 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIMTBench: A Multi-Scenario Cross-Modal Collaborative Evaluation Benchmark for In-Image Machine Translation
Mar 11, 2026End-to-end In-Image Machine Translation (IIMT) aims to convert text embedded within an image into a target language while preserving the original visual context, layout, and rendering style. However, existing IIMT benchmarks are largely synthetic and thus fail to reflect real-world complexity, while current evaluation protocols focus on single-modality metrics and overlook cross-modal faithfulness between rendered text and model outputs. To address these shortcomings, we present In-image Machine Translation Benchmark (IMTBench), a new benchmark of 2,500 image translation samples covering four practical scenarios and nine languages. IMTBench supports multi-aspect evaluation, including translation quality, background preservation, overall image quality, and a cross-modal alignment score that measures consistency between the translated text produced by the model and the text rendered in the translated image. We benchmark strong commercial cascade systems, and both closed- and open-source unified multi-modal models, and observe large performance gaps across scenarios and languages, especially on natural scenes and resource-limited languages, highlighting substantial headroom for end-to-end image text translation. We hope IMTBench establishes a standardized benchmark to accelerate progress in this emerging task.
TADoc: Robust Time-Aware Document Image Dewarping
Aug 09, 2025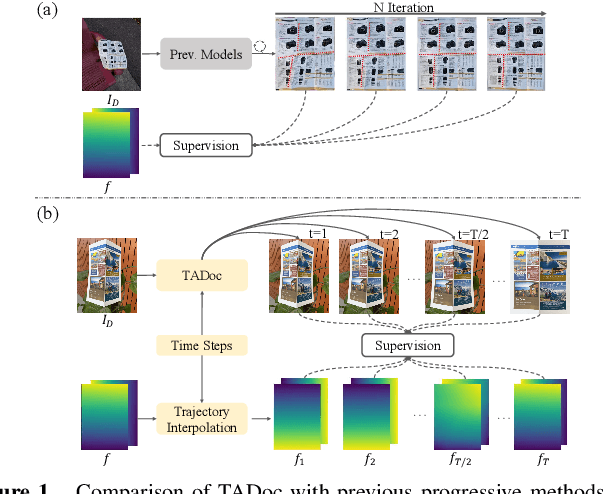
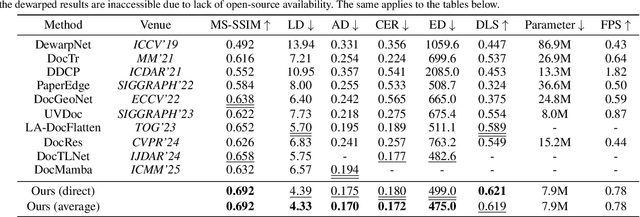
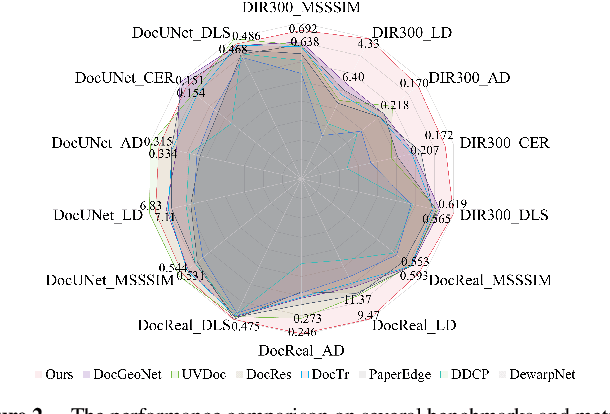
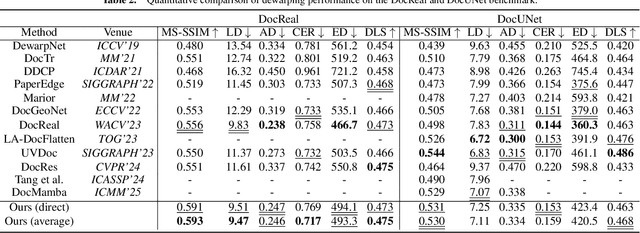
Flattening curved, wrinkled, and rotated document images captured by portable photographing devices, termed document image dewarping, has become an increasingly important task with the rise of digital economy and online working. Although many methods have been proposed recently, they often struggle to achieve satisfactory results when confronted with intricate document structures and higher degrees of deformation in real-world scenarios. Our main insight is that, unlike other document restoration tasks (e.g., deblurring), dewarping in real physical scenes is a progressive motion rather than a one-step transformation. Based on this, we have undertaken two key initiatives. Firstly, we reformulate this task, modeling it for the first time as a dynamic process that encompasses a series of intermediate states. Secondly, we design a lightweight framework called TADoc (Time-Aware Document Dewarping Network) to address the geometric distortion of document images. In addition, due to the inadequacy of OCR metrics for document images containing sparse text, the comprehensiveness of evaluation is insufficient. To address this shortcoming, we propose a new metric -- DLS (Document Layout Similarity) -- to evaluate the effectiveness of document dewarping in downstream tasks. Extensive experiments and in-depth evaluations have been conducted and the results indicate that our model possesses strong robustness, achieving superiority on several benchmarks with different document types and degrees of distortion.
Uni-DocDiff: A Unified Document Restoration Model Based on Diffusion
Aug 06, 2025Removing various degradations from damaged documents greatly benefits digitization, downstream document analysis, and readability. Previous methods often treat each restoration task independently with dedicated models, leading to a cumbersome and highly complex document processing system. Although recent studies attempt to unify multiple tasks, they often suffer from limited scalability due to handcrafted prompts and heavy preprocessing, and fail to fully exploit inter-task synergy within a shared architecture. To address the aforementioned challenges, we propose Uni-DocDiff, a Unified and highly scalable Document restoration model based on Diffusion. Uni-DocDiff develops a learnable task prompt design, ensuring exceptional scalability across diverse tasks. To further enhance its multi-task capabilities and address potential task interference, we devise a novel \textbf{Prior \textbf{P}ool}, a simple yet comprehensive mechanism that combines both local high-frequency features and global low-frequency features. Additionally, we design the \textbf{Prior \textbf{F}usion \textbf{M}odule (PFM)}, which enables the model to adaptively select the most relevant prior information for each specific task. Extensive experiments show that the versatile Uni-DocDiff achieves performance comparable or even superior performance compared with task-specific expert models, and simultaneously holds the task scalability for seamless adaptation to new tasks.
The Devil is in Fine-tuning and Long-tailed Problems:A New Benchmark for Scene Text Detection
May 21, 2025Scene text detection has seen the emergence of high-performing methods that excel on academic benchmarks. However, these detectors often fail to replicate such success in real-world scenarios. We uncover two key factors contributing to this discrepancy through extensive experiments. First, a \textit{Fine-tuning Gap}, where models leverage \textit{Dataset-Specific Optimization} (DSO) paradigm for one domain at the cost of reduced effectiveness in others, leads to inflated performances on academic benchmarks. Second, the suboptimal performance in practical settings is primarily attributed to the long-tailed distribution of texts, where detectors struggle with rare and complex categories as artistic or overlapped text. Given that the DSO paradigm might undermine the generalization ability of models, we advocate for a \textit{Joint-Dataset Learning} (JDL) protocol to alleviate the Fine-tuning Gap. Additionally, an error analysis is conducted to identify three major categories and 13 subcategories of challenges in long-tailed scene text, upon which we propose a Long-Tailed Benchmark (LTB). LTB facilitates a comprehensive evaluation of ability to handle a diverse range of long-tailed challenges. We further introduce MAEDet, a self-supervised learning-based method, as a strong baseline for LTB. The code is available at https://github.com/pd162/LTB.
Visual Text Processing: A Comprehensive Review and Unified Evaluation
Apr 30, 2025



Visual text is a crucial component in both document and scene images, conveying rich semantic information and attracting significant attention in the computer vision community. Beyond traditional tasks such as text detection and recognition, visual text processing has witnessed rapid advancements driven by the emergence of foundation models, including text image reconstruction and text image manipulation. Despite significant progress, challenges remain due to the unique properties that differentiate text from general objects. Effectively capturing and leveraging these distinct textual characteristics is essential for developing robust visual text processing models. In this survey, we present a comprehensive, multi-perspective analysis of recent advancements in visual text processing, focusing on two key questions: (1) What textual features are most suitable for different visual text processing tasks? (2) How can these distinctive text features be effectively incorporated into processing frameworks? Furthermore, we introduce VTPBench, a new benchmark that encompasses a broad range of visual text processing datasets. Leveraging the advanced visual quality assessment capabilities of multimodal large language models (MLLMs), we propose VTPScore, a novel evaluation metric designed to ensure fair and reliable evaluation. Our empirical study with more than 20 specific models reveals substantial room for improvement in the current techniques. Our aim is to establish this work as a fundamental resource that fosters future exploration and innovation in the dynamic field of visual text processing. The relevant repository is available at https://github.com/shuyansy/Visual-Text-Processing-survey.
Beyond Flat Text: Dual Self-inherited Guidance for Visual Text Generation
Jan 10, 2025



In real-world images, slanted or curved texts, especially those on cans, banners, or badges, appear as frequently, if not more so, than flat texts due to artistic design or layout constraints. While high-quality visual text generation has become available with the advanced generative capabilities of diffusion models, these models often produce distorted text and inharmonious text background when given slanted or curved text layouts due to training data limitation. In this paper, we introduce a new training-free framework, STGen, which accurately generates visual texts in challenging scenarios (\eg, slanted or curved text layouts) while harmonizing them with the text background. Our framework decomposes the visual text generation process into two branches: (i) \textbf{Semantic Rectification Branch}, which leverages the ability in generating flat but accurate visual texts of the model to guide the generation of challenging scenarios. The generated latent of flat text is abundant in accurate semantic information related both to the text itself and its background. By incorporating this, we rectify the semantic information of the texts and harmonize the integration of the text with its background in complex layouts. (ii) \textbf{Structure Injection Branch}, which reinforces the visual text structure during inference. We incorporate the latent information of the glyph image, rich in glyph structure, as a new condition to further strengthen the text structure. To enhance image harmony, we also apply an effective combination method to merge the priors, providing a solid foundation for generation. Extensive experiments across a variety of visual text layouts demonstrate that our framework achieves superior accuracy and outstanding quality.
First Creating Backgrounds Then Rendering Texts: A New Paradigm for Visual Text Blending
Oct 14, 2024



Diffusion models, known for their impressive image generation abilities, have played a pivotal role in the rise of visual text generation. Nevertheless, existing visual text generation methods often focus on generating entire images with text prompts, leading to imprecise control and limited practicality. A more promising direction is visual text blending, which focuses on seamlessly merging texts onto text-free backgrounds. However, existing visual text blending methods often struggle to generate high-fidelity and diverse images due to a shortage of backgrounds for synthesis and limited generalization capabilities. To overcome these challenges, we propose a new visual text blending paradigm including both creating backgrounds and rendering texts. Specifically, a background generator is developed to produce high-fidelity and text-free natural images. Moreover, a text renderer named GlyphOnly is designed for achieving visually plausible text-background integration. GlyphOnly, built on a Stable Diffusion framework, utilizes glyphs and backgrounds as conditions for accurate rendering and consistency control, as well as equipped with an adaptive text block exploration strategy for small-scale text rendering. We also explore several downstream applications based on our method, including scene text dataset synthesis for boosting scene text detectors, as well as text image customization and editing. Code and model will be available at \url{https://github.com/Zhenhang-Li/GlyphOnly}.
TextCtrl: Diffusion-based Scene Text Editing with Prior Guidance Control
Oct 14, 2024



Centred on content modification and style preservation, Scene Text Editing (STE) remains a challenging task despite considerable progress in text-to-image synthesis and text-driven image manipulation recently. GAN-based STE methods generally encounter a common issue of model generalization, while Diffusion-based STE methods suffer from undesired style deviations. To address these problems, we propose TextCtrl, a diffusion-based method that edits text with prior guidance control. Our method consists of two key components: (i) By constructing fine-grained text style disentanglement and robust text glyph structure representation, TextCtrl explicitly incorporates Style-Structure guidance into model design and network training, significantly improving text style consistency and rendering accuracy. (ii) To further leverage the style prior, a Glyph-adaptive Mutual Self-attention mechanism is proposed which deconstructs the implicit fine-grained features of the source image to enhance style consistency and vision quality during inference. Furthermore, to fill the vacancy of the real-world STE evaluation benchmark, we create the first real-world image-pair dataset termed ScenePair for fair comparisons. Experiments demonstrate the effectiveness of TextCtrl compared with previous methods concerning both style fidelity and text accuracy.
PianoBART: Symbolic Piano Music Generation and Understanding with Large-Scale Pre-Training
Jun 26, 2024



Learning musical structures and composition patterns is necessary for both music generation and understanding, but current methods do not make uniform use of learned features to generate and comprehend music simultaneously. In this paper, we propose PianoBART, a pre-trained model that uses BART for both symbolic piano music generation and understanding. We devise a multi-level object selection strategy for different pre-training tasks of PianoBART, which can prevent information leakage or loss and enhance learning ability. The musical semantics captured in pre-training are fine-tuned for music generation and understanding tasks. Experiments demonstrate that PianoBART efficiently learns musical patterns and achieves outstanding performance in generating high-quality coherent pieces and comprehending music. Our code and supplementary material are available at https://github.com/RS2002/PianoBart.
Visual Text Meets Low-level Vision: A Comprehensive Survey on Visual Text Processing
Feb 05, 2024Visual text, a pivotal element in both document and scene images, speaks volumes and attracts significant attention in the computer vision domain. Beyond visual text detection and recognition, the field of visual text processing has experienced a surge in research, driven by the advent of fundamental generative models. However, challenges persist due to the unique properties and features that distinguish text from general objects. Effectively leveraging these unique textual characteristics is crucial in visual text processing, as observed in our study. In this survey, we present a comprehensive, multi-perspective analysis of recent advancements in this field. Initially, we introduce a hierarchical taxonomy encompassing areas ranging from text image enhancement and restoration to text image manipulation, followed by different learning paradigms. Subsequently, we conduct an in-depth discussion of how specific textual features such as structure, stroke, semantics, style, and spatial context are seamlessly integrated into various tasks. Furthermore, we explore available public datasets and benchmark the reviewed methods on several widely-used datasets. Finally, we identify principal challenges and potential avenues for future research. Our aim is to establish this survey as a fundamental resource, fostering continued exploration and innovation in the dynamic area of visual text processing.