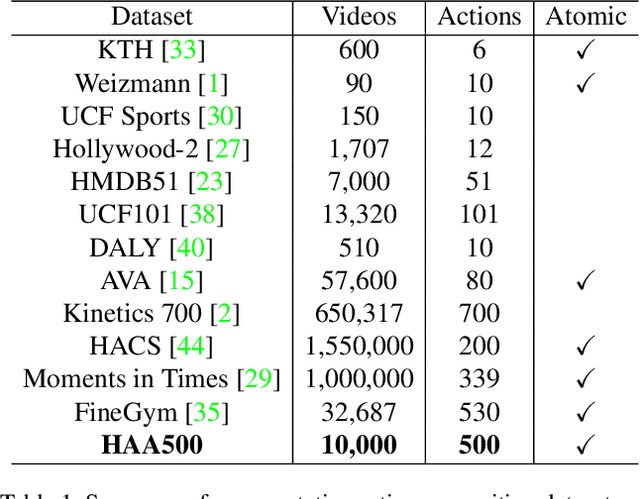
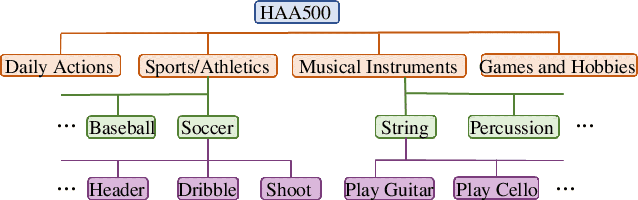
We contribute HAA500, a manually annotated human-centric atomic action dataset for action recognition on 500 classes with over 591k labeled frames. Unlike existing atomic action datasets, where coarse-grained atomic actions were labeled with action-verbs, e.g., "Throw", HAA500 contains fine-grained atomic actions where only consistent actions fall under the same label, e.g., "Baseball Pitching" vs "Free Throw in Basketball", to minimize ambiguities in action classification. HAA500 has been carefully curated to capture the movement of human figures with less spatio-temporal label noises to greatly enhance the training of deep neural networks. The advantages of HAA500 include: 1) human-centric actions with a high average of 69.7% detectable joints for the relevant human poses; 2) each video captures the essential elements of an atomic action without irrelevant frames; 3) fine-grained atomic action classes. Our extensive experiments validate the benefits of human-centric and atomic characteristics of HAA, which enables the trained model to improve prediction by attending to atomic human poses. We detail the HAA500 dataset statistics and collection methodology, and compare quantitatively with existing action recognition datasets.