 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMASPO: Joint Prompt Optimization for LLM-based Multi-Agent Systems
May 07, 2026Large language model (LLM)-based Multi-agent systems (MAS) have shown promise in tackling complex collaborative tasks, where agents are typically orchestrated via role-specific prompts. While the quality of these prompts is pivotal, jointly optimizing them across interacting agents remains a non-trivial challenge, primarily due to the misalignment between local agent objectives and holistic system goals. To address this, we introduce MASPO, a novel framework designed to automatically and iteratively refine prompts across the entire system. A core innovation of MASPO is its joint evaluation mechanism, which assesses prompts not merely by their local validity, but by their capacity to facilitate downstream success for successor agents. This effectively bridges the gap between local interactions and global outcomes without relying on ground-truth labels. Furthermore, MASPO employs a data-driven evolutionary beam search to efficiently navigate the high-dimensional prompt space. Extensive empirical evaluations across 6 diverse tasks demonstrate that MASPO consistently outperforms state-of-the-art prompt optimization methods, achieving an average accuracy improvement of 2.9. We release our code at https://github.com/wangzx1219/MASPO.
Chat2Workflow: A Benchmark for Generating Executable Visual Workflows with Natural Language
Apr 21, 2026At present, executable visual workflows have emerged as a mainstream paradigm in real-world industrial deployments, offering strong reliability and controllability. However, in current practice, such workflows are almost entirely constructed through manual engineering: developers must carefully design workflows, write prompts for each step, and repeatedly revise the logic as requirements evolve-making development costly, time-consuming, and error-prone. To study whether large language models can automate this multi-round interaction process, we introduce Chat2Workflow, a benchmark for generating executable visual workflows directly from natural language, and propose a robust agentic framework to mitigate recurrent execution errors. Chat2Workflow is built from a large collection of real-world business workflows, with each instance designed so that the generated workflow can be transformed and directly deployed to practical workflow platforms such as Dify and Coze. Experimental results show that while state-of-the-art language models can often capture high-level intent, they struggle to generate correct, stable, and executable workflows, especially under complex or changing requirements. Although our agentic framework yields up to 5.34% resolve rate gains, the remaining real-world gap positions Chat2Workflow as a foundation for advancing industrial-grade automation. Code is available at https://github.com/zjunlp/Chat2Workflow.
LMEB: Long-horizon Memory Embedding Benchmark
Mar 19, 2026Memory embeddings are crucial for memory-augmented systems, such as OpenClaw, but their evaluation is underexplored in current text embedding benchmarks, which narrowly focus on traditional passage retrieval and fail to assess models' ability to handle long-horizon memory retrieval tasks involving fragmented, context-dependent, and temporally distant information. To address this, we introduce the Long-horizon Memory Embedding Benchmark (LMEB), a comprehensive framework that evaluates embedding models' capabilities in handling complex, long-horizon memory retrieval tasks. LMEB spans 22 datasets and 193 zero-shot retrieval tasks across 4 memory types: episodic, dialogue, semantic, and procedural, with both AI-generated and human-annotated data. These memory types differ in terms of level of abstraction and temporal dependency, capturing distinct aspects of memory retrieval that reflect the diverse challenges of the real world. We evaluate 15 widely used embedding models, ranging from hundreds of millions to ten billion parameters. The results reveal that (1) LMEB provides a reasonable level of difficulty; (2) Larger models do not always perform better; (3) LMEB and MTEB exhibit orthogonality. This suggests that the field has yet to converge on a universal model capable of excelling across all memory retrieval tasks, and that performance in traditional passage retrieval may not generalize to long-horizon memory retrieval. In summary, by providing a standardized and reproducible evaluation framework, LMEB fills a crucial gap in memory embedding evaluation, driving further advancements in text embedding for handling long-term, context-dependent memory retrieval. LMEB is available at https://github.com/KaLM-Embedding/LMEB.
ChartE$^{3}$: A Comprehensive Benchmark for End-to-End Chart Editing
Jan 29, 2026Charts are a fundamental visualization format for structured data analysis. Enabling end-to-end chart editing according to user intent is of great practical value, yet remains challenging due to the need for both fine-grained control and global structural consistency. Most existing approaches adopt pipeline-based designs, where natural language or code serves as an intermediate representation, limiting their ability to faithfully execute complex edits. We introduce ChartE$^{3}$, an End-to-End Chart Editing benchmark that directly evaluates models without relying on intermediate natural language programs or code-level supervision. ChartE$^{3}$ focuses on two complementary editing dimensions: local editing, which involves fine-grained appearance changes such as font or color adjustments, and global editing, which requires holistic, data-centric transformations including data filtering and trend line addition. ChartE$^{3}$ contains over 1,200 high-quality samples constructed via a well-designed data pipeline with human curation. Each sample is provided as a triplet of a chart image, its underlying code, and a multimodal editing instruction, enabling evaluation from both objective and subjective perspectives. Extensive benchmarking of state-of-the-art multimodal large language models reveals substantial performance gaps, particularly on global editing tasks, highlighting critical limitations in current end-to-end chart editing capabilities.
RouteMoA: Dynamic Routing without Pre-Inference Boosts Efficient Mixture-of-Agents
Jan 26, 2026Mixture-of-Agents (MoA) improves LLM performance through layered collaboration, but its dense topology raises costs and latency. Existing methods employ LLM judges to filter responses, yet still require all models to perform inference before judging, failing to cut costs effectively. They also lack model selection criteria and struggle with large model pools, where full inference is costly and can exceed context limits. To address this, we propose RouteMoA, an efficient mixture-of-agents framework with dynamic routing. It employs a lightweight scorer to perform initial screening by predicting coarse-grained performance from the query, narrowing candidates to a high-potential subset without inference. A mixture of judges then refines these scores through lightweight self- and cross-assessment based on existing model outputs, providing posterior correction without additional inference. Finally, a model ranking mechanism selects models by balancing performance, cost, and latency. RouteMoA outperforms MoA across varying tasks and model pool sizes, reducing cost by 89.8% and latency by 63.6% in the large-scale model pool.
LexSemBridge: Fine-Grained Dense Representation Enhancement through Token-Aware Embedding Augmentation
Aug 25, 2025As queries in retrieval-augmented generation (RAG) pipelines powered by large language models (LLMs) become increasingly complex and diverse, dense retrieval models have demonstrated strong performance in semantic matching. Nevertheless, they often struggle with fine-grained retrieval tasks, where precise keyword alignment and span-level localization are required, even in cases with high lexical overlap that would intuitively suggest easier retrieval. To systematically evaluate this limitation, we introduce two targeted tasks, keyword retrieval and part-of-passage retrieval, designed to simulate practical fine-grained scenarios. Motivated by these observations, we propose LexSemBridge, a unified framework that enhances dense query representations through fine-grained, input-aware vector modulation. LexSemBridge constructs latent enhancement vectors from input tokens using three paradigms: Statistical (SLR), Learned (LLR), and Contextual (CLR), and integrates them with dense embeddings via element-wise interaction. Theoretically, we show that this modulation preserves the semantic direction while selectively amplifying discriminative dimensions. LexSemBridge operates as a plug-in without modifying the backbone encoder and naturally extends to both text and vision modalities. Extensive experiments across semantic and fine-grained retrieval tasks validate the effectiveness and generality of our approach. All code and models are publicly available at https://github.com/Jasaxion/LexSemBridge/
KaLM-Embedding-V2: Superior Training Techniques and Data Inspire A Versatile Embedding Model
Jun 26, 2025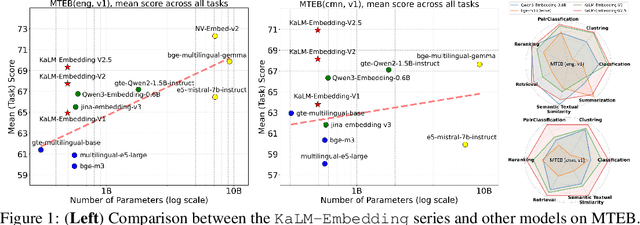
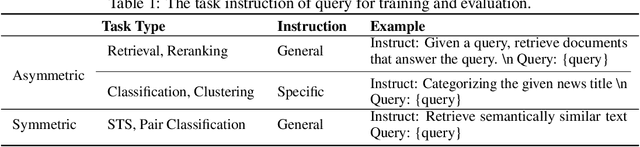

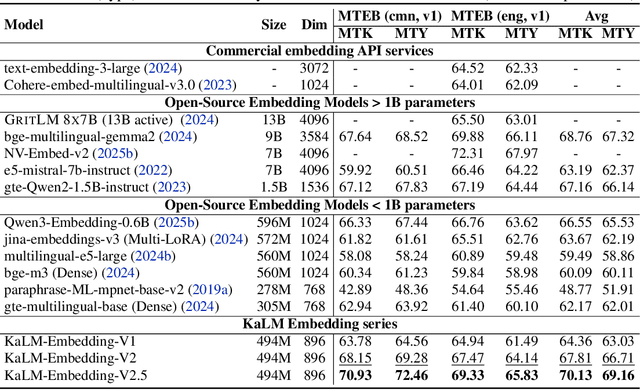
In this paper, we propose KaLM-Embedding-V2, a versatile and compact embedding model, which achieves impressive performance in general-purpose text embedding tasks by leveraging superior training techniques and data. Our key innovations include: (1) To better align the architecture with representation learning, we remove the causal attention mask and adopt a fully bidirectional transformer with simple yet effective mean-pooling to produce fixed-length embeddings; (2) We employ a multi-stage training pipeline: (i) pre-training on large-scale weakly supervised open-source corpora; (ii) fine-tuning on high-quality retrieval and non-retrieval datasets; and (iii) model-soup parameter averaging for robust generalization. Besides, we introduce a focal-style reweighting mechanism that concentrates learning on difficult samples and an online hard-negative mixing strategy to continuously enrich hard negatives without expensive offline mining; (3) We collect over 20 categories of data for pre-training and 100 categories of data for fine-tuning, to boost both the performance and generalization of the embedding model. Extensive evaluations on the Massive Text Embedding Benchmark (MTEB) Chinese and English show that our model significantly outperforms others of comparable size, and competes with 3x, 14x, 18x, and 26x larger embedding models, setting a new standard for a versatile and compact embedding model with less than 1B parameters.
DAST: Context-Aware Compression in LLMs via Dynamic Allocation of Soft Tokens
Feb 17, 2025



Large Language Models (LLMs) face computational inefficiencies and redundant processing when handling long context inputs, prompting a focus on compression techniques. While existing semantic vector-based compression methods achieve promising performance, these methods fail to account for the intrinsic information density variations between context chunks, instead allocating soft tokens uniformly across context chunks. This uniform distribution inevitably diminishes allocation to information-critical regions. To address this, we propose Dynamic Allocation of Soft Tokens (DAST), a simple yet effective method that leverages the LLM's intrinsic understanding of contextual relevance to guide compression. DAST combines perplexity-based local information with attention-driven global information to dynamically allocate soft tokens to the informative-rich chunks, enabling effective, context-aware compression. Experimental results across multiple benchmarks demonstrate that DAST surpasses state-of-the-art methods.
KaLM-Embedding: Superior Training Data Brings A Stronger Embedding Model
Jan 03, 2025



As retrieval-augmented generation prevails in large language models, embedding models are becoming increasingly crucial. Despite the growing number of general embedding models, prior work often overlooks the critical role of training data quality. In this work, we introduce KaLM-Embedding, a general multilingual embedding model that leverages a large quantity of cleaner, more diverse, and domain-specific training data. Our model has been trained with key techniques proven to enhance performance: (1) persona-based synthetic data to create diversified examples distilled from LLMs, (2) ranking consistency filtering to remove less informative samples, and (3) semi-homogeneous task batch sampling to improve training efficacy. Departing from traditional BERT-like architectures, we adopt Qwen2-0.5B as the pre-trained model, facilitating the adaptation of auto-regressive language models for general embedding tasks. Extensive evaluations of the MTEB benchmark across multiple languages show that our model outperforms others of comparable size, setting a new standard for multilingual embedding models with <1B parameters.
Loss-Aware Curriculum Learning for Chinese Grammatical Error Correction
Dec 31, 2024Chinese grammatical error correction (CGEC) aims to detect and correct errors in the input Chinese sentences. Recently, Pre-trained Language Models (PLMS) have been employed to improve the performance. However, current approaches ignore that correction difficulty varies across different instances and treat these samples equally, enhancing the challenge of model learning. To address this problem, we propose a multi-granularity Curriculum Learning (CL) framework. Specifically, we first calculate the correction difficulty of these samples and feed them into the model from easy to hard batch by batch. Then Instance-Level CL is employed to help the model optimize in the appropriate direction automatically by regulating the loss function. Extensive experimental results and comprehensive analyses of various datasets prove the effectiveness of our method.