 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDual-branch Spatial-Temporal Self-supervised Representation for Enhanced Road Network Learning
Nov 10, 2025



Road network representation learning (RNRL) has attracted increasing attention from both researchers and practitioners as various spatiotemporal tasks are emerging. Recent advanced methods leverage Graph Neural Networks (GNNs) and contrastive learning to characterize the spatial structure of road segments in a self-supervised paradigm. However, spatial heterogeneity and temporal dynamics of road networks raise severe challenges to the neighborhood smoothing mechanism of self-supervised GNNs. To address these issues, we propose a $\textbf{D}$ual-branch $\textbf{S}$patial-$\textbf{T}$emporal self-supervised representation framework for enhanced road representations, termed as DST. On one hand, DST designs a mix-hop transition matrix for graph convolution to incorporate dynamic relations of roads from trajectories. Besides, DST contrasts road representations of the vanilla road network against that of the hypergraph in a spatial self-supervised way. The hypergraph is newly built based on three types of hyperedges to capture long-range relations. On the other hand, DST performs next token prediction as the temporal self-supervised task on the sequences of traffic dynamics based on a causal Transformer, which is further regularized by differentiating traffic modes of weekdays from those of weekends. Extensive experiments against state-of-the-art methods verify the superiority of our proposed framework. Moreover, the comprehensive spatiotemporal modeling facilitates DST to excel in zero-shot learning scenarios.
Selecting Auxiliary Data via Neural Tangent Kernels for Low-Resource Domains
Nov 10, 2025Large language models (LLMs) have achieved remarkable success across widespread tasks, yet their application in low-resource domains remains a significant challenge due to data scarcity and the high risk of overfitting. While in-domain data is limited, there exist vast amounts of similar general-domain data, and our initial findings reveal that they could potentially serve as auxiliary supervision for domain enhancement. This observation leads us to our central research question: \textbf{\textit{how to effectively select the most valuable auxiliary data to maximize domain-specific performance}}, particularly when traditional methods are inapplicable due to a lack of large in-domain data pools or validation sets. To address this, we propose \textbf{NTK-Selector}, a principled and efficient framework for selecting general-domain auxiliary data to enhance domain-specific performance via neural tangent kernels (NTK). Our method tackles two challenges of directly applying NTK to LLMs, theoretical assumptions and prohibitive computational cost, by empirically demonstrating a stable NTK-like behavior in LLMs during LoRA fine-tuning and proposing a Jacobian-free approximation method. Extensive experiments across four low-resource domains (medical, financial, legal, and psychological) demonstrate that NTK-Selector consistently improves downstream performance. Specifically, fine-tuning on 1,000 in-domain samples alone only yielded +0.8 points for Llama3-8B-Instruct and +0.9 points for Qwen3-8B. In contrast, enriching with 9,000 auxiliary samples selected by NTK-Selector led to substantial \textbf{gains of +8.7 and +5.1 points}, which corresponds to a \textbf{10.9x and 5.7x improvement} over the domain-only setting.
Identifying the Periodicity of Information in Natural Language
Oct 31, 2025Recent theoretical advancement of information density in natural language has brought the following question on desk: To what degree does natural language exhibit periodicity pattern in its encoded information? We address this question by introducing a new method called AutoPeriod of Surprisal (APS). APS adopts a canonical periodicity detection algorithm and is able to identify any significant periods that exist in the surprisal sequence of a single document. By applying the algorithm to a set of corpora, we have obtained the following interesting results: Firstly, a considerable proportion of human language demonstrates a strong pattern of periodicity in information; Secondly, new periods that are outside the distributions of typical structural units in text (e.g., sentence boundaries, elementary discourse units, etc.) are found and further confirmed via harmonic regression modeling. We conclude that the periodicity of information in language is a joint outcome from both structured factors and other driving factors that take effect at longer distances. The advantages of our periodicity detection method and its potentials in LLM-generation detection are further discussed.
How Close Are We? Limitations and Progress of AI Models in Banff Lesion Scoring
Oct 31, 2025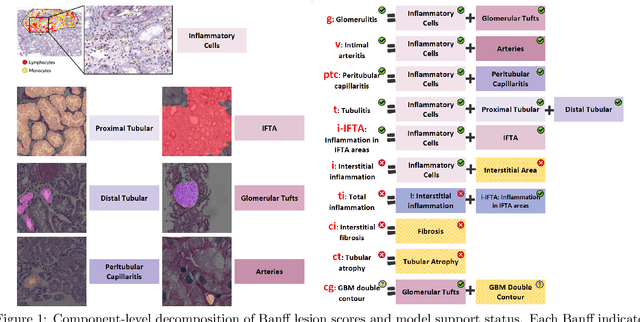
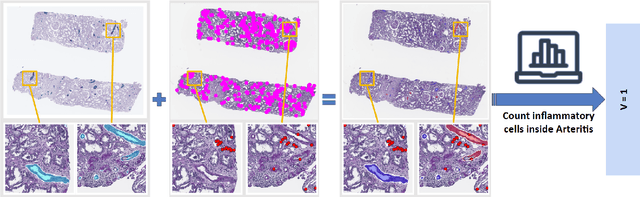
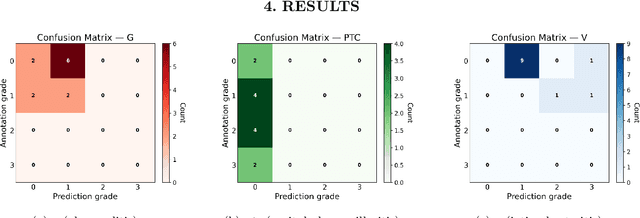
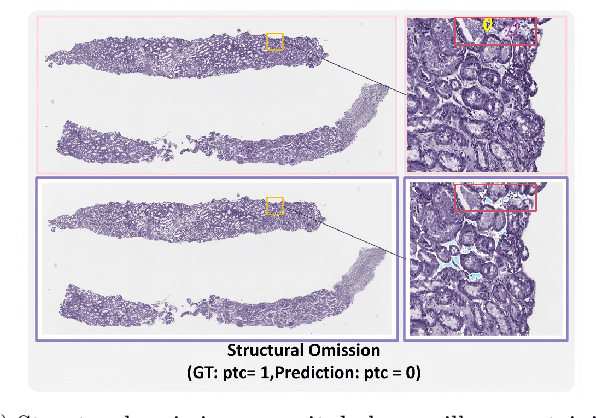
The Banff Classification provides the global standard for evaluating renal transplant biopsies, yet its semi-quantitative nature, complex criteria, and inter-observer variability present significant challenges for computational replication. In this study, we explore the feasibility of approximating Banff lesion scores using existing deep learning models through a modular, rule-based framework. We decompose each Banff indicator - such as glomerulitis (g), peritubular capillaritis (ptc), and intimal arteritis (v) - into its constituent structural and inflammatory components, and assess whether current segmentation and detection tools can support their computation. Model outputs are mapped to Banff scores using heuristic rules aligned with expert guidelines, and evaluated against expert-annotated ground truths. Our findings highlight both partial successes and critical failure modes, including structural omission, hallucination, and detection ambiguity. Even when final scores match expert annotations, inconsistencies in intermediate representations often undermine interpretability. These results reveal the limitations of current AI pipelines in replicating computational expert-level grading, and emphasize the importance of modular evaluation and computational Banff grading standard in guiding future model development for transplant pathology.
$π_\texttt{RL}$: Online RL Fine-tuning for Flow-based Vision-Language-Action Models
Oct 29, 2025


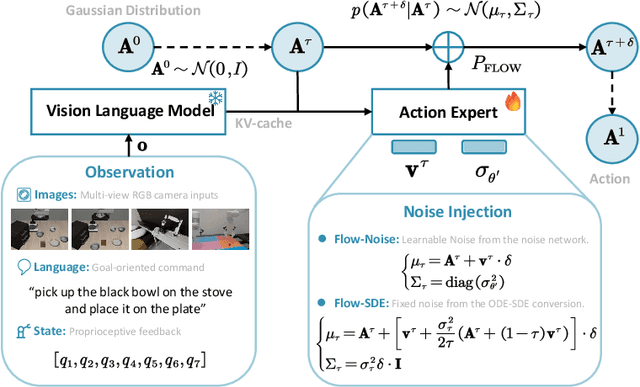
Vision-Language-Action (VLA) models enable robots to understand and perform complex tasks from multimodal input. Although recent work explores using reinforcement learning (RL) to automate the laborious data collection process in scaling supervised fine-tuning (SFT), applying large-scale RL to flow-based VLAs (e.g., $\pi_0$, $\pi_{0.5}$) remains challenging due to intractable action log-likelihoods from iterative denoising. We address this challenge with $\pi_{\text{RL}}$, an open-source framework for training flow-based VLAs in parallel simulation. $\pi_{\text{RL}}$ implements two RL algorithms: (1) {Flow-Noise} models the denoising process as a discrete-time MDP with a learnable noise network for exact log-likelihood computation. (2) {Flow-SDE} integrates denoising with agent-environment interaction, formulating a two-layer MDP that employs ODE-to-SDE conversion for efficient RL exploration. We evaluate $\pi_{\text{RL}}$ on LIBERO and ManiSkill benchmarks. On LIBERO, $\pi_{\text{RL}}$ boosts few-shot SFT models $\pi_0$ and $\pi_{0.5}$ from 57.6% to 97.6% and from 77.1% to 98.3%, respectively. In ManiSkill, we train $\pi_{\text{RL}}$ in 320 parallel environments, improving $\pi_0$ from 41.6% to 85.7% and $\pi_{0.5}$ from 40.0% to 84.8% across 4352 pick-and-place tasks, demonstrating scalable multitask RL under heterogeneous simulation. Overall, $\pi_{\text{RL}}$ achieves significant performance gains and stronger generalization over SFT-models, validating the effectiveness of online RL for flow-based VLAs.
On the Ability of LLMs to Handle Character-Level Perturbations: How Well and How?
Oct 16, 2025This work investigates the resilience of contemporary LLMs against frequent and structured character-level perturbations, specifically through the insertion of noisy characters after each input character. We introduce \nameshort{}, a practical method that inserts invisible Unicode control characters into text to discourage LLM misuse in scenarios such as online exam systems. Surprisingly, despite strong obfuscation that fragments tokenization and reduces the signal-to-noise ratio significantly, many LLMs still maintain notable performance. Through comprehensive evaluation across model-, problem-, and noise-related configurations, we examine the extent and mechanisms of this robustness, exploring both the handling of character-level tokenization and \textit{implicit} versus \textit{explicit} denoising mechanism hypotheses of character-level noises. We hope our findings on the low-level robustness of LLMs will shed light on the risks of their misuse and on the reliability of deploying LLMs across diverse applications.
Hierarchical Indexing with Knowledge Enrichment for Multilingual Video Corpus Retrieval
Oct 10, 2025Retrieving relevant instructional videos from multilingual medical archives is crucial for answering complex, multi-hop questions across language boundaries. However, existing systems either compress hour-long videos into coarse embeddings or incur prohibitive costs for fine-grained matching. We tackle the Multilingual Video Corpus Retrieval (mVCR) task in the NLPCC-2025 M4IVQA challenge with a multi-stage framework that integrates multilingual semantics, domain terminology, and efficient long-form processing. Video subtitles are divided into semantically coherent chunks, enriched with concise knowledge-graph (KG) facts, and organized into a hierarchical tree whose node embeddings are generated by a language-agnostic multilingual encoder. At query time, the same encoder embeds the input question; a coarse-to-fine tree search prunes irrelevant branches, and only the top-ranked chunks are re-scored by a lightweight large language model (LLM). This design avoids exhaustive cross-encoder scoring while preserving chunk-level precision. Experiments on the mVCR test set demonstrate state-of-the-art performance, and ablation studies confirm the complementary contributions of KG enrichment, hierarchical indexing, and targeted LLM re-ranking. The proposed method offers an accurate and scalable solution for multilingual retrieval in specialized medical video collections.
CS3-Bench: Evaluating and Enhancing Speech-to-Speech LLMs for Mandarin-English Code-Switching
Oct 09, 2025

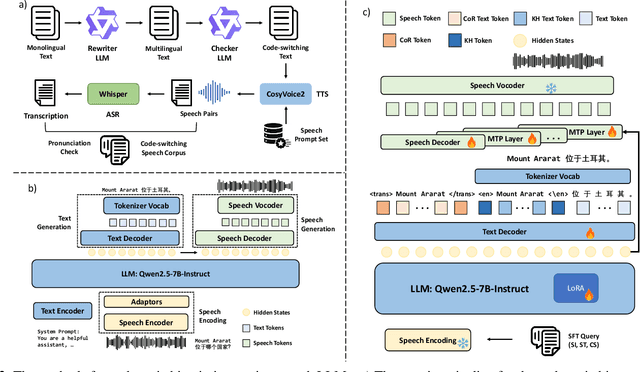
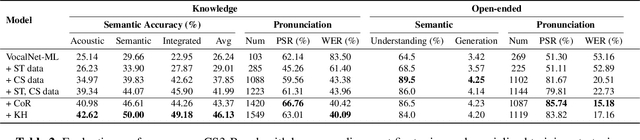
The advancement of multimodal large language models has accelerated the development of speech-to-speech interaction systems. While natural monolingual interaction has been achieved, we find existing models exhibit deficiencies in language alignment. In our proposed Code-Switching Speech-to-Speech Benchmark (CS3-Bench), experiments on 7 mainstream models demonstrate a relative performance drop of up to 66% in knowledge-intensive question answering and varying degrees of misunderstanding in open-ended conversations. Starting from a model with severe performance deterioration, we propose both data constructions and training approaches to improve the language alignment capabilities, specifically employing Chain of Recognition (CoR) to enhance understanding and Keyword Highlighting (KH) to guide generation. Our approach improves the knowledge accuracy from 25.14% to 46.13%, with open-ended understanding rate from 64.5% to 86.5%, and significantly reduces pronunciation errors in the secondary language. CS3-Bench is available at https://huggingface.co/datasets/VocalNet/CS3-Bench.
A Clinical-grade Universal Foundation Model for Intraoperative Pathology
Oct 06, 2025Intraoperative pathology is pivotal to precision surgery, yet its clinical impact is constrained by diagnostic complexity and the limited availability of high-quality frozen-section data. While computational pathology has made significant strides, the lack of large-scale, prospective validation has impeded its routine adoption in surgical workflows. Here, we introduce CRISP, a clinical-grade foundation model developed on over 100,000 frozen sections from eight medical centers, specifically designed to provide Clinical-grade Robust Intraoperative Support for Pathology (CRISP). CRISP was comprehensively evaluated on more than 15,000 intraoperative slides across nearly 100 retrospective diagnostic tasks, including benign-malignant discrimination, key intraoperative decision-making, and pan-cancer detection, etc. The model demonstrated robust generalization across diverse institutions, tumor types, and anatomical sites-including previously unseen sites and rare cancers. In a prospective cohort of over 2,000 patients, CRISP sustained high diagnostic accuracy under real-world conditions, directly informing surgical decisions in 92.6% of cases. Human-AI collaboration further reduced diagnostic workload by 35%, avoided 105 ancillary tests and enhanced detection of micrometastases with 87.5% accuracy. Together, these findings position CRISP as a clinical-grade paradigm for AI-driven intraoperative pathology, bridging computational advances with surgical precision and accelerating the translation of artificial intelligence into routine clinical practice.
Towards Better Optimization For Listwise Preference in Diffusion Models
Oct 02, 2025



Reinforcement learning from human feedback (RLHF) has proven effectiveness for aligning text-to-image (T2I) diffusion models with human preferences. Although Direct Preference Optimization (DPO) is widely adopted for its computational efficiency and avoidance of explicit reward modeling, its applications to diffusion models have primarily relied on pairwise preferences. The precise optimization of listwise preferences remains largely unaddressed. In practice, human feedback on image preferences often contains implicit ranked information, which conveys more precise human preferences than pairwise comparisons. In this work, we propose Diffusion-LPO, a simple and effective framework for Listwise Preference Optimization in diffusion models with listwise data. Given a caption, we aggregate user feedback into a ranked list of images and derive a listwise extension of the DPO objective under the Plackett-Luce model. Diffusion-LPO enforces consistency across the entire ranking by encouraging each sample to be preferred over all of its lower-ranked alternatives. We empirically demonstrate the effectiveness of Diffusion-LPO across various tasks, including text-to-image generation, image editing, and personalized preference alignment. Diffusion-LPO consistently outperforms pairwise DPO baselines on visual quality and preference alignment.