 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEGL-SCA: Structural Credit Assignment for Co-Evolving Instructions and Tools in Graph Reasoning Agents
May 11, 2026Graph reasoning agents operating from natural-language inputs must solve a coupled problem: they must reconstruct a structured graph instance from text, decide whether existing computational assets are sufficient, interact with tools under a strict execution protocol, and satisfy an external verifier that checks structured correctness rather than textual plausibility. Existing approaches usually improve either the instruction side or the tool side in isolation, which leaves unclear what should be updated after failure. We propose EGL-SCA, a verifier-centric dual-space framework that models a graph reasoning agent using two collaborative components: an instruction-side policy space for reasoning strategies, and a tool-side program space for executable algorithmic tools. Our central mechanism is structural credit assignment, which maps trajectory evidence to conditional updates, precisely routing failures to either prompt optimization or tool synthesis and repair. To provide sufficient learning signals for dual-space adaptation, we introduce a training distribution stratified by task family, coupled with a Pareto-style retention strategy to balance success, generality, and parsimony. Experiments on four graph reasoning benchmarks show that EGL-SCA achieves a state-of-the-art 92.0\% average success rate. By effectively co-evolving instructions and tools, our framework significantly outperforms both pure-prompting and fixed-toolbox baselines.
CoDA: Towards Effective Cross-domain Knowledge Transfer via CoT-guided Domain Adaptation
Apr 21, 2026Large language models (LLMs) have achieved substantial advances in logical reasoning, yet they continue to lag behind human-level performance. In-context learning provides a viable solution that boosts the model's performance via prompting its input with expert-curated, in-domain exemplars. However, in many real-world, expertise-scarce domains, such as low-resource scientific disciplines, emerging biomedical subfields, or niche legal jurisdictions, such high-quality in-domain demonstrations are inherently limited or entirely unavailable, thereby constraining the general applicability of these approaches. To mitigate this limitation, recent efforts have explored the retrieval of cross-domain samples as surrogate in-context demonstrations. Nevertheless, the resulting gains remain modest. This is largely attributable to the pronounced domain shift between source and target distributions, which impedes the model's ability to effectively identify and exploit underlying shared structures or latent reasoning patterns. Consequently, when relying solely on raw textual prompting, LLMs struggle to abstract and transfer such cross-domain knowledge in a robust and systematic manner. To address these issues, we propose CoDA, which employs a lightweight adapter to directly intervene in the intermediate hidden states. By combining feature-based distillation of CoT-enriched reference representations with Maximum Mean Discrepancy (MMD) for kernelized distribution matching, our method aligns the latent reasoning representation of the source and target domains. Extensive experimental results on multiple logical reasoning tasks across various model families validate the efficacy of CoDA by significantly outperforming the previous state-of-the-art baselines by a large margin.
Reason Analogically via Cross-domain Prior Knowledge: An Empirical Study of Cross-domain Knowledge Transfer for In-Context Learning
Apr 07, 2026Despite its success, existing in-context learning (ICL) relies on in-domain expert demonstrations, limiting its applicability when expert annotations are scarce. We posit that different domains may share underlying reasoning structures, enabling source-domain demonstrations to improve target-domain inference despite semantic mismatch. To test this hypothesis, we conduct a comprehensive empirical study of different retrieval methods to validate the feasibility of achieving cross-domain knowledge transfer under the in-context learning setting. Our results demonstrate conditional positive transfer in cross-domain ICL. We identify a clear example absorption threshold: beyond it, positive transfer becomes more likely, and additional demonstrations yield larger gains. Further analysis suggests that these gains stem from reasoning structure repair by retrieved cross-domain examples, rather than semantic cues. Overall, our study validates the feasibility of leveraging cross-domain knowledge transfer to improve cross-domain ICL performance, motivating the community to explore designing more effective retrieval approaches for this novel direction.\footnote{Our implementation is available at https://github.com/littlelaska/ICL-TF4LR}
Towards Effective In-context Cross-domain Knowledge Transfer via Domain-invariant-neurons-based Retrieval
Apr 07, 2026Large language models (LLMs) have made notable progress in logical reasoning, yet still fall short of human-level performance. Current boosting strategies rely on expert-crafted in-domain demonstrations, limiting their applicability in expertise-scarce domains, such as specialized mathematical reasoning, formal logic, or legal analysis. In this work, we demonstrate the feasibility of leveraging cross-domain demonstrating examples to boost the LLMs' reasoning performance. Despite substantial domain differences, many reusable implicit logical structures are shared across domains. In order to effectively retrieve cross-domain examples for unseen domains under investigation, in this work, we further propose an effective retrieval method, called domain-invariant neurons-based retrieval (\textbf{DIN-Retrieval}). Concisely, DIN-Retrieval first summarizes a hidden representation that is universal across different domains. Then, during the inference stage, we use the DIN vector to retrieve structurally compatible cross-domain demonstrations for the in-context learning. Experimental results in multiple settings for the transfer of mathematical and logical reasoning demonstrate that our method achieves an average improvement of 1.8 over the state-of-the-art methods \footnote{Our implementation is available at https://github.com/Leon221220/DIN-Retrieval}.
From Long to Lean: Performance-aware and Adaptive Chain-of-Thought Compression via Multi-round Refinement
Sep 26, 2025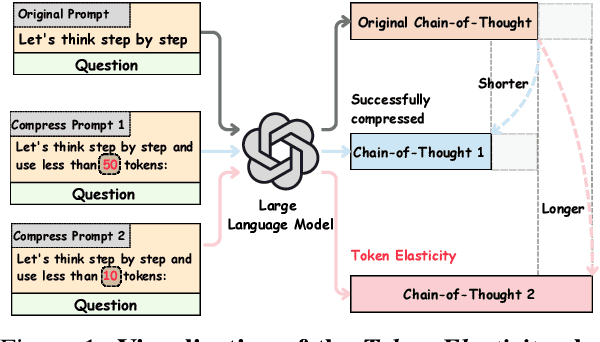
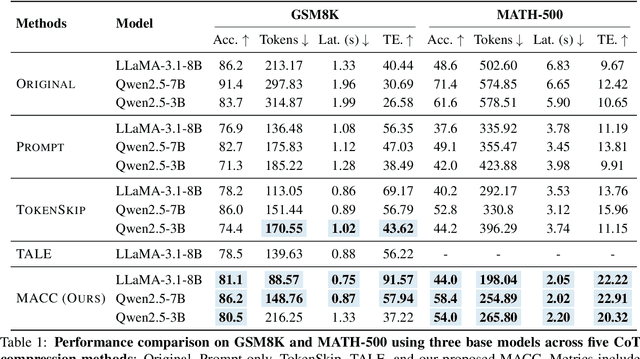
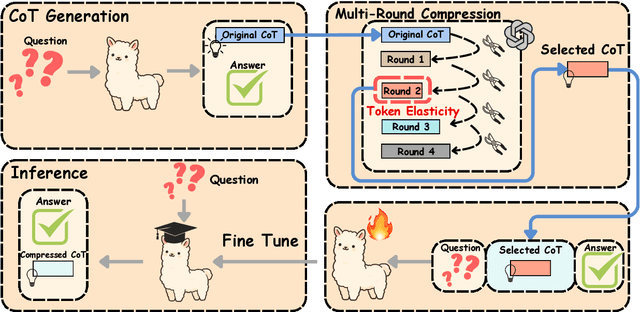
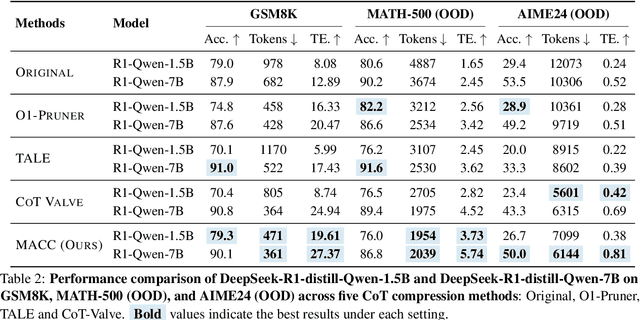
Chain-of-Thought (CoT) reasoning improves performance on complex tasks but introduces significant inference latency due to verbosity. We propose Multiround Adaptive Chain-of-Thought Compression (MACC), a framework that leverages the token elasticity phenomenon--where overly small token budgets can paradoxically increase output length--to progressively compress CoTs via multiround refinement. This adaptive strategy allows MACC to determine the optimal compression depth for each input. Our method achieves an average accuracy improvement of 5.6 percent over state-of-the-art baselines, while also reducing CoT length by an average of 47 tokens and significantly lowering latency. Furthermore, we show that test-time performance--accuracy and token length--can be reliably predicted using interpretable features like perplexity and compression rate on the training set. Evaluated across different models, our method enables efficient model selection and forecasting without repeated fine-tuning, demonstrating that CoT compression is both effective and predictable. Our code will be released in https://github.com/Leon221220/MACC.