 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCS3-Bench: Evaluating and Enhancing Speech-to-Speech LLMs for Mandarin-English Code-Switching
Paper and Code
Oct 09, 2025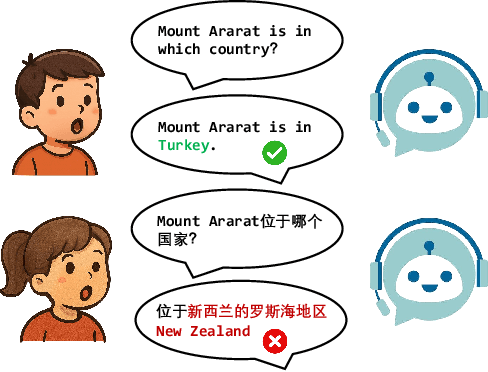

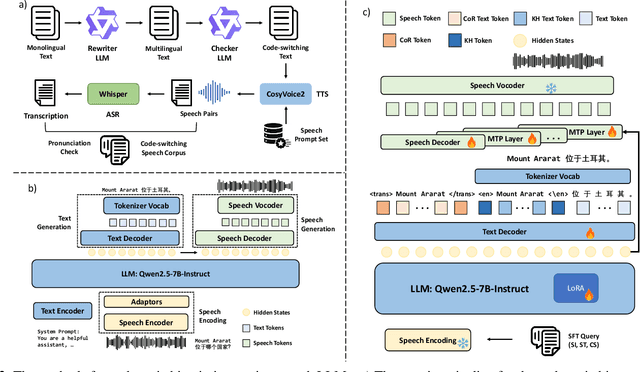
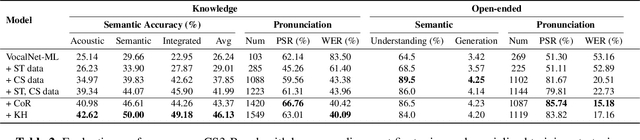
The advancement of multimodal large language models has accelerated the development of speech-to-speech interaction systems. While natural monolingual interaction has been achieved, we find existing models exhibit deficiencies in language alignment. In our proposed Code-Switching Speech-to-Speech Benchmark (CS3-Bench), experiments on 7 mainstream models demonstrate a relative performance drop of up to 66% in knowledge-intensive question answering and varying degrees of misunderstanding in open-ended conversations. Starting from a model with severe performance deterioration, we propose both data constructions and training approaches to improve the language alignment capabilities, specifically employing Chain of Recognition (CoR) to enhance understanding and Keyword Highlighting (KH) to guide generation. Our approach improves the knowledge accuracy from 25.14% to 46.13%, with open-ended understanding rate from 64.5% to 86.5%, and significantly reduces pronunciation errors in the secondary language. CS3-Bench is available at https://huggingface.co/datasets/VocalNet/CS3-Bench.