 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFIRE: A Comprehensive Benchmark for Financial Intelligence and Reasoning Evaluation
Feb 25, 2026We introduce FIRE, a comprehensive benchmark designed to evaluate both the theoretical financial knowledge of LLMs and their ability to handle practical business scenarios. For theoretical assessment, we curate a diverse set of examination questions drawn from widely recognized financial qualification exams, enabling evaluation of LLMs deep understanding and application of financial knowledge. In addition, to assess the practical value of LLMs in real-world financial tasks, we propose a systematic evaluation matrix that categorizes complex financial domains and ensures coverage of essential subdomains and business activities. Based on this evaluation matrix, we collect 3,000 financial scenario questions, consisting of closed-form decision questions with reference answers and open-ended questions evaluated by predefined rubrics. We conduct comprehensive evaluations of state-of-the-art LLMs on the FIRE benchmark, including XuanYuan 4.0, our latest financial-domain model, as a strong in-domain baseline. These results enable a systematic analysis of the capability boundaries of current LLMs in financial applications. We publicly release the benchmark questions and evaluation code to facilitate future research.
MirrorLA: Reflecting Feature Map for Vision Linear Attention
Feb 04, 2026Linear attention significantly reduces the computational complexity of Transformers from quadratic to linear, yet it consistently lags behind softmax-based attention in performance. We identify the root cause of this degradation as the non-negativity constraint imposed on kernel feature maps: standard projections like ReLU act as "passive truncation" operators, indiscriminately discarding semantic information residing in the negative domain. We propose MirrorLA, a geometric framework that substitutes passive truncation with active reorientation. By leveraging learnable Householder reflections, MirrorLA rotates the feature geometry into the non-negative orthant to maximize information retention. Our approach restores representational density through a cohesive, multi-scale design: it first optimizes local discriminability via block-wise isometries, stabilizes long-context dynamics using variance-aware modulation to diversify activations, and finally, integrates dispersed subspaces via cross-head reflections to induce global covariance mixing. MirrorLA achieves state-of-the-art performance across standard benchmarks, demonstrating that strictly linear efficiency can be achieved without compromising representational fidelity.
STILL: Selecting Tokens for Intra-Layer Hybrid Attention to Linearize LLMs
Feb 02, 2026Linearizing pretrained large language models (LLMs) primarily relies on intra-layer hybrid attention mechanisms to alleviate the quadratic complexity of standard softmax attention. Existing methods perform token routing based on sliding-window partitions, resulting in position-based selection and fails to capture token-specific global importance. Meanwhile, linear attention further suffers from distribution shift caused by learnable feature maps that distort pretrained feature magnitudes. Motivated by these limitations, we propose STILL, an intra-layer hybrid linearization framework for efficiently linearizing LLMs. STILL introduces a Self-Saliency Score with strong local-global consistency, enabling accurate token selection using sliding-window computation, and retains salient tokens for sparse softmax attention while summarizing the remaining context via linear attention. To preserve pretrained representations, we design a Norm-Preserved Feature Map (NP-Map) that decouples feature direction from magnitude and reinjects pretrained norms. We further adopt a unified training-inference architecture with chunk-wise parallelization and delayed selection to improve hardware efficiency. Experiments show that STILL matches or surpasses the original pretrained model on commonsense and general reasoning tasks, and achieves up to a 86.2% relative improvement over prior linearized attention methods on long-context benchmarks.
MCGA: A Multi-task Classical Chinese Literary Genre Audio Corpus
Jan 14, 2026With the rapid advancement of Multimodal Large Language Models (MLLMs), their potential has garnered significant attention in Chinese Classical Studies (CCS). While existing research has primarily focused on text and visual modalities, the audio corpus within this domain remains largely underexplored. To bridge this gap, we propose the Multi-task Classical Chinese Literary Genre Audio Corpus (MCGA). It encompasses a diverse range of literary genres across six tasks: Automatic Speech Recognition (ASR), Speech-to-Text Translation (S2TT), Speech Emotion Captioning (SEC), Spoken Question Answering (SQA), Speech Understanding (SU), and Speech Reasoning (SR). Through the evaluation of ten MLLMs, our experimental results demonstrate that current models still face substantial challenges when processed on the MCGA test set. Furthermore, we introduce an evaluation metric for SEC and a metric to measure the consistency between the speech and text capabilities of MLLMs. We release MCGA and our code to the public to facilitate the development of MLLMs with more robust multidimensional audio capabilities in CCS. MCGA Corpus: https://github.com/yxduir/MCGA
MoGU: A Framework for Enhancing Safety of Open-Sourced LLMs While Preserving Their Usability
May 23, 2024



Large Language Models (LLMs) are increasingly deployed in various applications. As their usage grows, concerns regarding their safety are rising, especially in maintaining harmless responses when faced with malicious instructions. Many defense strategies have been developed to enhance the safety of LLMs. However, our research finds that existing defense strategies lead LLMs to predominantly adopt a rejection-oriented stance, thereby diminishing the usability of their responses to benign instructions. To solve this problem, we introduce the MoGU framework, designed to enhance LLMs' safety while preserving their usability. Our MoGU framework transforms the base LLM into two variants: the usable LLM and the safe LLM, and further employs dynamic routing to balance their contribution. When encountering malicious instructions, the router will assign a higher weight to the safe LLM to ensure that responses are harmless. Conversely, for benign instructions, the router prioritizes the usable LLM, facilitating usable and helpful responses. On various open-sourced LLMs, we compare multiple defense strategies to verify the superiority of our MoGU framework. Besides, our analysis provides key insights into the effectiveness of MoGU and verifies that our designed routing mechanism can effectively balance the contribution of each variant by assigning weights. Our work released the safer Llama2, Vicuna, Falcon, Dolphin, and Baichuan2.
Predicting Head Movement in Panoramic Video: A Deep Reinforcement Learning Approach
Sep 21, 2018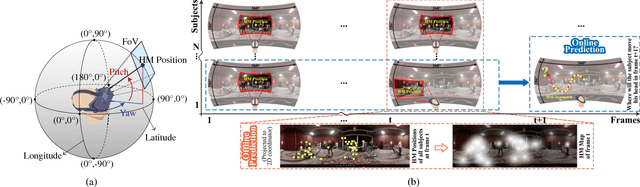

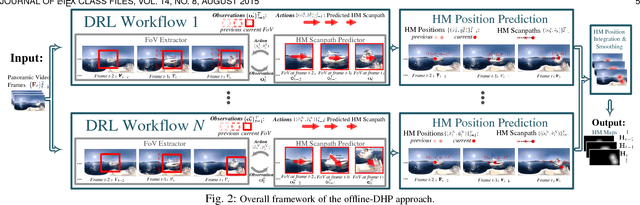
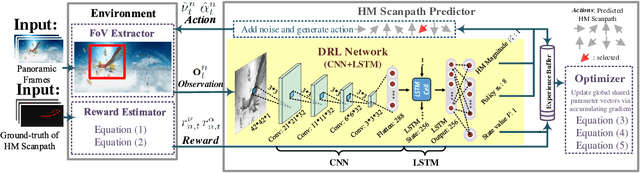
Panoramic video provides immersive and interactive experience by enabling humans to control the field of view (FoV) through head movement (HM). Thus, HM plays a key role in modeling human attention on panoramic video. This paper establishes a database collecting subjects' HM in panoramic video sequences. From this database, we find that the HM data are highly consistent across subjects. Furthermore, we find that deep reinforcement learning (DRL) can be applied to predict HM positions, via maximizing the reward of imitating human HM scanpaths through the agent's actions. Based on our findings, we propose a DRL-based HM prediction (DHP) approach with offline and online versions, called offline-DHP and online-DHP. In offline-DHP, multiple DRL workflows are run to determine potential HM positions at each panoramic frame. Then, a heat map of the potential HM positions, named the HM map, is generated as the output of offline-DHP. In online-DHP, the next HM position of one subject is estimated given the currently observed HM position, which is achieved by developing a DRL algorithm upon the learned offline-DHP model. Finally, the experiments validate that our approach is effective in both offline and online prediction of HM positions for panoramic video, and that the learned offline-DHP model can improve the performance of online-DHP.
* 15 pages, 10 figures, published on TPAMI 2018
Generalization Tower Network: A Novel Deep Neural Network Architecture for Multi-Task Learning
Jan 02, 2018
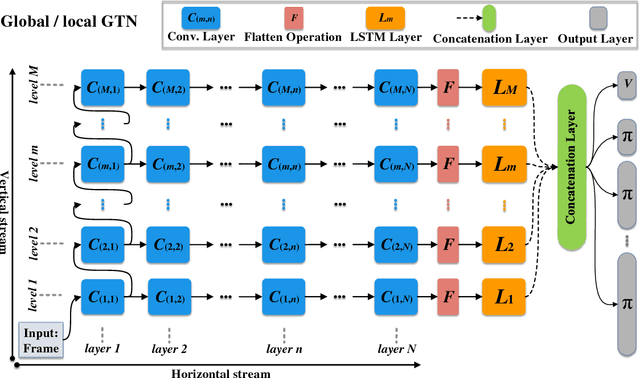
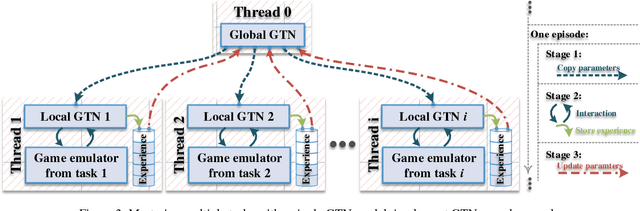
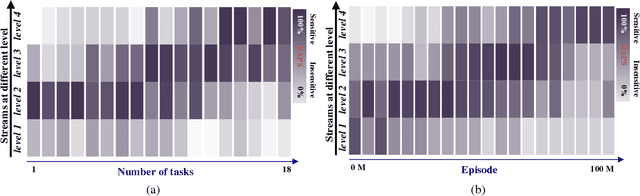
Deep learning (DL) advances state-of-the-art reinforcement learning (RL), by incorporating deep neural networks in learning representations from the input to RL. However, the conventional deep neural network architecture is limited in learning representations for multi-task RL (MT-RL), as multiple tasks can refer to different kinds of representations. In this paper, we thus propose a novel deep neural network architecture, namely generalization tower network (GTN), which can achieve MT-RL within a single learned model. Specifically, the architecture of GTN is composed of both horizontal and vertical streams. In our GTN architecture, horizontal streams are used to learn representation shared in similar tasks. In contrast, the vertical streams are introduced to be more suitable for handling diverse tasks, which encodes hierarchical shared knowledge of these tasks. The effectiveness of the introduced vertical stream is validated by experimental results. Experimental results further verify that our GTN architecture is able to advance the state-of-the-art MT-RL, via being tested on 51 Atari games.