 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDynST: Dynamic Sparse Training for Resource-Constrained Spatio-Temporal Forecasting
Mar 05, 2024



The ever-increasing sensor service, though opening a precious path and providing a deluge of earth system data for deep-learning-oriented earth science, sadly introduce a daunting obstacle to their industrial level deployment. Concretely, earth science systems rely heavily on the extensive deployment of sensors, however, the data collection from sensors is constrained by complex geographical and social factors, making it challenging to achieve comprehensive coverage and uniform deployment. To alleviate the obstacle, traditional approaches to sensor deployment utilize specific algorithms to design and deploy sensors. These methods dynamically adjust the activation times of sensors to optimize the detection process across each sub-region. Regrettably, formulating an activation strategy generally based on historical observations and geographic characteristics, which make the methods and resultant models were neither simple nor practical. Worse still, the complex technical design may ultimately lead to a model with weak generalizability. In this paper, we introduce for the first time the concept of spatio-temporal data dynamic sparse training and are committed to adaptively, dynamically filtering important sensor distributions. To our knowledge, this is the first proposal (termed DynST) of an industry-level deployment optimization concept at the data level. However, due to the existence of the temporal dimension, pruning of spatio-temporal data may lead to conflicts at different timestamps. To achieve this goal, we employ dynamic merge technology, along with ingenious dimensional mapping to mitigate potential impacts caused by the temporal aspect. During the training process, DynST utilize iterative pruning and sparse training, repeatedly identifying and dynamically removing sensor perception areas that contribute the least to future predictions.
Deep Learning for Cross-Domain Data Fusion in Urban Computing: Taxonomy, Advances, and Outlook
Feb 29, 2024



As cities continue to burgeon, Urban Computing emerges as a pivotal discipline for sustainable development by harnessing the power of cross-domain data fusion from diverse sources (e.g., geographical, traffic, social media, and environmental data) and modalities (e.g., spatio-temporal, visual, and textual modalities). Recently, we are witnessing a rising trend that utilizes various deep-learning methods to facilitate cross-domain data fusion in smart cities. To this end, we propose the first survey that systematically reviews the latest advancements in deep learning-based data fusion methods tailored for urban computing. Specifically, we first delve into data perspective to comprehend the role of each modality and data source. Secondly, we classify the methodology into four primary categories: feature-based, alignment-based, contrast-based, and generation-based fusion methods. Thirdly, we further categorize multi-modal urban applications into seven types: urban planning, transportation, economy, public safety, society, environment, and energy. Compared with previous surveys, we focus more on the synergy of deep learning methods with urban computing applications. Furthermore, we shed light on the interplay between Large Language Models (LLMs) and urban computing, postulating future research directions that could revolutionize the field. We firmly believe that the taxonomy, progress, and prospects delineated in our survey stand poised to significantly enrich the research community. The summary of the comprehensive and up-to-date paper list can be found at https://github.com/yoshall/Awesome-Multimodal-Urban-Computing.
More Than Routing: Joint GPS and Route Modeling for Refine Trajectory Representation Learning
Feb 25, 2024



Trajectory representation learning plays a pivotal role in supporting various downstream tasks. Traditional methods in order to filter the noise in GPS trajectories tend to focus on routing-based methods used to simplify the trajectories. However, this approach ignores the motion details contained in the GPS data, limiting the representation capability of trajectory representation learning. To fill this gap, we propose a novel representation learning framework that Joint GPS and Route Modelling based on self-supervised technology, namely JGRM. We consider GPS trajectory and route as the two modes of a single movement observation and fuse information through inter-modal information interaction. Specifically, we develop two encoders, each tailored to capture representations of route and GPS trajectories respectively. The representations from the two modalities are fed into a shared transformer for inter-modal information interaction. Eventually, we design three self-supervised tasks to train the model. We validate the effectiveness of the proposed method on two real datasets based on extensive experiments. The experimental results demonstrate that JGRM outperforms existing methods in both road segment representation and trajectory representation tasks. Our source code is available at Anonymous Github.
Artificial Intelligence for Complex Network: Potential, Methodology and Application
Feb 23, 2024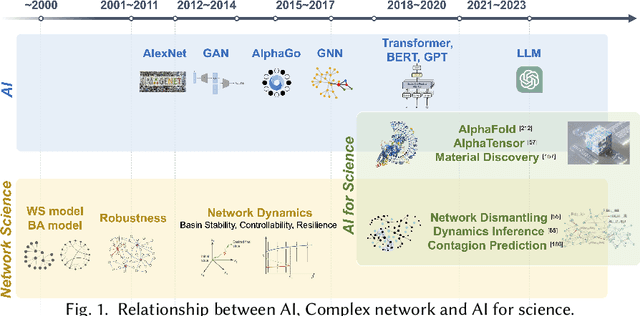
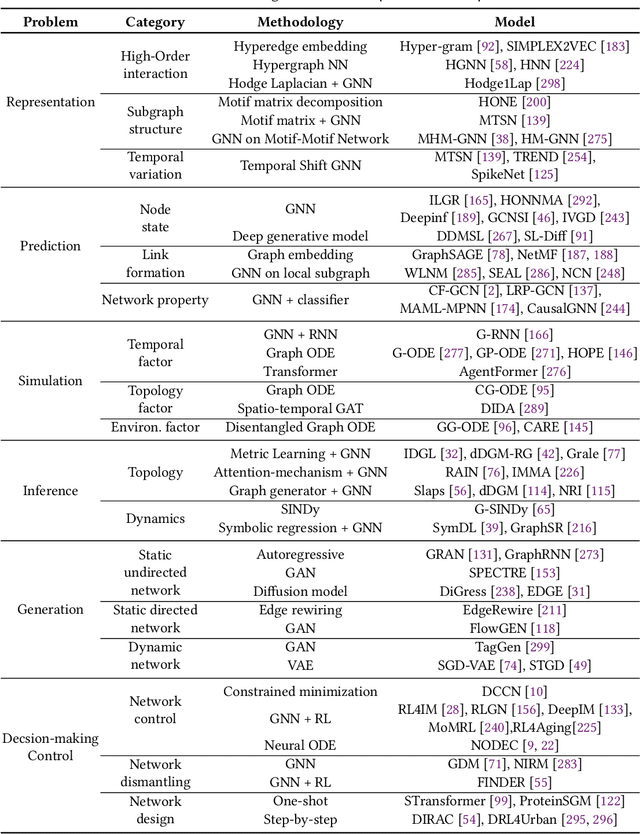
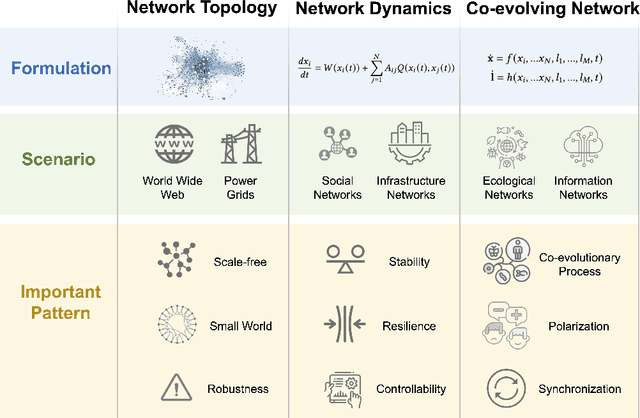
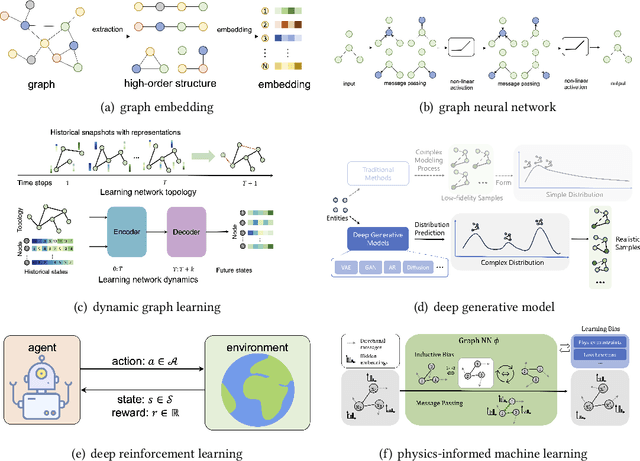
Complex networks pervade various real-world systems, from the natural environment to human societies. The essence of these networks is in their ability to transition and evolve from microscopic disorder-where network topology and node dynamics intertwine-to a macroscopic order characterized by certain collective behaviors. Over the past two decades, complex network science has significantly enhanced our understanding of the statistical mechanics, structures, and dynamics underlying real-world networks. Despite these advancements, there remain considerable challenges in exploring more realistic systems and enhancing practical applications. The emergence of artificial intelligence (AI) technologies, coupled with the abundance of diverse real-world network data, has heralded a new era in complex network science research. This survey aims to systematically address the potential advantages of AI in overcoming the lingering challenges of complex network research. It endeavors to summarize the pivotal research problems and provide an exhaustive review of the corresponding methodologies and applications. Through this comprehensive survey-the first of its kind on AI for complex networks-we expect to provide valuable insights that will drive further research and advancement in this interdisciplinary field.
Graph Spatiotemporal Process for Multivariate Time Series Anomaly Detection with Missing Values
Jan 11, 2024



The detection of anomalies in multivariate time series data is crucial for various practical applications, including smart power grids, traffic flow forecasting, and industrial process control. However, real-world time series data is usually not well-structured, posting significant challenges to existing approaches: (1) The existence of missing values in multivariate time series data along variable and time dimensions hinders the effective modeling of interwoven spatial and temporal dependencies, resulting in important patterns being overlooked during model training; (2) Anomaly scoring with irregularly-sampled observations is less explored, making it difficult to use existing detectors for multivariate series without fully-observed values. In this work, we introduce a novel framework called GST-Pro, which utilizes a graph spatiotemporal process and anomaly scorer to tackle the aforementioned challenges in detecting anomalies on irregularly-sampled multivariate time series. Our approach comprises two main components. First, we propose a graph spatiotemporal process based on neural controlled differential equations. This process enables effective modeling of multivariate time series from both spatial and temporal perspectives, even when the data contains missing values. Second, we present a novel distribution-based anomaly scoring mechanism that alleviates the reliance on complete uniform observations. By analyzing the predictions of the graph spatiotemporal process, our approach allows anomalies to be easily detected. Our experimental results show that the GST-Pro method can effectively detect anomalies in time series data and outperforms state-of-the-art methods, regardless of whether there are missing values present in the data. Our code is available: https://github.com/huankoh/GST-Pro.
FlexSSL : A Generic and Efficient Framework for Semi-Supervised Learning
Dec 28, 2023



Semi-supervised learning holds great promise for many real-world applications, due to its ability to leverage both unlabeled and expensive labeled data. However, most semi-supervised learning algorithms still heavily rely on the limited labeled data to infer and utilize the hidden information from unlabeled data. We note that any semi-supervised learning task under the self-training paradigm also hides an auxiliary task of discriminating label observability. Jointly solving these two tasks allows full utilization of information from both labeled and unlabeled data, thus alleviating the problem of over-reliance on labeled data. This naturally leads to a new generic and efficient learning framework without the reliance on any domain-specific information, which we call FlexSSL. The key idea of FlexSSL is to construct a semi-cooperative "game", which forges cooperation between a main self-interested semi-supervised learning task and a companion task that infers label observability to facilitate main task training. We show with theoretical derivation of its connection to loss re-weighting on noisy labels. Through evaluations on a diverse range of tasks, we demonstrate that FlexSSL can consistently enhance the performance of semi-supervised learning algorithms.
Efficient Large Language Models: A Survey
Dec 23, 2023



Large Language Models (LLMs) have demonstrated remarkable capabilities in important tasks such as natural language understanding, language generation, and complex reasoning and have the potential to make a substantial impact on our society. Such capabilities, however, come with the considerable resources they demand, highlighting the strong need to develop effective techniques for addressing their efficiency challenges. In this survey, we provide a systematic and comprehensive review of efficient LLMs research. We organize the literature in a taxonomy consisting of three main categories, covering distinct yet interconnected efficient LLMs topics from model-centric, data-centric, and framework-centric perspective, respectively. We have also created a GitHub repository where we compile the papers featured in this survey at https://github.com/AIoT-MLSys-Lab/EfficientLLMs, and will actively maintain this repository and incorporate new research as it emerges. We hope our survey can serve as a valuable resource to help researchers and practitioners gain a systematic understanding of the research developments in efficient LLMs and inspire them to contribute to this important and exciting field.
Spherical Frustum Sparse Convolution Network for LiDAR Point Cloud Semantic Segmentation
Nov 29, 2023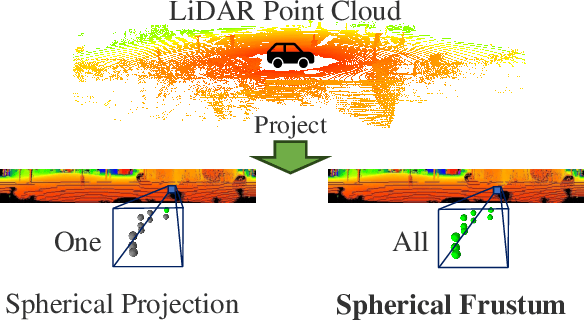
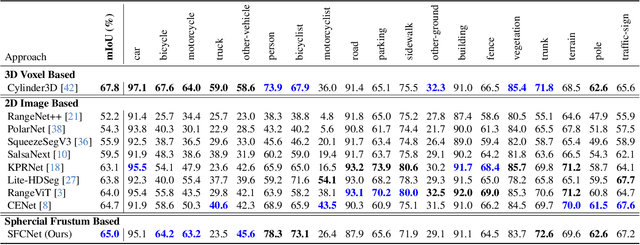
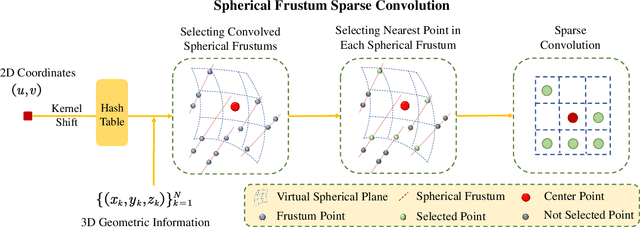
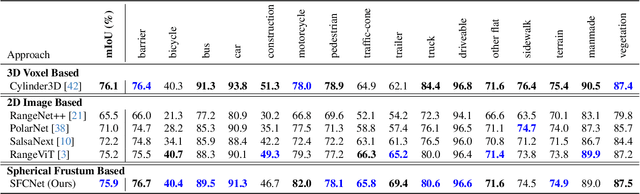
LiDAR point cloud semantic segmentation enables the robots to obtain fine-grained semantic information of the surrounding environment. Recently, many works project the point cloud onto the 2D image and adopt the 2D Convolutional Neural Networks (CNNs) or vision transformer for LiDAR point cloud semantic segmentation. However, since more than one point can be projected onto the same 2D position but only one point can be preserved, the previous 2D image-based segmentation methods suffer from inevitable quantized information loss. To avoid quantized information loss, in this paper, we propose a novel spherical frustum structure. The points projected onto the same 2D position are preserved in the spherical frustums. Moreover, we propose a memory-efficient hash-based representation of spherical frustums. Through the hash-based representation, we propose the Spherical Frustum sparse Convolution (SFC) and Frustum Fast Point Sampling (F2PS) to convolve and sample the points stored in spherical frustums respectively. Finally, we present the Spherical Frustum sparse Convolution Network (SFCNet) to adopt 2D CNNs for LiDAR point cloud semantic segmentation without quantized information loss. Extensive experiments on the SemanticKITTI and nuScenes datasets demonstrate that our SFCNet outperforms the 2D image-based semantic segmentation methods based on conventional spherical projection. The source code will be released later.
Inverse Learning with Extremely Sparse Feedback for Recommendation
Nov 20, 2023



Modern personalized recommendation services often rely on user feedback, either explicit or implicit, to improve the quality of services. Explicit feedback refers to behaviors like ratings, while implicit feedback refers to behaviors like user clicks. However, in the scenario of full-screen video viewing experiences like Tiktok and Reels, the click action is absent, resulting in unclear feedback from users, hence introducing noises in modeling training. Existing approaches on de-noising recommendation mainly focus on positive instances while ignoring the noise in a large amount of sampled negative feedback. In this paper, we propose a meta-learning method to annotate the unlabeled data from loss and gradient perspectives, which considers the noises in both positive and negative instances. Specifically, we first propose an Inverse Dual Loss (IDL) to boost the true label learning and prevent the false label learning. Then we further propose an Inverse Gradient (IG) method to explore the correct updating gradient and adjust the updating based on meta-learning. Finally, we conduct extensive experiments on both benchmark and industrial datasets where our proposed method can significantly improve AUC by 9.25% against state-of-the-art methods. Further analysis verifies the proposed inverse learning framework is model-agnostic and can improve a variety of recommendation backbones. The source code, along with the best hyper-parameter settings, is available at this link: https://github.com/Guanyu-Lin/InverseLearning.
Mixed Attention Network for Cross-domain Sequential Recommendation
Nov 14, 2023



In modern recommender systems, sequential recommendation leverages chronological user behaviors to make effective next-item suggestions, which suffers from data sparsity issues, especially for new users. One promising line of work is the cross-domain recommendation, which trains models with data across multiple domains to improve the performance in data-scarce domains. Recent proposed cross-domain sequential recommendation models such as PiNet and DASL have a common drawback relying heavily on overlapped users in different domains, which limits their usage in practical recommender systems. In this paper, we propose a Mixed Attention Network (MAN) with local and global attention modules to extract the domain-specific and cross-domain information. Firstly, we propose a local/global encoding layer to capture the domain-specific/cross-domain sequential pattern. Then we propose a mixed attention layer with item similarity attention, sequence-fusion attention, and group-prototype attention to capture the local/global item similarity, fuse the local/global item sequence, and extract the user groups across different domains, respectively. Finally, we propose a local/global prediction layer to further evolve and combine the domain-specific and cross-domain interests. Experimental results on two real-world datasets (each with two domains) demonstrate the superiority of our proposed model. Further study also illustrates that our proposed method and components are model-agnostic and effective, respectively. The code and data are available at https://github.com/Guanyu-Lin/MAN.