 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEGL-SCA: Structural Credit Assignment for Co-Evolving Instructions and Tools in Graph Reasoning Agents
May 11, 2026Graph reasoning agents operating from natural-language inputs must solve a coupled problem: they must reconstruct a structured graph instance from text, decide whether existing computational assets are sufficient, interact with tools under a strict execution protocol, and satisfy an external verifier that checks structured correctness rather than textual plausibility. Existing approaches usually improve either the instruction side or the tool side in isolation, which leaves unclear what should be updated after failure. We propose EGL-SCA, a verifier-centric dual-space framework that models a graph reasoning agent using two collaborative components: an instruction-side policy space for reasoning strategies, and a tool-side program space for executable algorithmic tools. Our central mechanism is structural credit assignment, which maps trajectory evidence to conditional updates, precisely routing failures to either prompt optimization or tool synthesis and repair. To provide sufficient learning signals for dual-space adaptation, we introduce a training distribution stratified by task family, coupled with a Pareto-style retention strategy to balance success, generality, and parsimony. Experiments on four graph reasoning benchmarks show that EGL-SCA achieves a state-of-the-art 92.0\% average success rate. By effectively co-evolving instructions and tools, our framework significantly outperforms both pure-prompting and fixed-toolbox baselines.
CoDA: Towards Effective Cross-domain Knowledge Transfer via CoT-guided Domain Adaptation
Apr 21, 2026Large language models (LLMs) have achieved substantial advances in logical reasoning, yet they continue to lag behind human-level performance. In-context learning provides a viable solution that boosts the model's performance via prompting its input with expert-curated, in-domain exemplars. However, in many real-world, expertise-scarce domains, such as low-resource scientific disciplines, emerging biomedical subfields, or niche legal jurisdictions, such high-quality in-domain demonstrations are inherently limited or entirely unavailable, thereby constraining the general applicability of these approaches. To mitigate this limitation, recent efforts have explored the retrieval of cross-domain samples as surrogate in-context demonstrations. Nevertheless, the resulting gains remain modest. This is largely attributable to the pronounced domain shift between source and target distributions, which impedes the model's ability to effectively identify and exploit underlying shared structures or latent reasoning patterns. Consequently, when relying solely on raw textual prompting, LLMs struggle to abstract and transfer such cross-domain knowledge in a robust and systematic manner. To address these issues, we propose CoDA, which employs a lightweight adapter to directly intervene in the intermediate hidden states. By combining feature-based distillation of CoT-enriched reference representations with Maximum Mean Discrepancy (MMD) for kernelized distribution matching, our method aligns the latent reasoning representation of the source and target domains. Extensive experimental results on multiple logical reasoning tasks across various model families validate the efficacy of CoDA by significantly outperforming the previous state-of-the-art baselines by a large margin.
Towards Effective In-context Cross-domain Knowledge Transfer via Domain-invariant-neurons-based Retrieval
Apr 07, 2026Large language models (LLMs) have made notable progress in logical reasoning, yet still fall short of human-level performance. Current boosting strategies rely on expert-crafted in-domain demonstrations, limiting their applicability in expertise-scarce domains, such as specialized mathematical reasoning, formal logic, or legal analysis. In this work, we demonstrate the feasibility of leveraging cross-domain demonstrating examples to boost the LLMs' reasoning performance. Despite substantial domain differences, many reusable implicit logical structures are shared across domains. In order to effectively retrieve cross-domain examples for unseen domains under investigation, in this work, we further propose an effective retrieval method, called domain-invariant neurons-based retrieval (\textbf{DIN-Retrieval}). Concisely, DIN-Retrieval first summarizes a hidden representation that is universal across different domains. Then, during the inference stage, we use the DIN vector to retrieve structurally compatible cross-domain demonstrations for the in-context learning. Experimental results in multiple settings for the transfer of mathematical and logical reasoning demonstrate that our method achieves an average improvement of 1.8 over the state-of-the-art methods \footnote{Our implementation is available at https://github.com/Leon221220/DIN-Retrieval}.
Reason Analogically via Cross-domain Prior Knowledge: An Empirical Study of Cross-domain Knowledge Transfer for In-Context Learning
Apr 07, 2026Despite its success, existing in-context learning (ICL) relies on in-domain expert demonstrations, limiting its applicability when expert annotations are scarce. We posit that different domains may share underlying reasoning structures, enabling source-domain demonstrations to improve target-domain inference despite semantic mismatch. To test this hypothesis, we conduct a comprehensive empirical study of different retrieval methods to validate the feasibility of achieving cross-domain knowledge transfer under the in-context learning setting. Our results demonstrate conditional positive transfer in cross-domain ICL. We identify a clear example absorption threshold: beyond it, positive transfer becomes more likely, and additional demonstrations yield larger gains. Further analysis suggests that these gains stem from reasoning structure repair by retrieved cross-domain examples, rather than semantic cues. Overall, our study validates the feasibility of leveraging cross-domain knowledge transfer to improve cross-domain ICL performance, motivating the community to explore designing more effective retrieval approaches for this novel direction.\footnote{Our implementation is available at https://github.com/littlelaska/ICL-TF4LR}
LSA: A Long-Short-term Aspect Interest Transformer for Aspect-Based Recommendation
Mar 22, 2026Aspect-based recommendation methods extract aspect terms from reviews, such as price, to model fine-grained user preferences on items, making them a critical approach in personalized recommender systems. Existing methods utilize graphs to represent the relationships among users, items, and aspect terms, modeling user preferences based on graph neural networks. However, they overlook the dynamic nature of user interests - users may temporarily focus on aspects they previously paid little attention to - making it difficult to assign accurate weights to aspect terms for each user-item interaction. In this paper, we propose a long-short-term aspect interest Transformer (LSA) for aspect-based recommendation, which effectively captures the dynamic nature of user preferences by integrating both long-term and short-term aspect interests. Specifically, the short-term interests model the temporal changes in the importance of recently interacted aspect terms, while the long-term interests consider global behavioral patterns, including aspects that users have not interacted with recently. Finally, LSA combines long- and short-term interests to evaluate the importance of aspects within the union of user and item aspect neighbors, therefore accurately assigns aspect weights for each user-item interaction. Experiments conducted on four real-world datasets demonstrate that LSA improves MSE by 2.55% on average over the best baseline.
Fairness risk and its privacy-enabled solution in AI-driven robotic applications
Jan 13, 2026Complex decision-making by autonomous machines and algorithms could underpin the foundations of future society. Generative AI is emerging as a powerful engine for such transitions. However, we show that Generative AI-driven developments pose a critical pitfall: fairness concerns. In robotic applications, although intuitions about fairness are common, a precise and implementable definition that captures user utility and inherent data randomness is missing. Here we provide a utility-aware fairness metric for robotic decision making and analyze fairness jointly with user-data privacy, deriving conditions under which privacy budgets govern fairness metrics. This yields a unified framework that formalizes and quantifies fairness and its interplay with privacy, which is tested in a robot navigation task. In view of the fact that under legal requirements, most robotic systems will enforce user privacy, the approach shows surprisingly that such privacy budgets can be jointly used to meet fairness targets. Addressing fairness concerns in the creative combined consideration of privacy is a step towards ethical use of AI and strengthens trust in autonomous robots deployed in everyday environments.
Privacy protection under the exposure of systems' prior information
Nov 13, 2025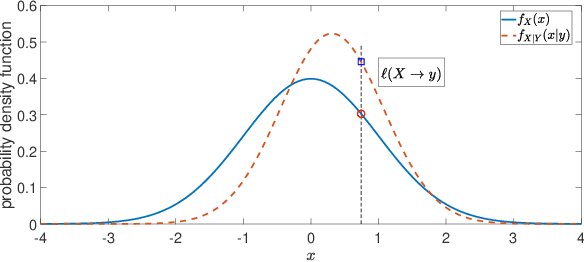
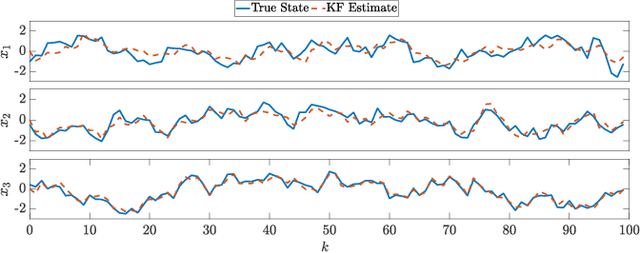
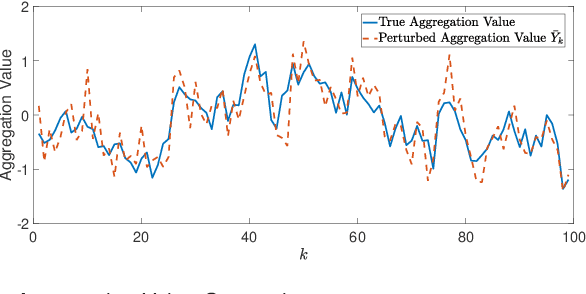
For systems whose states implicate sensitive information, their privacy is of great concern. While notions like differential privacy have been successfully introduced to dynamical systems, it is still unclear how a system's privacy can be properly protected when facing the challenging yet frequently-encountered scenario where an adversary possesses prior knowledge, e.g., the steady state, of the system. This paper presents a new systematic approach to protect the privacy of a discrete-time linear time-invariant system against adversaries knowledgeable of the system's prior information. We employ a tailored \emph{pointwise maximal leakage (PML) privacy} criterion. PML characterizes the worst-case privacy performance, which is sharply different from that of the better-known mutual-information privacy. We derive necessary and sufficient conditions for PML privacy and construct tractable design procedures. Furthermore, our analysis leads to insight into how PML privacy, differential privacy, and mutual-information privacy are related. We then revisit Kalman filters from the perspective of PML privacy and derive a lower bound on the steady-state estimation-error covariance in terms of the PML parameters. Finally, the derived results are illustrated in a case study of privacy protection for distributed sensing in smart buildings.
From Long to Lean: Performance-aware and Adaptive Chain-of-Thought Compression via Multi-round Refinement
Sep 26, 2025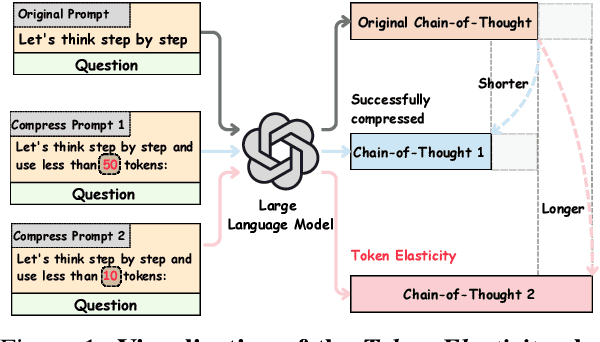
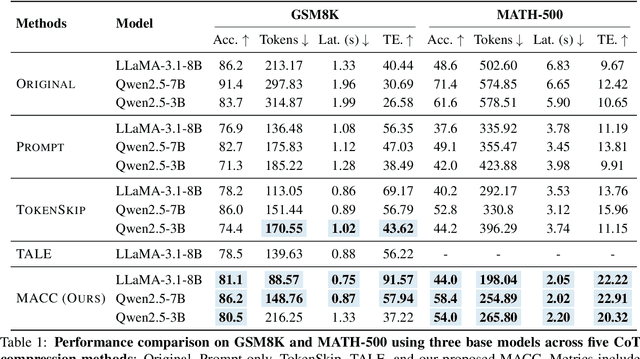
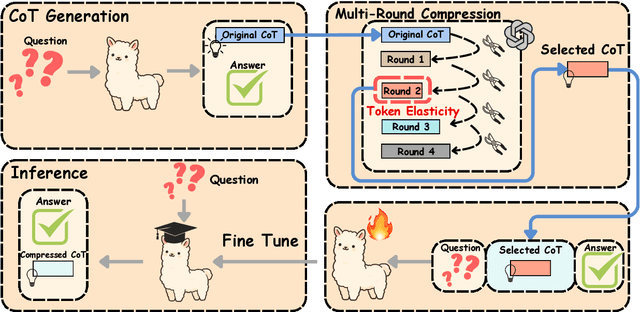
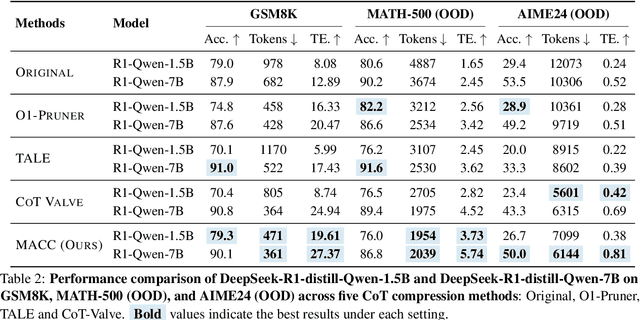
Chain-of-Thought (CoT) reasoning improves performance on complex tasks but introduces significant inference latency due to verbosity. We propose Multiround Adaptive Chain-of-Thought Compression (MACC), a framework that leverages the token elasticity phenomenon--where overly small token budgets can paradoxically increase output length--to progressively compress CoTs via multiround refinement. This adaptive strategy allows MACC to determine the optimal compression depth for each input. Our method achieves an average accuracy improvement of 5.6 percent over state-of-the-art baselines, while also reducing CoT length by an average of 47 tokens and significantly lowering latency. Furthermore, we show that test-time performance--accuracy and token length--can be reliably predicted using interpretable features like perplexity and compression rate on the training set. Evaluated across different models, our method enables efficient model selection and forecasting without repeated fine-tuning, demonstrating that CoT compression is both effective and predictable. Our code will be released in https://github.com/Leon221220/MACC.
BrainZ-BP: A Non-invasive Cuff-less Blood Pressure Estimation Approach Leveraging Brain Bio-impedance and Electrocardiogram
Nov 23, 2023



Accurate and continuous blood pressure (BP) monitoring is essential to the early prevention of cardiovascular diseases. Non-invasive and cuff-less BP estimation algorithm has gained much attention in recent years. Previous studies have demonstrated that brain bio-impedance (BIOZ) is a promising technique for non-invasive intracranial pressure (ICP) monitoring. Clinically, treatment for patients with traumatic brain injuries (TBI) requires monitoring the ICP and BP of patients simultaneously. Estimating BP by brain BIOZ directly can reduce the number of sensors attached to the patients, thus improving their comfort. To address the issues, in this study, we explore the feasibility of leveraging brain BIOZ for BP estimation and propose a novel cuff-less BP estimation approach called BrainZ-BP. Two electrodes are placed on the forehead and occipital bone of the head in the anterior-posterior direction for brain BIOZ measurement. Various features including pulse transit time and morphological features of brain BIOZ are extracted and fed into four regression models for BP estimation. Results show that the mean absolute error, root mean square error, and correlation coefficient of random forest regression model are 2.17 mmHg, 3.91 mmHg, and 0.90 for systolic pressure estimation, and are 1.71 mmHg, 3.02 mmHg, and 0.89 for diastolic pressure estimation. The presented BrainZ-BP can be applied in the brain BIOZ-based ICP monitoring scenario to monitor BP simultaneously.
Multi-Level Features Contrastive Networks for Unsupervised Domain Adaptation
Sep 14, 2021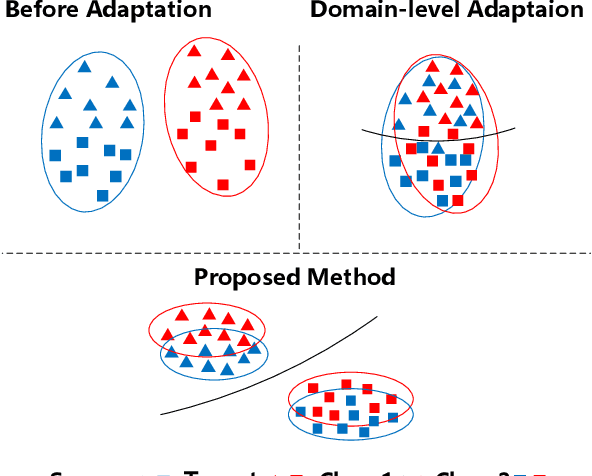
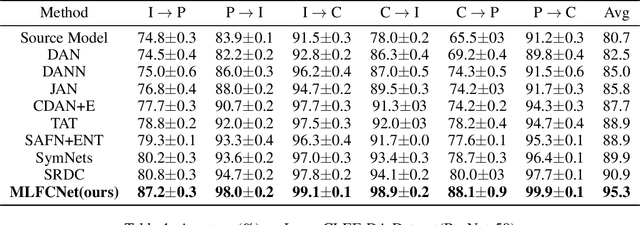
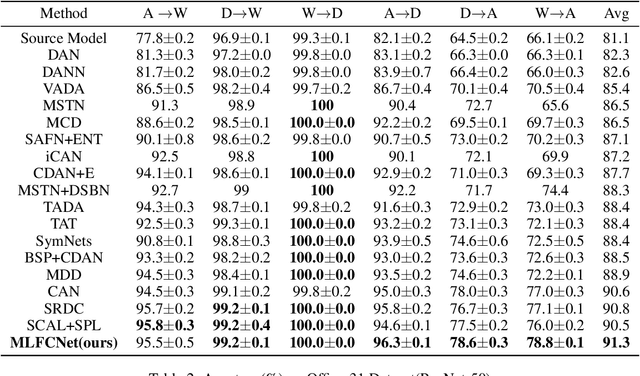
Unsupervised domain adaptation aims to train a model from the labeled source domain to make predictions on the unlabeled target domain when the data distribution of the two domains is different. As a result, it needs to reduce the data distribution difference between the two domains to improve the model's generalization ability. Existing methods tend to align the two domains directly at the domain-level, or perform class-level domain alignment based on deep feature. The former ignores the relationship between the various classes in the two domains, which may cause serious negative transfer, the latter alleviates it by introducing pseudo-labels of the target domain, but it does not consider the importance of performing class-level alignment on shallow feature representations. In this paper, we develop this work on the method of class-level alignment. The proposed method reduces the difference between two domains dramaticlly by aligning multi-level features. In the case that the two domains share the label space, the class-level alignment is implemented by introducing Multi-Level Feature Contrastive Networks (MLFCNet). In practice, since the categories of samples in target domain are unavailable, we iteratively use clustering algorithm to obtain the pseudo-labels, and then minimize Multi-Level Contrastive Discrepancy (MLCD) loss to achieve more accurate class-level alignment. Experiments on three real-world benchmarks ImageCLEF-DA, Office-31 and Office-Home demonstrate that MLFCNet compares favorably against the existing state-of-the-art domain adaptation methods.