 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBandwidth-Efficient and Privacy-Preserving Edge-Cloud Many-to-Many Speech Translation
May 27, 2026Multimodal large language models (MLLMs) have demonstrated significant potential for speech-to-text translation (S2TT). However, existing deployment paradigms face critical challenges: pure on-device models suffer from resource constraints, while centralized cloud systems incur severe privacy risks and bandwidth bottlenecks by transmitting raw voice data. Furthermore, most models exhibit English-centric biases, restricting many-to-many translation scaling. In this paper, we propose Edge-cloud Speech Recognition and Translation (ESRT), a privacy-preserving and bandwidth-efficient collaborative edge-cloud MLLM framework. Specifically, we design an edge-cloud split inference architecture that retains a lightweight speech encoder and adapter on the device, transmitting only highly compressed intermediate features to the cloud. This fundamentally prevents voiceprint leakage and reduces bandwidth requirements by up to 10$\times$. To overcome English-centric bottlenecks, we introduce a multi-task weighted curriculum learning strategy with data balancing to ensure robust cross-lingual consistency. Extensive experiments on the FLEURS dataset demonstrate that our models, ESRT-4B and ESRT-12B, achieve state-of-the-art many-to-many S2TT performance across 45 languages ($45 \times 44$ directions). Code and models are released to facilitate reproducible, privacy-aware MLLM S2TT research. The code and models are released at https://github.com/yxduir/esrt.
Tailoring Teaching to Aptitude: Direction-Adaptive Self-Distillation for LLM Reasoning
May 21, 2026On-policy self-distillation (OPSD) is an emerging LLM post-training paradigm in which the model serves as its own teacher: conditioned on privileged information such as a reference trace or hint, the same policy provides dense token-level supervision on its own rollouts. However, recent studies show that OPSD degrades complex reasoning by suppressing predictive uncertainty, which supports exploration and hypothesis revision. Our token-level analysis shows that this failure arises from applying a uniform direction of teacher supervision across tokens with different uncertainty levels: conformity to the privileged self-teacher suppresses exploration at high entropy, while deviation from the teacher degrades step accuracy at low entropy. Accordingly, we propose \textbf{Direction-Adaptive Self-Distillation} (\textbf{DASD}), which reframes privileged self-distillation from uniform teacher imitation into entropy-routed directional supervision: high-entropy tokens are pushed away from the privileged teacher to preserve exploration, while low-entropy tokens are pulled toward the teacher to stabilize step-level execution. Across six mathematical reasoning benchmarks, DASD achieves the best macro Avg@16 over strong RLVR and self-distillation baselines. Pass@$k$, reasoning-health, and generalization analyses show that these average gains come from preserving exploration without sacrificing step-level execution.
Towards Effective In-context Cross-domain Knowledge Transfer via Domain-invariant-neurons-based Retrieval
Apr 07, 2026Large language models (LLMs) have made notable progress in logical reasoning, yet still fall short of human-level performance. Current boosting strategies rely on expert-crafted in-domain demonstrations, limiting their applicability in expertise-scarce domains, such as specialized mathematical reasoning, formal logic, or legal analysis. In this work, we demonstrate the feasibility of leveraging cross-domain demonstrating examples to boost the LLMs' reasoning performance. Despite substantial domain differences, many reusable implicit logical structures are shared across domains. In order to effectively retrieve cross-domain examples for unseen domains under investigation, in this work, we further propose an effective retrieval method, called domain-invariant neurons-based retrieval (\textbf{DIN-Retrieval}). Concisely, DIN-Retrieval first summarizes a hidden representation that is universal across different domains. Then, during the inference stage, we use the DIN vector to retrieve structurally compatible cross-domain demonstrations for the in-context learning. Experimental results in multiple settings for the transfer of mathematical and logical reasoning demonstrate that our method achieves an average improvement of 1.8 over the state-of-the-art methods \footnote{Our implementation is available at https://github.com/Leon221220/DIN-Retrieval}.
Reason Analogically via Cross-domain Prior Knowledge: An Empirical Study of Cross-domain Knowledge Transfer for In-Context Learning
Apr 07, 2026Despite its success, existing in-context learning (ICL) relies on in-domain expert demonstrations, limiting its applicability when expert annotations are scarce. We posit that different domains may share underlying reasoning structures, enabling source-domain demonstrations to improve target-domain inference despite semantic mismatch. To test this hypothesis, we conduct a comprehensive empirical study of different retrieval methods to validate the feasibility of achieving cross-domain knowledge transfer under the in-context learning setting. Our results demonstrate conditional positive transfer in cross-domain ICL. We identify a clear example absorption threshold: beyond it, positive transfer becomes more likely, and additional demonstrations yield larger gains. Further analysis suggests that these gains stem from reasoning structure repair by retrieved cross-domain examples, rather than semantic cues. Overall, our study validates the feasibility of leveraging cross-domain knowledge transfer to improve cross-domain ICL performance, motivating the community to explore designing more effective retrieval approaches for this novel direction.\footnote{Our implementation is available at https://github.com/littlelaska/ICL-TF4LR}
Mitigating Translationese Bias in Multilingual LLM-as-a-Judge via Disentangled Information Bottleneck
Mar 11, 2026Large language models (LLMs) have become a standard for multilingual evaluation, yet they exhibit a severe systematic translationese bias. In this paper, translationese bias is characterized as LLMs systematically favoring machine-translated text over human-authored references, particularly in low-resource languages. We attribute this bias to spurious correlations with (i) latent manifold alignment with English and (ii) cross-lingual predictability. To mitigate this bias, we propose DIBJudge, a robust fine-tuning framework that learns a minimally sufficient, judgment-critical representation via variational information compression, while explicitly isolating spurious factors into the dedicated bias branch. Furthermore, we incorporate a cross-covariance penalty that explicitly suppresses statistical dependence between robust and bias representations, thereby encouraging effective disentanglement. Extensive evaluations on multilingual reward modeling benchmarks and a dedicated translationese bias evaluation suite demonstrate that the proposed DIBJudge consistently outperforms strong baselines and substantially mitigates translationese bias.
Scalable Multilingual Multimodal Machine Translation with Speech-Text Fusion
Feb 25, 2026Multimodal Large Language Models (MLLMs) have achieved notable success in enhancing translation performance by integrating multimodal information. However, existing research primarily focuses on image-guided methods, whose applicability is constrained by the scarcity of multilingual image-text pairs. The speech modality overcomes this limitation due to its natural alignment with text and the abundance of existing speech datasets, which enable scalable language coverage. In this paper, we propose a Speech-guided Machine Translation (SMT) framework that integrates speech and text as fused inputs into an MLLM to improve translation quality. To mitigate reliance on low-resource data, we introduce a Self-Evolution Mechanism. The core components of this framework include a text-to-speech model, responsible for generating synthetic speech, and an MLLM capable of classifying synthetic speech samples and iteratively optimizing itself using positive samples. Experimental results demonstrate that our framework surpasses all existing methods on the Multi30K multimodal machine translation benchmark, achieving new state-of-the-art results. Furthermore, on general machine translation datasets, particularly the FLORES-200, it achieves average state-of-the-art performance in 108 translation directions. Ablation studies on CoVoST-2 confirms that differences between synthetic and authentic speech have negligible impact on translation quality. The code and models are released at https://github.com/yxduir/LLM-SRT.
Decoupling Skeleton and Flesh: Efficient Multimodal Table Reasoning with Disentangled Alignment and Structure-aware Guidance
Feb 03, 2026Reasoning over table images remains challenging for Large Vision-Language Models (LVLMs) due to complex layouts and tightly coupled structure-content information. Existing solutions often depend on expensive supervised training, reinforcement learning, or external tools, limiting efficiency and scalability. This work addresses a key question: how to adapt LVLMs to table reasoning with minimal annotation and no external tools? Specifically, we first introduce DiSCo, a Disentangled Structure-Content alignment framework that explicitly separates structural abstraction from semantic grounding during multimodal alignment, efficiently adapting LVLMs to tables structures. Building on DiSCo, we further present Table-GLS, a Global-to-Local Structure-guided reasoning framework that performs table reasoning via structured exploration and evidence-grounded inference. Extensive experiments across diverse benchmarks demonstrate that our framework efficiently enhances LVLM's table understanding and reasoning capabilities, particularly generalizing to unseen table structures.
MCGA: A Multi-task Classical Chinese Literary Genre Audio Corpus
Jan 14, 2026With the rapid advancement of Multimodal Large Language Models (MLLMs), their potential has garnered significant attention in Chinese Classical Studies (CCS). While existing research has primarily focused on text and visual modalities, the audio corpus within this domain remains largely underexplored. To bridge this gap, we propose the Multi-task Classical Chinese Literary Genre Audio Corpus (MCGA). It encompasses a diverse range of literary genres across six tasks: Automatic Speech Recognition (ASR), Speech-to-Text Translation (S2TT), Speech Emotion Captioning (SEC), Spoken Question Answering (SQA), Speech Understanding (SU), and Speech Reasoning (SR). Through the evaluation of ten MLLMs, our experimental results demonstrate that current models still face substantial challenges when processed on the MCGA test set. Furthermore, we introduce an evaluation metric for SEC and a metric to measure the consistency between the speech and text capabilities of MLLMs. We release MCGA and our code to the public to facilitate the development of MLLMs with more robust multidimensional audio capabilities in CCS. MCGA Corpus: https://github.com/yxduir/MCGA
From Long to Lean: Performance-aware and Adaptive Chain-of-Thought Compression via Multi-round Refinement
Sep 26, 2025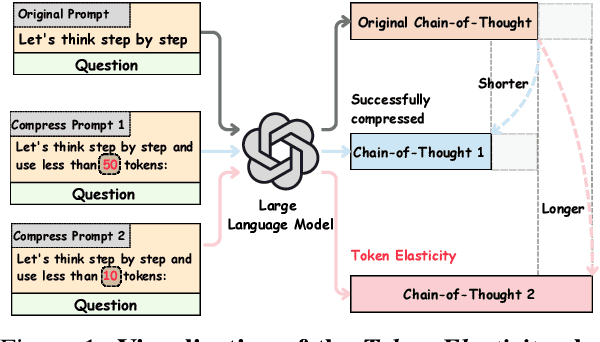
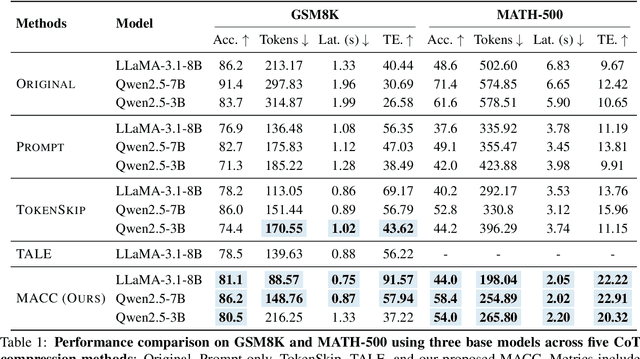
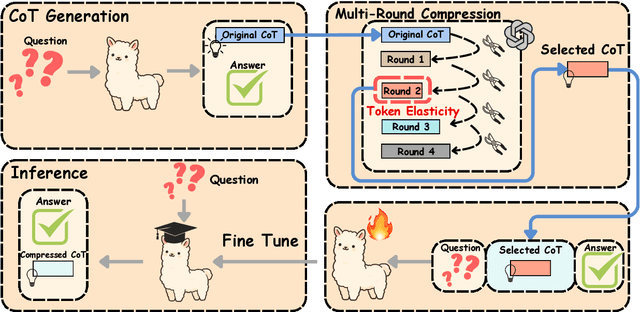
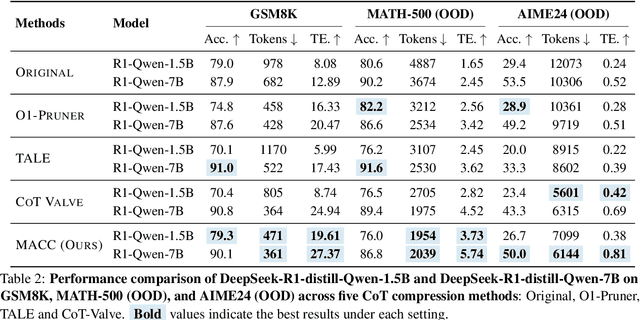
Chain-of-Thought (CoT) reasoning improves performance on complex tasks but introduces significant inference latency due to verbosity. We propose Multiround Adaptive Chain-of-Thought Compression (MACC), a framework that leverages the token elasticity phenomenon--where overly small token budgets can paradoxically increase output length--to progressively compress CoTs via multiround refinement. This adaptive strategy allows MACC to determine the optimal compression depth for each input. Our method achieves an average accuracy improvement of 5.6 percent over state-of-the-art baselines, while also reducing CoT length by an average of 47 tokens and significantly lowering latency. Furthermore, we show that test-time performance--accuracy and token length--can be reliably predicted using interpretable features like perplexity and compression rate on the training set. Evaluated across different models, our method enables efficient model selection and forecasting without repeated fine-tuning, demonstrating that CoT compression is both effective and predictable. Our code will be released in https://github.com/Leon221220/MACC.
CCFQA: A Benchmark for Cross-Lingual and Cross-Modal Speech and Text Factuality Evaluation
Aug 10, 2025As Large Language Models (LLMs) are increasingly popularized in the multilingual world, ensuring hallucination-free factuality becomes markedly crucial. However, existing benchmarks for evaluating the reliability of Multimodal Large Language Models (MLLMs) predominantly focus on textual or visual modalities with a primary emphasis on English, which creates a gap in evaluation when processing multilingual input, especially in speech. To bridge this gap, we propose a novel \textbf{C}ross-lingual and \textbf{C}ross-modal \textbf{F}actuality benchmark (\textbf{CCFQA}). Specifically, the CCFQA benchmark contains parallel speech-text factual questions across 8 languages, designed to systematically evaluate MLLMs' cross-lingual and cross-modal factuality capabilities. Our experimental results demonstrate that current MLLMs still face substantial challenges on the CCFQA benchmark. Furthermore, we propose a few-shot transfer learning strategy that effectively transfers the Question Answering (QA) capabilities of LLMs in English to multilingual Spoken Question Answering (SQA) tasks, achieving competitive performance with GPT-4o-mini-Audio using just 5-shot training. We release CCFQA as a foundational research resource to promote the development of MLLMs with more robust and reliable speech understanding capabilities. Our code and dataset are available at https://github.com/yxduir/ccfqa.