 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeZipper-LoRA: Dynamic Parameter Decoupling for Speech-LLM based Multilingual Speech Recognition
Mar 19, 2026Speech Large Language Models (Speech-LLMs) have emerged as a powerful approach for automatic speech recognition (ASR) by aligning speech encoders with large language models. However, adapting these systems to multilingual settings with imbalanced data distributions remains challenging. In such scenarios, a stability-plasticity dilemma often arises: fully shared Parameter-Efficient Fine-Tuning (PEFT) can cause negative inter-lingual interference for under-represented languages, while fully language-specific tuning limits the cross-lingual beneficial knowledge transfer needed for low-resource tasks. To address this, we propose Zipper-LoRA, a novel rank-level decoupling framework with three variants (Static, Hard, and Soft) that dynamically synthesizes LoRA updates from shared and language-specific subspaces. By using a lightweight language-conditioned router, Zipper-LoRA dynamically controls the contribution of each subspace at the LoRA rank level, enabling fine-grained sharing where languages are compatible and strict decoupling when conflicts occur. To further stabilize optimization under imbalanced data, we propose a two-stage training strategy with an Initial-B warm start that significantly accelerates convergence. Experiments on a 12-language mixed-resource setting show that Zipper-LoRA consistently outperforms both fully shared and independent baselines, particularly in extremely low-resource scenarios. Moreover, we demonstrate that these gains are robust across both chunked and non-chunked encoder configurations, confirming the framework's reliability for practical, large-scale multilingual ASR. Our code and data will be available at https://github.com/YuCeong-May/Zipper-LoRA for reproducibility.
Enroll-on-Wakeup: A First Comparative Study of Target Speech Extraction for Seamless Interaction in Real Noisy Human-Machine Dialogue Scenarios
Feb 17, 2026Target speech extraction (TSE) typically relies on pre-recorded high-quality enrollment speech, which disrupts user experience and limits feasibility in spontaneous interaction. In this paper, we propose Enroll-on-Wakeup (EoW), a novel framework where the wake-word segment, captured naturally during human-machine interaction, is automatically utilized as the enrollment reference. This eliminates the need for pre-collected speech to enable a seamless experience. We perform the first systematic study of EoW-TSE, evaluating advanced discriminative and generative models under real diverse acoustic conditions. Given the short and noisy nature of wake-word segments, we investigate enrollment augmentation using LLM-based TTS. Results show that while current TSE models face performance degradation in EoW-TSE, TTS-based assistance significantly enhances the listening experience, though gaps remain in speech recognition accuracy.
Bridging the gap: A comparative exploration of Speech-LLM and end-to-end architecture for multilingual conversational ASR
Jan 04, 2026The INTERSPEECH 2025 Challenge on Multilingual Conversational Speech Language Models (MLC-SLM) promotes multilingual conversational ASR with large language models (LLMs). Our previous SHNU-mASR system adopted a competitive parallel-speech-encoder architecture that integrated Whisper and mHuBERT with an LLM. However, it faced two challenges: simple feature concatenation may not fully exploit complementary information, and the performance gap between LLM-based ASR and end-to-end(E2E) encoder-decoder ASR remained unexplored. In this work, we present an enhanced LLM-based ASR framework that combines fine-tuned Whisper and mHuBERT encoders with an LLM to enrich speech representations. We first evaluate E2E Whisper models with LoRA and full fine-tuning on the MLC-SLM ASR task, and then propose cross-attention-based fusion mechanisms for the parallel-speech-encoder. On the official evaluation set of the MLC-SLM Challenge, our system achieves a CER/WER of 10.69%, ranking on par with the top-ranked Track 1 systems, even though it uses only 1,500 hours of baseline training data compared with their large-scale training sets. Nonetheless, we find that our final LLM-based ASR still does not match the performance of a fine-tuned E2E Whisper model, providing valuable empirical guidance for future Speech-LLM design. Our code is publicly available at https://github.com/1535176727/MLC-SLM.
A Language-Agnostic Hierarchical LoRA-MoE Architecture for CTC-based Multilingual ASR
Jan 02, 2026Large-scale multilingual ASR (mASR) models such as Whisper achieve strong performance but incur high computational and latency costs, limiting their deployment on resource-constrained edge devices. In this study, we propose a lightweight and language-agnostic multilingual ASR system based on a CTC architecture with domain adaptation. Specifically, we introduce a Language-agnostic Hierarchical LoRA-MoE (HLoRA) framework integrated into an mHuBERT-CTC model, enabling end-to-end decoding via LID-posterior-driven LoRA routing. The hierarchical design consists of a multilingual shared LoRA for learning language-invariant acoustic representations and language-specific LoRA experts for modeling language-dependent characteristics. The proposed routing mechanism removes the need for prior language identity information or explicit language labels during inference, achieving true language-agnostic decoding. Experiments on MSR-86K and the MLC-SLM 2025 Challenge datasets demonstrate that HLoRA achieves competitive performance with state-of-the-art two-stage inference methods using only single-pass decoding, significantly improving decoding efficiency for low-resource mASR applications.
Lightweight speech enhancement guided target speech extraction in noisy multi-speaker scenarios
Aug 27, 2025



Target speech extraction (TSE) has achieved strong performance in relatively simple conditions such as one-speaker-plus-noise and two-speaker mixtures, but its performance remains unsatisfactory in noisy multi-speaker scenarios. To address this issue, we introduce a lightweight speech enhancement model, GTCRN, to better guide TSE in noisy environments. Building on our competitive previous speaker embedding/encoder-free framework SEF-PNet, we propose two extensions: LGTSE and D-LGTSE. LGTSE incorporates noise-agnostic enrollment guidance by denoising the input noisy speech before context interaction with enrollment speech, thereby reducing noise interference. D-LGTSE further improves system robustness against speech distortion by leveraging denoised speech as an additional noisy input during training, expanding the dynamic range of noisy conditions and enabling the model to directly learn from distorted signals. Furthermore, we propose a two-stage training strategy, first with GTCRN enhancement-guided pre-training and then joint fine-tuning, to fully exploit model potential.Experiments on the Libri2Mix dataset demonstrate significant improvements of 0.89 dB in SISDR, 0.16 in PESQ, and 1.97% in STOI, validating the effectiveness of our approach. Our code is publicly available at https://github.com/isHuangZiling/D-LGTSE.
Unified Architecture and Unsupervised Speech Disentanglement for Speaker Embedding-Free Enrollment in Personalized Speech Enhancement
May 18, 2025



Conventional speech enhancement (SE) aims to improve speech perception and intelligibility by suppressing noise without requiring enrollment speech as reference, whereas personalized SE (PSE) addresses the cocktail party problem by extracting a target speaker's speech using enrollment speech. While these two tasks tackle different yet complementary challenges in speech signal processing, they often share similar model architectures, with PSE incorporating an additional branch to process enrollment speech. This suggests developing a unified model capable of efficiently handling both SE and PSE tasks, thereby simplifying deployment while maintaining high performance. However, PSE performance is sensitive to variations in enrollment speech, like emotional tone, which limits robustness in real-world applications. To address these challenges, we propose two novel models, USEF-PNet and DSEF-PNet, both extending our previous SEF-PNet framework. USEF-PNet introduces a unified architecture for processing enrollment speech, integrating SE and PSE into a single framework to enhance performance and streamline deployment. Meanwhile, DSEF-PNet incorporates an unsupervised speech disentanglement approach by pairing a mixture speech with two different enrollment utterances and enforcing consistency in the extracted target speech. This strategy effectively isolates high-quality speaker identity information from enrollment speech, reducing interference from factors such as emotion and content, thereby improving PSE robustness. Additionally, we explore a long-short enrollment pairing (LSEP) strategy to examine the impact of enrollment speech duration during both training and evaluation. Extensive experiments on the Libri2Mix and VoiceBank DEMAND demonstrate that our proposed USEF-PNet, DSEF-PNet all achieve substantial performance improvements, with random enrollment duration performing slightly better.
Exploring the Potential of SSL Models for Sound Event Detection
May 17, 2025Self-supervised learning (SSL) models offer powerful representations for sound event detection (SED), yet their synergistic potential remains underexplored. This study systematically evaluates state-of-the-art SSL models to guide optimal model selection and integration for SED. We propose a framework that combines heterogeneous SSL representations (e.g., BEATs, HuBERT, WavLM) through three fusion strategies: individual SSL embedding integration, dual-modal fusion, and full aggregation. Experiments on the DCASE 2023 Task 4 Challenge reveal that dual-modal fusion (e.g., CRNN+BEATs+WavLM) achieves complementary performance gains, while CRNN+BEATs alone delivers the best results among individual SSL models. We further introduce normalized sound event bounding boxes (nSEBBs), an adaptive post-processing method that dynamically adjusts event boundary predictions, improving PSDS1 by up to 4% for standalone SSL models. These findings highlight the compatibility and complementarity of SSL architectures, providing guidance for task-specific fusion and robust SED system design.
SEF-PNet: Speaker Encoder-Free Personalized Speech Enhancement with Local and Global Contexts Aggregation
Jan 20, 2025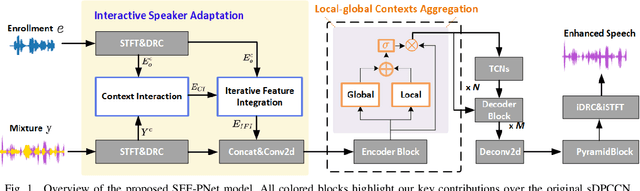
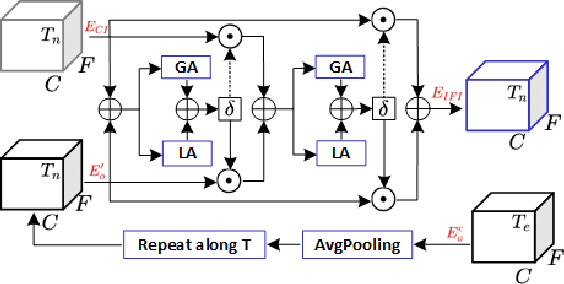
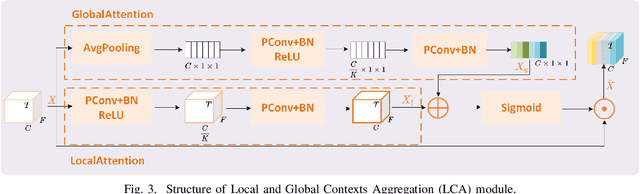
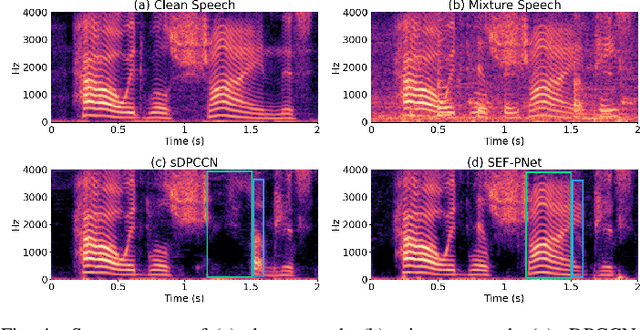
Personalized speech enhancement (PSE) methods typically rely on pre-trained speaker verification models or self-designed speaker encoders to extract target speaker clues, guiding the PSE model in isolating the desired speech. However, these approaches suffer from significant model complexity and often underutilize enrollment speaker information, limiting the potential performance of the PSE model. To address these limitations, we propose a novel Speaker Encoder-Free PSE network, termed SEF-PNet, which fully exploits the information present in both the enrollment speech and noisy mixtures. SEF-PNet incorporates two key innovations: Interactive Speaker Adaptation (ISA) and Local-Global Context Aggregation (LCA). ISA dynamically modulates the interactions between enrollment and noisy signals to enhance the speaker adaptation, while LCA employs advanced channel attention within the PSE encoder to effectively integrate local and global contextual information, thus improving feature learning. Experiments on the Libri2Mix dataset demonstrate that SEF-PNet significantly outperforms baseline models, achieving state-of-the-art PSE performance.
ICSD: An Open-source Dataset for Infant Cry and Snoring Detection
Aug 20, 2024



The detection and analysis of infant cry and snoring events are crucial tasks within the field of audio signal processing. While existing datasets for general sound event detection are plentiful, they often fall short in providing sufficient, strongly labeled data specific to infant cries and snoring. To provide a benchmark dataset and thus foster the research of infant cry and snoring detection, this paper introduces the Infant Cry and Snoring Detection (ICSD) dataset, a novel, publicly available dataset specially designed for ICSD tasks. The ICSD comprises three types of subsets: a real strongly labeled subset with event-based labels annotated manually, a weakly labeled subset with only clip-level event annotations, and a synthetic subset generated and labeled with strong annotations. This paper provides a detailed description of the ICSD creation process, including the challenges encountered and the solutions adopted. We offer a comprehensive characterization of the dataset, discussing its limitations and key factors for ICSD usage. Additionally, we conduct extensive experiments on the ICSD dataset to establish baseline systems and offer insights into the main factors when using this dataset for ICSD research. Our goal is to develop a dataset that will be widely adopted by the community as a new open benchmark for future ICSD research.
Autoencoder with Group-based Decoder and Multi-task Optimization for Anomalous Sound Detection
Nov 15, 2023


In industry, machine anomalous sound detection (ASD) is in great demand. However, collecting enough abnormal samples is difficult due to the high cost, which boosts the rapid development of unsupervised ASD algorithms. Autoencoder (AE) based methods have been widely used for unsupervised ASD, but suffer from problems including 'shortcut', poor anti-noise ability and sub-optimal quality of features. To address these challenges, we propose a new AE-based framework termed AEGM. Specifically, we first insert an auxiliary classifier into AE to enhance ASD in a multi-task learning manner. Then, we design a group-based decoder structure, accompanied by an adaptive loss function, to endow the model with domain-specific knowledge. Results on the DCASE 2021 Task 2 development set show that our methods achieve a relative improvement of 13.11% and 15.20% respectively in average AUC over the official AE and MobileNetV2 across test sets of seven machines.