 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBuilding Interactable Replicas of Complex Articulated Objects via Gaussian Splatting
Feb 26, 2025Building articulated objects is a key challenge in computer vision. Existing methods often fail to effectively integrate information across different object states, limiting the accuracy of part-mesh reconstruction and part dynamics modeling, particularly for complex multi-part articulated objects. We introduce ArtGS, a novel approach that leverages 3D Gaussians as a flexible and efficient representation to address these issues. Our method incorporates canonical Gaussians with coarse-to-fine initialization and updates for aligning articulated part information across different object states, and employs a skinning-inspired part dynamics modeling module to improve both part-mesh reconstruction and articulation learning. Extensive experiments on both synthetic and real-world datasets, including a new benchmark for complex multi-part objects, demonstrate that ArtGS achieves state-of-the-art performance in joint parameter estimation and part mesh reconstruction. Our approach significantly improves reconstruction quality and efficiency, especially for multi-part articulated objects. Additionally, we provide comprehensive analyses of our design choices, validating the effectiveness of each component to highlight potential areas for future improvement.
Rewards-based image analysis in microscopy
Feb 23, 2025



Analyzing imaging and hyperspectral data is crucial across scientific fields, including biology, medicine, chemistry, and physics. The primary goal is to transform high-resolution or high-dimensional data into an interpretable format to generate actionable insights, aiding decision-making and advancing knowledge. Currently, this task relies on complex, human-designed workflows comprising iterative steps such as denoising, spatial sampling, keypoint detection, feature generation, clustering, dimensionality reduction, and physics-based deconvolutions. The introduction of machine learning over the past decade has accelerated tasks like image segmentation and object detection via supervised learning, and dimensionality reduction via unsupervised methods. However, both classical and NN-based approaches still require human input, whether for hyperparameter tuning, data labeling, or both. The growing use of automated imaging tools, from atomically resolved imaging to biological applications, demands unsupervised methods that optimize data representation for human decision-making or autonomous experimentation. Here, we discuss advances in reward-based workflows, which adopt expert decision-making principles and demonstrate strong transfer learning across diverse tasks. We represent image analysis as a decision-making process over possible operations and identify desiderata and their mappings to classical decision-making frameworks. Reward-driven workflows enable a shift from supervised, black-box models sensitive to distribution shifts to explainable, unsupervised, and robust optimization in image analysis. They can function as wrappers over classical and DCNN-based methods, making them applicable to both unsupervised and supervised workflows (e.g., classification, regression for structure-property mapping) across imaging and hyperspectral data.
MapFusion: A Novel BEV Feature Fusion Network for Multi-modal Map Construction
Feb 05, 2025Map construction task plays a vital role in providing precise and comprehensive static environmental information essential for autonomous driving systems. Primary sensors include cameras and LiDAR, with configurations varying between camera-only, LiDAR-only, or camera-LiDAR fusion, based on cost-performance considerations. While fusion-based methods typically perform best, existing approaches often neglect modality interaction and rely on simple fusion strategies, which suffer from the problems of misalignment and information loss. To address these issues, we propose MapFusion, a novel multi-modal Bird's-Eye View (BEV) feature fusion method for map construction. Specifically, to solve the semantic misalignment problem between camera and LiDAR BEV features, we introduce the Cross-modal Interaction Transform (CIT) module, enabling interaction between two BEV feature spaces and enhancing feature representation through a self-attention mechanism. Additionally, we propose an effective Dual Dynamic Fusion (DDF) module to adaptively select valuable information from different modalities, which can take full advantage of the inherent information between different modalities. Moreover, MapFusion is designed to be simple and plug-and-play, easily integrated into existing pipelines. We evaluate MapFusion on two map construction tasks, including High-definition (HD) map and BEV map segmentation, to show its versatility and effectiveness. Compared with the state-of-the-art methods, MapFusion achieves 3.6% and 6.2% absolute improvements on the HD map construction and BEV map segmentation tasks on the nuScenes dataset, respectively, demonstrating the superiority of our approach.
Learning to Learn Weight Generation via Trajectory Diffusion
Feb 03, 2025



Diffusion-based algorithms have emerged as promising techniques for weight generation, particularly in scenarios like multi-task learning that require frequent weight updates. However, existing solutions suffer from limited cross-task transferability. In addition, they only utilize optimal weights as training samples, ignoring the value of other weights in the optimization process. To address these issues, we propose Lt-Di, which integrates the diffusion algorithm with meta-learning to generate weights for unseen tasks. Furthermore, we extend the vanilla diffusion algorithm into a trajectory diffusion algorithm to utilize other weights along the optimization trajectory. Trajectory diffusion decomposes the entire diffusion chain into multiple shorter ones, improving training and inference efficiency. We analyze the convergence properties of the weight generation paradigm and improve convergence efficiency without additional time overhead. Our experiments demonstrate Lt-Di's higher accuracy while reducing computational overhead across various tasks, including zero-shot and few-shot learning, multi-domain generalization, and large-scale language model fine-tuning.Our code is released at https://github.com/tuantuange/Lt-Di.
RegionGCN: Spatial-Heterogeneity-Aware Graph Convolutional Networks
Jan 29, 2025



Modeling spatial heterogeneity in the data generation process is essential for understanding and predicting geographical phenomena. Despite their prevalence in geospatial tasks, neural network models usually assume spatial stationarity, which could limit their performance in the presence of spatial process heterogeneity. By allowing model parameters to vary over space, several approaches have been proposed to incorporate spatial heterogeneity into neural networks. However, current geographically weighting approaches are ineffective on graph neural networks, yielding no significant improvement in prediction accuracy. We assume the crux lies in the over-fitting risk brought by a large number of local parameters. Accordingly, we propose to model spatial process heterogeneity at the regional level rather than at the individual level, which largely reduces the number of spatially varying parameters. We further develop a heuristic optimization procedure to learn the region partition adaptively in the process of model training. Our proposed spatial-heterogeneity-aware graph convolutional network, named RegionGCN, is applied to the spatial prediction of county-level vote share in the 2016 US presidential election based on socioeconomic attributes. Results show that RegionGCN achieves significant improvement over the basic and geographically weighted GCNs. We also offer an exploratory analysis tool for the spatial variation of non-linear relationships through ensemble learning of regional partitions from RegionGCN. Our work contributes to the practice of Geospatial Artificial Intelligence (GeoAI) in tackling spatial heterogeneity.
TranStable: Towards Robust Pixel-level Online Video Stabilization by Jointing Transformer and CNN
Jan 25, 2025Video stabilization often struggles with distortion and excessive cropping. This paper proposes a novel end-to-end framework, named TranStable, to address these challenges, comprising a genera tor and a discriminator. We establish TransformerUNet (TUNet) as the generator to utilize the Hierarchical Adaptive Fusion Module (HAFM), integrating Transformer and CNN to leverage both global and local features across multiple visual cues. By modeling frame-wise relationships, it generates robust pixel-level warping maps for stable geometric transformations. Furthermore, we design the Stability Discriminator Module (SDM), which provides pixel-wise supervision for authenticity and consistency in training period, ensuring more complete field-of-view while minimizing jitter artifacts and enhancing visual fidelity. Extensive experiments on NUS, DeepStab, and Selfie benchmarks demonstrate state-of-the-art performance.
DiffDoctor: Diagnosing Image Diffusion Models Before Treating
Jan 21, 2025



In spite of the recent progress, image diffusion models still produce artifacts. A common solution is to refine an established model with a quality assessment system, which generally rates an image in its entirety. In this work, we believe problem-solving starts with identification, yielding the request that the model should be aware of not just the presence of defects in an image, but their specific locations. Motivated by this, we propose DiffDoctor, a two-stage pipeline to assist image diffusion models in generating fewer artifacts. Concretely, the first stage targets developing a robust artifact detector, for which we collect a dataset of over 1M flawed synthesized images and set up an efficient human-in-the-loop annotation process, incorporating a carefully designed class-balance strategy. The learned artifact detector is then involved in the second stage to tune the diffusion model through assigning a per-pixel confidence map for each synthesis. Extensive experiments on text-to-image diffusion models demonstrate the effectiveness of our artifact detector as well as the soundness of our diagnose-then-treat design.
Universal Actions for Enhanced Embodied Foundation Models
Jan 17, 2025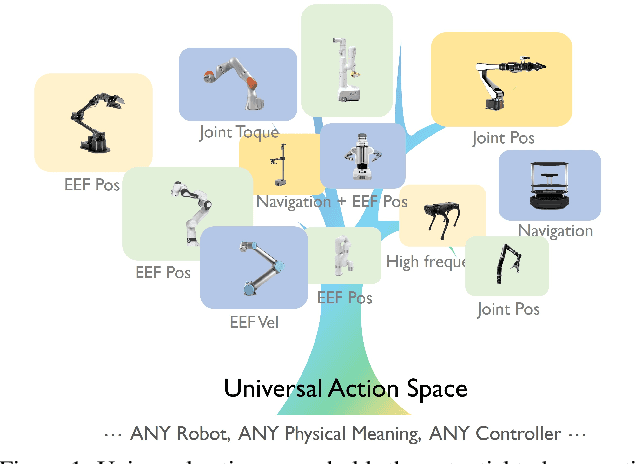

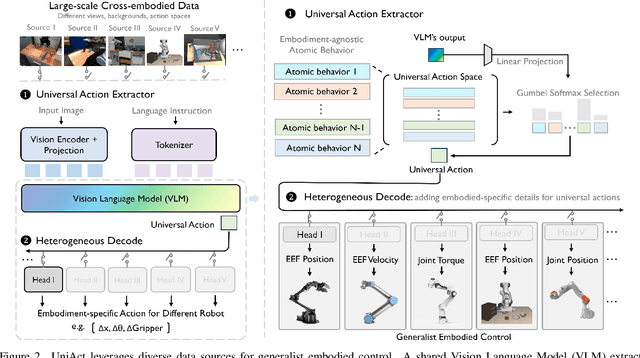
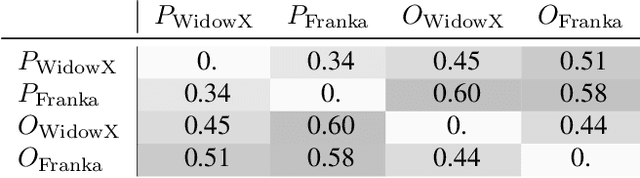
Training on diverse, internet-scale data is a key factor in the success of recent large foundation models. Yet, using the same recipe for building embodied agents has faced noticeable difficulties. Despite the availability of many crowd-sourced embodied datasets, their action spaces often exhibit significant heterogeneity due to distinct physical embodiment and control interfaces for different robots, causing substantial challenges in developing embodied foundation models using cross-domain data. In this paper, we introduce UniAct, a new embodied foundation modeling framework operating in a tokenized Universal Action Space. Our learned universal actions capture the generic atomic behaviors across diverse robots by exploiting their shared structural features, and enable enhanced cross-domain data utilization and cross-embodiment generalizations by eliminating the notorious heterogeneity. The universal actions can be efficiently translated back to heterogeneous actionable commands by simply adding embodiment-specific details, from which fast adaptation to new robots becomes simple and straightforward. Our 0.5B instantiation of UniAct outperforms 14X larger SOTA embodied foundation models in extensive evaluations on various real-world and simulation robots, showcasing exceptional cross-embodiment control and adaptation capability, highlighting the crucial benefit of adopting universal actions. Project page: https://github.com/2toinf/UniAct
VanGogh: A Unified Multimodal Diffusion-based Framework for Video Colorization
Jan 16, 2025



Video colorization aims to transform grayscale videos into vivid color representations while maintaining temporal consistency and structural integrity. Existing video colorization methods often suffer from color bleeding and lack comprehensive control, particularly under complex motion or diverse semantic cues. To this end, we introduce VanGogh, a unified multimodal diffusion-based framework for video colorization. VanGogh tackles these challenges using a Dual Qformer to align and fuse features from multiple modalities, complemented by a depth-guided generation process and an optical flow loss, which help reduce color overflow. Additionally, a color injection strategy and luma channel replacement are implemented to improve generalization and mitigate flickering artifacts. Thanks to this design, users can exercise both global and local control over the generation process, resulting in higher-quality colorized videos. Extensive qualitative and quantitative evaluations, and user studies, demonstrate that VanGogh achieves superior temporal consistency and color fidelity.Project page: https://becauseimbatman0.github.io/VanGogh.
MangaNinja: Line Art Colorization with Precise Reference Following
Jan 14, 2025



Derived from diffusion models, MangaNinjia specializes in the task of reference-guided line art colorization. We incorporate two thoughtful designs to ensure precise character detail transcription, including a patch shuffling module to facilitate correspondence learning between the reference color image and the target line art, and a point-driven control scheme to enable fine-grained color matching. Experiments on a self-collected benchmark demonstrate the superiority of our model over current solutions in terms of precise colorization. We further showcase the potential of the proposed interactive point control in handling challenging cases, cross-character colorization, multi-reference harmonization, beyond the reach of existing algorithms.