 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLycheeCluster: Efficient Long-Context Inference with Structure-Aware Chunking and Hierarchical KV Indexing
Mar 09, 2026The quadratic complexity of the attention mechanism and the substantial memory footprint of the Key-Value (KV) cache present severe computational and memory challenges for Large Language Models (LLMs) processing long contexts. Existing retrieval-based methods often compromise semantic integrity through fixed-size chunking and suffer from inefficient linear scanning. In this paper, we propose LycheeCluster, a novel method for efficient KV cache management. LycheeCluster preserves local semantic coherence via boundary-aware chunking and constructs a recursive hierarchical index rooted in the triangle inequality. This design transforms cache retrieval from a linear scan into a theoretically bounded, logarithmic-time pruning process, while a lazy update strategy supports efficient streaming generation. Experiments demonstrate that LycheeCluster achieves up to a 3.6x end-to-end inference speedup with negligible degradation in model performance, outperforming state-of-the-art KV cache management methods (e.g., Quest, ClusterKV). We will release our code and kernels after publication.
SLO-Aware Compute Resource Allocation for Prefill-Decode Disaggregated LLM Inference
Mar 05, 2026Prefill-Decode (P/D) disaggregation has emerged as a widely adopted optimization strategy for Large Language Model (LLM) inference. However, there currently exists no well-established methodology for determining the optimal number of P/D hardware resources, subject to constraints on total throughput, service level objectives (SLOs), and request characteristics - specifically input and output lengths. To address this gap, we propose a hybrid approach that combines theoretical modeling with empirical benchmarking. First, we present a theoretical model for calculating P/D resource counts, which is based on total throughput requirements, request input and output lengths, as well as prefill and decode throughput. Then, to obtain the actual prefill and decode throughput under SLO constraints, we model the prefill process using M/M/1 queuing theory, deriving the achieved prefill throughput from the benchmarked maximum prefill throughput and Time-To-First-Token (TTFT). For the decode phase, we determine the decode batch sizes that meet Time-Per-Output-Token (TPOT) requirements and obtain the corresponding decode throughput through empirical measurements. Our experimental results demonstrate that the proposed method can accurately predict optimal P/D resource allocation in real-world LLM inference scenarios.
Dynamic Long Context Reasoning over Compressed Memory via End-to-End Reinforcement Learning
Feb 09, 2026Large Language Models (LLMs) face significant challenges in long-context processing, including quadratic computational costs, information forgetting, and the context fragmentation inherent in retrieval-augmented generation (RAG). We propose a cognitively inspired framework for efficient long-context inference based on chunk-wise compression and selective memory recall, rather than processing all raw tokens. The framework segments long inputs into chunks and encodes each chunk into compressed memory representations using a learned compressor. A gating module dynamically selects relevant memory blocks, which are then iteratively processed by a reasoning module with an evolving working memory to solve downstream tasks. The compressor and reasoner are jointly optimized via end-to-end reinforcement learning, while the gating module is trained separately as a classifier. Experimental results show that the proposed method achieves competitive accuracy on multi-hop reasoning benchmarks such as RULER-HQA, extrapolates context length from 7K to 1.75M tokens, and offers a favorable accuracy-efficiency trade-off compared to strong long-context baselines. In particular, it achieves up to a 2 times reduction in peak GPU memory usage and a 6 times inference speedup over MemAgent.
LycheeDecode: Accelerating Long-Context LLM Inference via Hybrid-Head Sparse Decoding
Feb 04, 2026The proliferation of long-context large language models (LLMs) exposes a key bottleneck: the rapidly expanding key-value cache during decoding, which imposes heavy memory and latency costs. While recent approaches attempt to alleviate this by sharing a single set of crucial tokens across layers, such coarse-grained sharing undermines model performance by neglecting the functional diversity of attention heads. To address this, we propose LycheeDecode, an efficient decoding method centered on a fine-grained hybrid-head attention mechanism that employs a hardware-efficient top-k selection strategy. Specifically, the novel HardKuma-based mechanism partitions attention heads into a small subset of retrieval heads that dynamically identify crucial tokens and a majority of sparse heads that reuse them for efficient computation. Through extensive experiments on leading models like Llama3 and Qwen3 across diverse benchmarks for long-context understanding (e.g., LongBench, RULER) and complex reasoning (e.g., AIME24, OlympiadBench), we demonstrate that LycheeDecode achieves generative quality comparable to, and at times surpassing even the full-attention baseline. Crucially, this is accomplished with up to a 2.7x speedup at a 128K context length. By preserving the functional diversity of attention heads, our fine-grained strategy overcomes the performance bottlenecks of existing methods, providing a powerful and validated pathway to both efficient and high-quality long-context LLM inference.
Structured Episodic Event Memory
Jan 10, 2026Current approaches to memory in Large Language Models (LLMs) predominantly rely on static Retrieval-Augmented Generation (RAG), which often results in scattered retrieval and fails to capture the structural dependencies required for complex reasoning. For autonomous agents, these passive and flat architectures lack the cognitive organization necessary to model the dynamic and associative nature of long-term interaction. To address this, we propose Structured Episodic Event Memory (SEEM), a hierarchical framework that synergizes a graph memory layer for relational facts with a dynamic episodic memory layer for narrative progression. Grounded in cognitive frame theory, SEEM transforms interaction streams into structured Episodic Event Frames (EEFs) anchored by precise provenance pointers. Furthermore, we introduce an agentic associative fusion and Reverse Provenance Expansion (RPE) mechanism to reconstruct coherent narrative contexts from fragmented evidence. Experimental results on the LoCoMo and LongMemEval benchmarks demonstrate that SEEM significantly outperforms baselines, enabling agents to maintain superior narrative coherence and logical consistency.
KaLM-Embedding-V2: Superior Training Techniques and Data Inspire A Versatile Embedding Model
Jun 26, 2025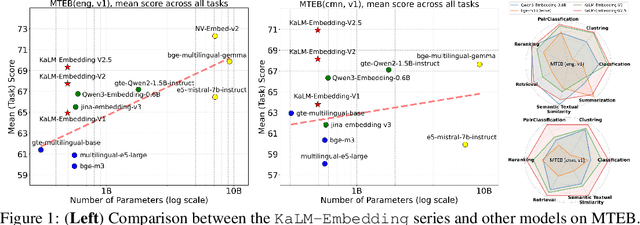
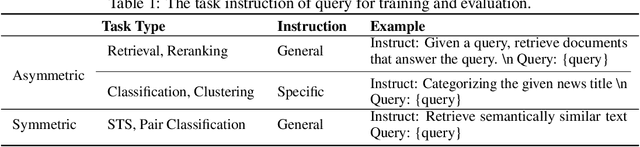

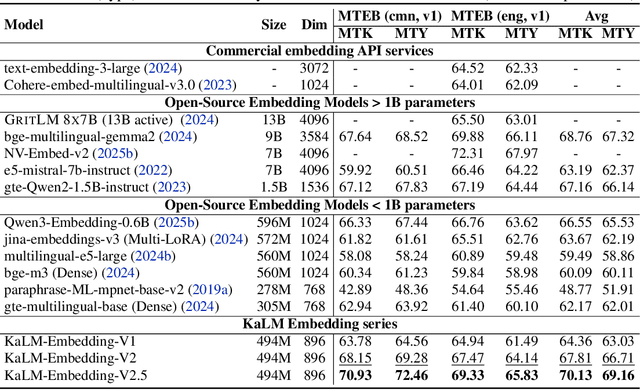
In this paper, we propose KaLM-Embedding-V2, a versatile and compact embedding model, which achieves impressive performance in general-purpose text embedding tasks by leveraging superior training techniques and data. Our key innovations include: (1) To better align the architecture with representation learning, we remove the causal attention mask and adopt a fully bidirectional transformer with simple yet effective mean-pooling to produce fixed-length embeddings; (2) We employ a multi-stage training pipeline: (i) pre-training on large-scale weakly supervised open-source corpora; (ii) fine-tuning on high-quality retrieval and non-retrieval datasets; and (iii) model-soup parameter averaging for robust generalization. Besides, we introduce a focal-style reweighting mechanism that concentrates learning on difficult samples and an online hard-negative mixing strategy to continuously enrich hard negatives without expensive offline mining; (3) We collect over 20 categories of data for pre-training and 100 categories of data for fine-tuning, to boost both the performance and generalization of the embedding model. Extensive evaluations on the Massive Text Embedding Benchmark (MTEB) Chinese and English show that our model significantly outperforms others of comparable size, and competes with 3x, 14x, 18x, and 26x larger embedding models, setting a new standard for a versatile and compact embedding model with less than 1B parameters.
Take Off the Training Wheels Progressive In-Context Learning for Effective Alignment
Mar 13, 2025



Recent studies have explored the working mechanisms of In-Context Learning (ICL). However, they mainly focus on classification and simple generation tasks, limiting their broader application to more complex generation tasks in practice. To address this gap, we investigate the impact of demonstrations on token representations within the practical alignment tasks. We find that the transformer embeds the task function learned from demonstrations into the separator token representation, which plays an important role in the generation of prior response tokens. Once the prior response tokens are determined, the demonstrations become redundant.Motivated by this finding, we propose an efficient Progressive In-Context Alignment (PICA) method consisting of two stages. In the first few-shot stage, the model generates several prior response tokens via standard ICL while concurrently extracting the ICL vector that stores the task function from the separator token representation. In the following zero-shot stage, this ICL vector guides the model to generate responses without further demonstrations.Extensive experiments demonstrate that our PICA not only surpasses vanilla ICL but also achieves comparable performance to other alignment tuning methods. The proposed training-free method reduces the time cost (e.g., 5.45+) with improved alignment performance (e.g., 6.57+). Consequently, our work highlights the application of ICL for alignment and calls for a deeper understanding of ICL for complex generations. The code will be available at https://github.com/HITsz-TMG/PICA.
Improving Value-based Process Verifier via Structural Prior Injection
Feb 21, 2025



In the Large Language Model(LLM) reasoning scenario, people often estimate state value via Monte Carlo sampling. Though Monte Carlo estimation is an elegant method with less inductive bias, noise and errors are inevitably introduced due to the limited sampling. To handle the problem, we inject the structural prior into the value representation and transfer the scalar value into the expectation of a pre-defined categorical distribution, representing the noise and errors from a distribution perspective. Specifically, by treating the result of Monte Carlo sampling as a single sample from the prior ground-truth Binomial distribution, we quantify the sampling error as the mismatch between posterior estimated distribution and ground-truth distribution, which is thus optimized via distribution selection optimization. We test the performance of value-based process verifiers on Best-of-N task and Beam search task. Compared with the scalar value representation, we show that reasonable structural prior injection induced by different objective functions or optimization methods can improve the performance of value-based process verifiers for about 1$\sim$2 points at little-to-no cost. We also show that under different structural prior, the verifiers' performances vary greatly despite having the same optimal solution, indicating the importance of reasonable structural prior injection.
KaLM-Embedding: Superior Training Data Brings A Stronger Embedding Model
Jan 03, 2025



As retrieval-augmented generation prevails in large language models, embedding models are becoming increasingly crucial. Despite the growing number of general embedding models, prior work often overlooks the critical role of training data quality. In this work, we introduce KaLM-Embedding, a general multilingual embedding model that leverages a large quantity of cleaner, more diverse, and domain-specific training data. Our model has been trained with key techniques proven to enhance performance: (1) persona-based synthetic data to create diversified examples distilled from LLMs, (2) ranking consistency filtering to remove less informative samples, and (3) semi-homogeneous task batch sampling to improve training efficacy. Departing from traditional BERT-like architectures, we adopt Qwen2-0.5B as the pre-trained model, facilitating the adaptation of auto-regressive language models for general embedding tasks. Extensive evaluations of the MTEB benchmark across multiple languages show that our model outperforms others of comparable size, setting a new standard for multilingual embedding models with <1B parameters.
CMT: A Memory Compression Method for Continual Knowledge Learning of Large Language Models
Dec 10, 2024



Large Language Models (LLMs) need to adapt to the continuous changes in data, tasks, and user preferences. Due to their massive size and the high costs associated with training, LLMs are not suitable for frequent retraining. However, updates are necessary to keep them in sync with rapidly evolving human knowledge. To address these challenges, this paper proposes the Compression Memory Training (CMT) method, an efficient and effective online adaptation framework for LLMs that features robust knowledge retention capabilities. Inspired by human memory mechanisms, CMT compresses and extracts information from new documents to be stored in a memory bank. When answering to queries related to these new documents, the model aggregates these document memories from the memory bank to better answer user questions. The parameters of the LLM itself do not change during training and inference, reducing the risk of catastrophic forgetting. To enhance the encoding, retrieval, and aggregation of memory, we further propose three new general and flexible techniques, including memory-aware objective, self-matching and top-aggregation. Extensive experiments conducted on three continual learning datasets (i.e., StreamingQA, SQuAD and ArchivalQA) demonstrate that the proposed method improves model adaptability and robustness across multiple base LLMs (e.g., +4.07 EM & +4.19 F1 in StreamingQA with Llama-2-7b).