 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTADoc: Robust Time-Aware Document Image Dewarping
Aug 09, 2025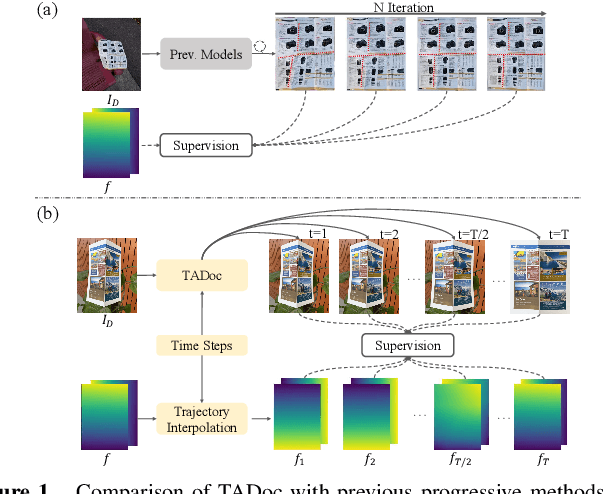
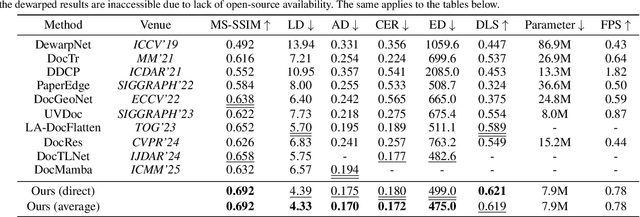
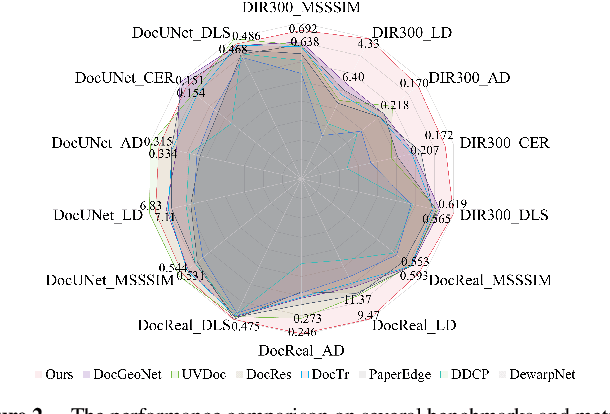
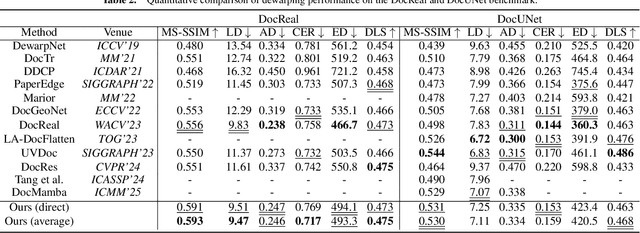
Flattening curved, wrinkled, and rotated document images captured by portable photographing devices, termed document image dewarping, has become an increasingly important task with the rise of digital economy and online working. Although many methods have been proposed recently, they often struggle to achieve satisfactory results when confronted with intricate document structures and higher degrees of deformation in real-world scenarios. Our main insight is that, unlike other document restoration tasks (e.g., deblurring), dewarping in real physical scenes is a progressive motion rather than a one-step transformation. Based on this, we have undertaken two key initiatives. Firstly, we reformulate this task, modeling it for the first time as a dynamic process that encompasses a series of intermediate states. Secondly, we design a lightweight framework called TADoc (Time-Aware Document Dewarping Network) to address the geometric distortion of document images. In addition, due to the inadequacy of OCR metrics for document images containing sparse text, the comprehensiveness of evaluation is insufficient. To address this shortcoming, we propose a new metric -- DLS (Document Layout Similarity) -- to evaluate the effectiveness of document dewarping in downstream tasks. Extensive experiments and in-depth evaluations have been conducted and the results indicate that our model possesses strong robustness, achieving superiority on several benchmarks with different document types and degrees of distortion.
Uni-DocDiff: A Unified Document Restoration Model Based on Diffusion
Aug 06, 2025Removing various degradations from damaged documents greatly benefits digitization, downstream document analysis, and readability. Previous methods often treat each restoration task independently with dedicated models, leading to a cumbersome and highly complex document processing system. Although recent studies attempt to unify multiple tasks, they often suffer from limited scalability due to handcrafted prompts and heavy preprocessing, and fail to fully exploit inter-task synergy within a shared architecture. To address the aforementioned challenges, we propose Uni-DocDiff, a Unified and highly scalable Document restoration model based on Diffusion. Uni-DocDiff develops a learnable task prompt design, ensuring exceptional scalability across diverse tasks. To further enhance its multi-task capabilities and address potential task interference, we devise a novel \textbf{Prior \textbf{P}ool}, a simple yet comprehensive mechanism that combines both local high-frequency features and global low-frequency features. Additionally, we design the \textbf{Prior \textbf{F}usion \textbf{M}odule (PFM)}, which enables the model to adaptively select the most relevant prior information for each specific task. Extensive experiments show that the versatile Uni-DocDiff achieves performance comparable or even superior performance compared with task-specific expert models, and simultaneously holds the task scalability for seamless adaptation to new tasks.
Gather and Trace: Rethinking Video TextVQA from an Instance-oriented Perspective
Aug 06, 2025Video text-based visual question answering (Video TextVQA) aims to answer questions by explicitly reading and reasoning about the text involved in a video. Most works in this field follow a frame-level framework which suffers from redundant text entities and implicit relation modeling, resulting in limitations in both accuracy and efficiency. In this paper, we rethink the Video TextVQA task from an instance-oriented perspective and propose a novel model termed GAT (Gather and Trace). First, to obtain accurate reading result for each video text instance, a context-aggregated instance gathering module is designed to integrate the visual appearance, layout characteristics, and textual contents of the related entities into a unified textual representation. Then, to capture dynamic evolution of text in the video flow, an instance-focused trajectory tracing module is utilized to establish spatio-temporal relationships between instances and infer the final answer. Extensive experiments on several public Video TextVQA datasets validate the effectiveness and generalization of our framework. GAT outperforms existing Video TextVQA methods, video-language pretraining methods, and video large language models in both accuracy and inference speed. Notably, GAT surpasses the previous state-of-the-art Video TextVQA methods by 3.86\% in accuracy and achieves ten times of faster inference speed than video large language models. The source code is available at https://github.com/zhangyan-ucas/GAT.
Step-Audio 2 Technical Report
Jul 24, 2025



This paper presents Step-Audio 2, an end-to-end multi-modal large language model designed for industry-strength audio understanding and speech conversation. By integrating a latent audio encoder and reasoning-centric reinforcement learning (RL), Step-Audio 2 achieves promising performance in automatic speech recognition (ASR) and audio understanding. To facilitate genuine end-to-end speech conversation, Step-Audio 2 incorporates the generation of discrete audio tokens into language modeling, significantly enhancing its responsiveness to paralinguistic information such as speaking styles and emotions. To effectively leverage the rich textual and acoustic knowledge in real-world data, Step-Audio 2 integrates retrieval-augmented generation (RAG) and is able to call external tools such as web search to mitigate hallucination and audio search to switch timbres. Trained on millions of hours of speech and audio data, Step-Audio 2 delivers intelligence and expressiveness across diverse conversational scenarios. Evaluation results demonstrate that Step-Audio 2 achieves state-of-the-art performance on various audio understanding and conversational benchmarks compared to other open-source and commercial solutions. Please visit https://github.com/stepfun-ai/Step-Audio2 for more information.
Single-to-mix Modality Alignment with Multimodal Large Language Model for Document Image Machine Translation
Jul 10, 2025Document Image Machine Translation (DIMT) aims to translate text within document images, facing generalization challenges due to limited training data and the complex interplay between visual and textual information. To address these challenges, we introduce M4Doc, a novel single-to-mix modality alignment framework leveraging Multimodal Large Language Models (MLLMs). M4Doc aligns an image-only encoder with the multimodal representations of an MLLM, pre-trained on large-scale document image datasets. This alignment enables a lightweight DIMT model to learn crucial visual-textual correlations during training. During inference, M4Doc bypasses the MLLM, maintaining computational efficiency while benefiting from its multimodal knowledge. Comprehensive experiments demonstrate substantial improvements in translation quality, especially in cross-domain generalization and challenging document image scenarios.
The Four Color Theorem for Cell Instance Segmentation
Jun 11, 2025Cell instance segmentation is critical to analyzing biomedical images, yet accurately distinguishing tightly touching cells remains a persistent challenge. Existing instance segmentation frameworks, including detection-based, contour-based, and distance mapping-based approaches, have made significant progress, but balancing model performance with computational efficiency remains an open problem. In this paper, we propose a novel cell instance segmentation method inspired by the four-color theorem. By conceptualizing cells as countries and tissues as oceans, we introduce a four-color encoding scheme that ensures adjacent instances receive distinct labels. This reformulation transforms instance segmentation into a constrained semantic segmentation problem with only four predicted classes, substantially simplifying the instance differentiation process. To solve the training instability caused by the non-uniqueness of four-color encoding, we design an asymptotic training strategy and encoding transformation method. Extensive experiments on various modes demonstrate our approach achieves state-of-the-art performance. The code is available at https://github.com/zhangye-zoe/FCIS.
Step-Audio-AQAA: a Fully End-to-End Expressive Large Audio Language Model
Jun 10, 2025



Large Audio-Language Models (LALMs) have significantly advanced intelligent human-computer interaction, yet their reliance on text-based outputs limits their ability to generate natural speech responses directly, hindering seamless audio interactions. To address this, we introduce Step-Audio-AQAA, a fully end-to-end LALM designed for Audio Query-Audio Answer (AQAA) tasks. The model integrates a dual-codebook audio tokenizer for linguistic and semantic feature extraction, a 130-billion-parameter backbone LLM and a neural vocoder for high-fidelity speech synthesis. Our post-training approach employs interleaved token-output of text and audio to enhance semantic coherence and combines Direct Preference Optimization (DPO) with model merge to improve performance. Evaluations on the StepEval-Audio-360 benchmark demonstrate that Step-Audio-AQAA excels especially in speech control, outperforming the state-of-art LALMs in key areas. This work contributes a promising solution for end-to-end LALMs and highlights the critical role of token-based vocoder in enhancing overall performance for AQAA tasks.
When Semantics Mislead Vision: Mitigating Large Multimodal Models Hallucinations in Scene Text Spotting and Understanding
Jun 05, 2025



Large Multimodal Models (LMMs) have achieved impressive progress in visual perception and reasoning. However, when confronted with visually ambiguous or non-semantic scene text, they often struggle to accurately spot and understand the content, frequently generating semantically plausible yet visually incorrect answers, which we refer to as semantic hallucination. In this work, we investigate the underlying causes of semantic hallucination and identify a key finding: Transformer layers in LLM with stronger attention focus on scene text regions are less prone to producing semantic hallucinations. Thus, we propose a training-free semantic hallucination mitigation framework comprising two key components: (1) ZoomText, a coarse-to-fine strategy that identifies potential text regions without external detectors; and (2) Grounded Layer Correction, which adaptively leverages the internal representations from layers less prone to hallucination to guide decoding, correcting hallucinated outputs for non-semantic samples while preserving the semantics of meaningful ones. To enable rigorous evaluation, we introduce TextHalu-Bench, a benchmark of over 1,730 samples spanning both semantic and non-semantic cases, with manually curated question-answer pairs designed to probe model hallucinations. Extensive experiments demonstrate that our method not only effectively mitigates semantic hallucination but also achieves strong performance on public benchmarks for scene text spotting and understanding.
Beyond Cropped Regions: New Benchmark and Corresponding Baseline for Chinese Scene Text Retrieval in Diverse Layouts
Jun 05, 2025



Chinese scene text retrieval is a practical task that aims to search for images containing visual instances of a Chinese query text. This task is extremely challenging because Chinese text often features complex and diverse layouts in real-world scenes. Current efforts tend to inherit the solution for English scene text retrieval, failing to achieve satisfactory performance. In this paper, we establish a Diversified Layout benchmark for Chinese Street View Text Retrieval (DL-CSVTR), which is specifically designed to evaluate retrieval performance across various text layouts, including vertical, cross-line, and partial alignments. To address the limitations in existing methods, we propose Chinese Scene Text Retrieval CLIP (CSTR-CLIP), a novel model that integrates global visual information with multi-granularity alignment training. CSTR-CLIP applies a two-stage training process to overcome previous limitations, such as the exclusion of visual features outside the text region and reliance on single-granularity alignment, thereby enabling the model to effectively handle diverse text layouts. Experiments on existing benchmark show that CSTR-CLIP outperforms the previous state-of-the-art model by 18.82% accuracy and also provides faster inference speed. Further analysis on DL-CSVTR confirms the superior performance of CSTR-CLIP in handling various text layouts. The dataset and code will be publicly available to facilitate research in Chinese scene text retrieval.
VidText: Towards Comprehensive Evaluation for Video Text Understanding
May 28, 2025Visual texts embedded in videos carry rich semantic information, which is crucial for both holistic video understanding and fine-grained reasoning about local human actions. However, existing video understanding benchmarks largely overlook textual information, while OCR-specific benchmarks are constrained to static images, limiting their ability to capture the interaction between text and dynamic visual contexts. To address this gap, we propose VidText, a new benchmark designed for comprehensive and in-depth evaluation of video text understanding. VidText offers the following key features: 1) It covers a wide range of real-world scenarios and supports multilingual content, encompassing diverse settings where video text naturally appears. 2) It introduces a hierarchical evaluation framework with video-level, clip-level, and instance-level tasks, enabling assessment of both global summarization and local retrieval capabilities. 3) The benchmark also introduces a set of paired perception reasoning tasks, ranging from visual text perception to cross-modal reasoning between textual and visual information. Extensive experiments on 18 state-of-the-art Large Multimodal Models (LMMs) reveal that current models struggle across most tasks, with significant room for improvement. Further analysis highlights the impact of both model-intrinsic factors, such as input resolution and OCR capability, and external factors, including the use of auxiliary information and Chain-of-Thought reasoning strategies. We hope VidText will fill the current gap in video understanding benchmarks and serve as a foundation for future research on multimodal reasoning with video text in dynamic environments.