 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeKnowU-Bench: Towards Interactive, Proactive, and Personalized Mobile Agent Evaluation
Apr 09, 2026Personalized mobile agents that infer user preferences and calibrate proactive assistance hold great promise as everyday digital assistants, yet existing benchmarks fail to capture what this requires. Prior work evaluates preference recovery from static histories or intent prediction from fixed contexts. Neither tests whether an agent can elicit missing preferences through interaction, nor whether it can decide when to intervene, seek consent, or remain silent in a live GUI environment. We introduce KnowU-Bench, an online benchmark for personalized mobile agents built on a reproducible Android emulation environment, covering 42 general GUI tasks, 86 personalized tasks, and 64 proactive tasks. Unlike prior work that treats user preferences as static context, KnowU-Bench hides the user profile from the agent and exposes only behavioral logs, forcing genuine preference inference rather than context lookup. To support multi-turn preference elicitation, it instantiates an LLM-driven user simulator grounded in structured profiles, enabling realistic clarification dialogues and proactive consent handling. Beyond personalization, KnowU-Bench provides comprehensive evaluation of the complete proactive decision chain, including grounded GUI execution, consent negotiation, and post-rejection restraint, evaluated through a hybrid protocol combining rule-based verification with LLM-as-a-Judge scoring. Our experiments reveal a striking degradation: agents that excel at explicit task execution fall below 50% under vague instructions requiring user preference inference or intervention calibration, even for frontier models like Claude Sonnet 4.6. The core bottlenecks are not GUI navigation but preference acquisition and intervention calibration, exposing a fundamental gap between competent interface operation and trustworthy personal assistance.
Towards Real-world Human Behavior Simulation: Benchmarking Large Language Models on Long-horizon, Cross-scenario, Heterogeneous Behavior Traces
Apr 09, 2026The emergence of Large Language Models (LLMs) has illuminated the potential for a general-purpose user simulator. However, existing benchmarks remain constrained to isolated scenarios, narrow action spaces, or synthetic data, failing to capture the holistic nature of authentic human behavior. To bridge this gap, we introduce OmniBehavior, the first user simulation benchmark constructed entirely from real-world data, integrating long-horizon, cross-scenario, and heterogeneous behavioral patterns into a unified framework. Based on this benchmark, we first provide empirical evidence that previous datasets with isolated scenarios suffer from tunnel vision, whereas real-world decision-making relies on long-term, cross-scenario causal chains. Extensive evaluations of state-of-the-art LLMs reveal that current models struggle to accurately simulate these complex behaviors, with performance plateauing even as context windows expand. Crucially, a systematic comparison between simulated and authentic behaviors uncovers a fundamental structural bias: LLMs tend to converge toward a positive average person, exhibiting hyper-activity, persona homogenization, and a Utopian bias. This results in the loss of individual differences and long-tail behaviors, highlighting critical directions for future high-fidelity simulation research.
NimbusGS: Unified 3D Scene Reconstruction under Hybrid Weather
Mar 28, 2026We present NimbusGS, a unified framework for reconstructing high-quality 3D scenes from degraded multi-view inputs captured under diverse and mixed adverse weather conditions. Unlike existing methods that target specific weather types, NimbusGS addresses the broader challenge of generalization by modeling the dual nature of weather: a continuous, view-consistent medium that attenuates light, and dynamic, view-dependent particles that cause scattering and occlusion. To capture this structure, we decompose degradations into a global transmission field and per-view particulate residuals. The transmission field represents static atmospheric effects shared across views, while the residuals model transient disturbances unique to each input. To enable stable geometry learning under severe visibility degradation, we introduce a geometry-guided gradient scaling mechanism that mitigates gradient imbalance during the self-supervised optimization of 3D Gaussian representations. This physically grounded formulation allows NimbusGS to disentangle complex degradations while preserving scene structure, yielding superior geometry reconstruction and outperforming task-specific methods across diverse and challenging weather conditions. Code is available at https://github.com/lyy-ovo/NimbusGS.
OmniVTON++: Training-Free Universal Virtual Try-On with Principal Pose Guidance
Feb 16, 2026Image-based Virtual Try-On (VTON) concerns the synthesis of realistic person imagery through garment re-rendering under human pose and body constraints. In practice, however, existing approaches are typically optimized for specific data conditions, making their deployment reliant on retraining and limiting their generalization as a unified solution. We present OmniVTON++, a training-free VTON framework designed for universal applicability. It addresses the intertwined challenges of garment alignment, human structural coherence, and boundary continuity by coordinating Structured Garment Morphing for correspondence-driven garment adaptation, Principal Pose Guidance for step-wise structural regulation during diffusion sampling, and Continuous Boundary Stitching for boundary-aware refinement, forming a cohesive pipeline without task-specific retraining. Experimental results demonstrate that OmniVTON++ achieves state-of-the-art performance across diverse generalization settings, including cross-dataset and cross-garment-type evaluations, while reliably operating across scenarios and diffusion backbones within a single formulation. In addition to single-garment, single-human cases, the framework supports multi-garment, multi-human, and anime character virtual try-on, expanding the scope of virtual try-on applications. The source code will be released to the public.
MotionAdapter: Video Motion Transfer via Content-Aware Attention Customization
Jan 05, 2026Recent advances in diffusion-based text-to-video models, particularly those built on the diffusion transformer architecture, have achieved remarkable progress in generating high-quality and temporally coherent videos. However, transferring complex motions between videos remains challenging. In this work, we present MotionAdapter, a content-aware motion transfer framework that enables robust and semantically aligned motion transfer within DiT-based T2V models. Our key insight is that effective motion transfer requires \romannumeral1) explicit disentanglement of motion from appearance and \romannumeral 2) adaptive customization of motion to target content. MotionAdapter first isolates motion by analyzing cross-frame attention within 3D full-attention modules to extract attention-derived motion fields. To bridge the semantic gap between reference and target videos, we further introduce a DINO-guided motion customization module that rearranges and refines motion fields based on content correspondences. The customized motion field is then used to guide the DiT denoising process, ensuring that the synthesized video inherits the reference motion while preserving target appearance and semantics. Extensive experiments demonstrate that MotionAdapter outperforms state-of-the-art methods in both qualitative and quantitative evaluations. Moreover, MotionAdapter naturally supports complex motion transfer and motion editing tasks such as zooming.
AvatarVTON: 4D Virtual Try-On for Animatable Avatars
Oct 06, 2025We propose AvatarVTON, the first 4D virtual try-on framework that generates realistic try-on results from a single in-shop garment image, enabling free pose control, novel-view rendering, and diverse garment choices. Unlike existing methods, AvatarVTON supports dynamic garment interactions under single-view supervision, without relying on multi-view garment captures or physics priors. The framework consists of two key modules: (1) a Reciprocal Flow Rectifier, a prior-free optical-flow correction strategy that stabilizes avatar fitting and ensures temporal coherence; and (2) a Non-Linear Deformer, which decomposes Gaussian maps into view-pose-invariant and view-pose-specific components, enabling adaptive, non-linear garment deformations. To establish a benchmark for 4D virtual try-on, we extend existing baselines with unified modules for fair qualitative and quantitative comparisons. Extensive experiments show that AvatarVTON achieves high fidelity, diversity, and dynamic garment realism, making it well-suited for AR/VR, gaming, and digital-human applications.
Test-Time Reinforcement Learning for GUI Grounding via Region Consistency
Aug 07, 2025Graphical User Interface (GUI) grounding, the task of mapping natural language instructions to precise screen coordinates, is fundamental to autonomous GUI agents. While existing methods achieve strong performance through extensive supervised training or reinforcement learning with labeled rewards, they remain constrained by the cost and availability of pixel-level annotations. We observe that when models generate multiple predictions for the same GUI element, the spatial overlap patterns reveal implicit confidence signals that can guide more accurate localization. Leveraging this insight, we propose GUI-RC (Region Consistency), a test-time scaling method that constructs spatial voting grids from multiple sampled predictions to identify consensus regions where models show highest agreement. Without any training, GUI-RC improves accuracy by 2-3% across various architectures on ScreenSpot benchmarks. We further introduce GUI-RCPO (Region Consistency Policy Optimization), which transforms these consistency patterns into rewards for test-time reinforcement learning. By computing how well each prediction aligns with the collective consensus, GUI-RCPO enables models to iteratively refine their outputs on unlabeled data during inference. Extensive experiments demonstrate the generality of our approach: GUI-RC boosts Qwen2.5-VL-3B-Instruct from 80.11% to 83.57% on ScreenSpot-v2, while GUI-RCPO further improves it to 85.14% through self-supervised optimization. Our approach reveals the untapped potential of test-time scaling and test-time reinforcement learning for GUI grounding, offering a promising path toward more robust and data-efficient GUI agents.
HarmonPaint: Harmonized Training-Free Diffusion Inpainting
Jul 22, 2025Existing inpainting methods often require extensive retraining or fine-tuning to integrate new content seamlessly, yet they struggle to maintain coherence in both structure and style between inpainted regions and the surrounding background. Motivated by these limitations, we introduce HarmonPaint, a training-free inpainting framework that seamlessly integrates with the attention mechanisms of diffusion models to achieve high-quality, harmonized image inpainting without any form of training. By leveraging masking strategies within self-attention, HarmonPaint ensures structural fidelity without model retraining or fine-tuning. Additionally, we exploit intrinsic diffusion model properties to transfer style information from unmasked to masked regions, achieving a harmonious integration of styles. Extensive experiments demonstrate the effectiveness of HarmonPaint across diverse scenes and styles, validating its versatility and performance.
Beyond the LUMIR challenge: The pathway to foundational registration models
May 30, 2025



Medical image challenges have played a transformative role in advancing the field, catalyzing algorithmic innovation and establishing new performance standards across diverse clinical applications. Image registration, a foundational task in neuroimaging pipelines, has similarly benefited from the Learn2Reg initiative. Building on this foundation, we introduce the Large-scale Unsupervised Brain MRI Image Registration (LUMIR) challenge, a next-generation benchmark designed to assess and advance unsupervised brain MRI registration. Distinct from prior challenges that leveraged anatomical label maps for supervision, LUMIR removes this dependency by providing over 4,000 preprocessed T1-weighted brain MRIs for training without any label maps, encouraging biologically plausible deformation modeling through self-supervision. In addition to evaluating performance on 590 held-out test subjects, LUMIR introduces a rigorous suite of zero-shot generalization tasks, spanning out-of-domain imaging modalities (e.g., FLAIR, T2-weighted, T2*-weighted), disease populations (e.g., Alzheimer's disease), acquisition protocols (e.g., 9.4T MRI), and species (e.g., macaque brains). A total of 1,158 subjects and over 4,000 image pairs were included for evaluation. Performance was assessed using both segmentation-based metrics (Dice coefficient, 95th percentile Hausdorff distance) and landmark-based registration accuracy (target registration error). Across both in-domain and zero-shot tasks, deep learning-based methods consistently achieved state-of-the-art accuracy while producing anatomically plausible deformation fields. The top-performing deep learning-based models demonstrated diffeomorphic properties and inverse consistency, outperforming several leading optimization-based methods, and showing strong robustness to most domain shifts, the exception being a drop in performance on out-of-domain contrasts.
Deep learning-derived arterial input function
May 30, 2025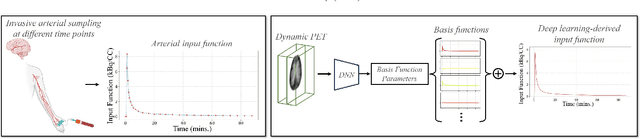

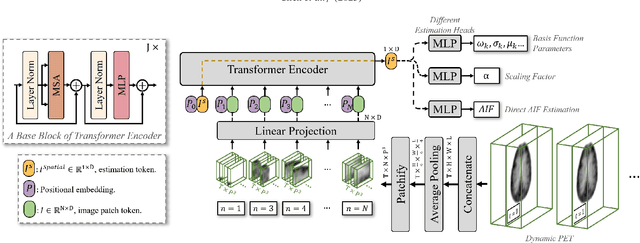
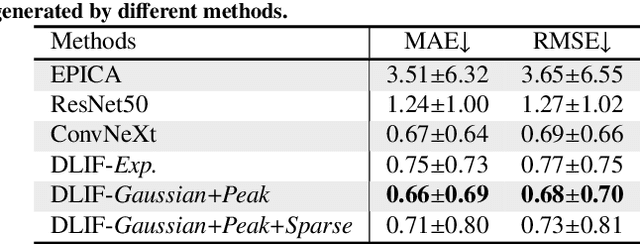
Dynamic positron emission tomography (PET) imaging combined with radiotracer kinetic modeling is a powerful technique for visualizing biological processes in the brain, offering valuable insights into brain functions and neurological disorders such as Alzheimer's and Parkinson's diseases. Accurate kinetic modeling relies heavily on the use of a metabolite-corrected arterial input function (AIF), which typically requires invasive and labor-intensive arterial blood sampling. While alternative non-invasive approaches have been proposed, they often compromise accuracy or still necessitate at least one invasive blood sampling. In this study, we present the deep learning-derived arterial input function (DLIF), a deep learning framework capable of estimating a metabolite-corrected AIF directly from dynamic PET image sequences without any blood sampling. We validated DLIF using existing dynamic PET patient data. We compared DLIF and resulting parametric maps against ground truth measurements. Our evaluation shows that DLIF achieves accurate and robust AIF estimation. By leveraging deep learning's ability to capture complex temporal dynamics and incorporating prior knowledge of typical AIF shapes through basis functions, DLIF provides a rapid, accurate, and entirely non-invasive alternative to traditional AIF measurement methods.