 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEGL-SCA: Structural Credit Assignment for Co-Evolving Instructions and Tools in Graph Reasoning Agents
May 11, 2026Graph reasoning agents operating from natural-language inputs must solve a coupled problem: they must reconstruct a structured graph instance from text, decide whether existing computational assets are sufficient, interact with tools under a strict execution protocol, and satisfy an external verifier that checks structured correctness rather than textual plausibility. Existing approaches usually improve either the instruction side or the tool side in isolation, which leaves unclear what should be updated after failure. We propose EGL-SCA, a verifier-centric dual-space framework that models a graph reasoning agent using two collaborative components: an instruction-side policy space for reasoning strategies, and a tool-side program space for executable algorithmic tools. Our central mechanism is structural credit assignment, which maps trajectory evidence to conditional updates, precisely routing failures to either prompt optimization or tool synthesis and repair. To provide sufficient learning signals for dual-space adaptation, we introduce a training distribution stratified by task family, coupled with a Pareto-style retention strategy to balance success, generality, and parsimony. Experiments on four graph reasoning benchmarks show that EGL-SCA achieves a state-of-the-art 92.0\% average success rate. By effectively co-evolving instructions and tools, our framework significantly outperforms both pure-prompting and fixed-toolbox baselines.
Reason Analogically via Cross-domain Prior Knowledge: An Empirical Study of Cross-domain Knowledge Transfer for In-Context Learning
Apr 07, 2026Despite its success, existing in-context learning (ICL) relies on in-domain expert demonstrations, limiting its applicability when expert annotations are scarce. We posit that different domains may share underlying reasoning structures, enabling source-domain demonstrations to improve target-domain inference despite semantic mismatch. To test this hypothesis, we conduct a comprehensive empirical study of different retrieval methods to validate the feasibility of achieving cross-domain knowledge transfer under the in-context learning setting. Our results demonstrate conditional positive transfer in cross-domain ICL. We identify a clear example absorption threshold: beyond it, positive transfer becomes more likely, and additional demonstrations yield larger gains. Further analysis suggests that these gains stem from reasoning structure repair by retrieved cross-domain examples, rather than semantic cues. Overall, our study validates the feasibility of leveraging cross-domain knowledge transfer to improve cross-domain ICL performance, motivating the community to explore designing more effective retrieval approaches for this novel direction.\footnote{Our implementation is available at https://github.com/littlelaska/ICL-TF4LR}
Towards Effective In-context Cross-domain Knowledge Transfer via Domain-invariant-neurons-based Retrieval
Apr 07, 2026Large language models (LLMs) have made notable progress in logical reasoning, yet still fall short of human-level performance. Current boosting strategies rely on expert-crafted in-domain demonstrations, limiting their applicability in expertise-scarce domains, such as specialized mathematical reasoning, formal logic, or legal analysis. In this work, we demonstrate the feasibility of leveraging cross-domain demonstrating examples to boost the LLMs' reasoning performance. Despite substantial domain differences, many reusable implicit logical structures are shared across domains. In order to effectively retrieve cross-domain examples for unseen domains under investigation, in this work, we further propose an effective retrieval method, called domain-invariant neurons-based retrieval (\textbf{DIN-Retrieval}). Concisely, DIN-Retrieval first summarizes a hidden representation that is universal across different domains. Then, during the inference stage, we use the DIN vector to retrieve structurally compatible cross-domain demonstrations for the in-context learning. Experimental results in multiple settings for the transfer of mathematical and logical reasoning demonstrate that our method achieves an average improvement of 1.8 over the state-of-the-art methods \footnote{Our implementation is available at https://github.com/Leon221220/DIN-Retrieval}.
From Long to Lean: Performance-aware and Adaptive Chain-of-Thought Compression via Multi-round Refinement
Sep 26, 2025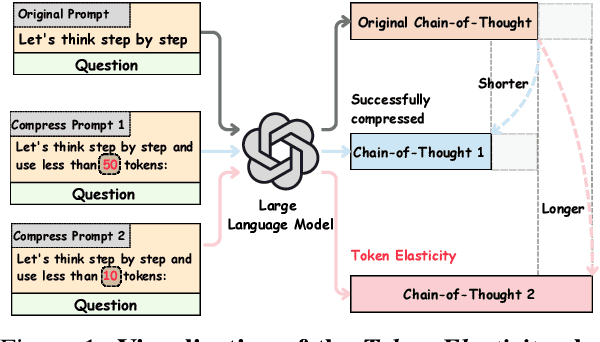
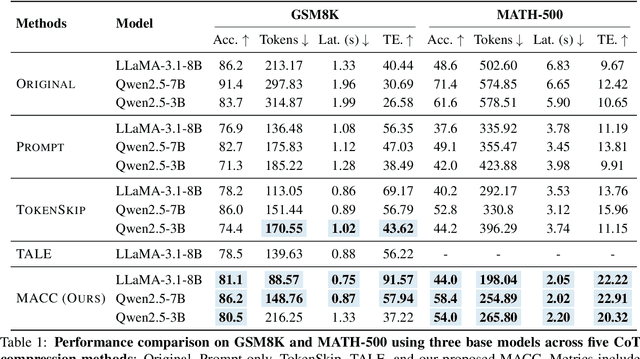
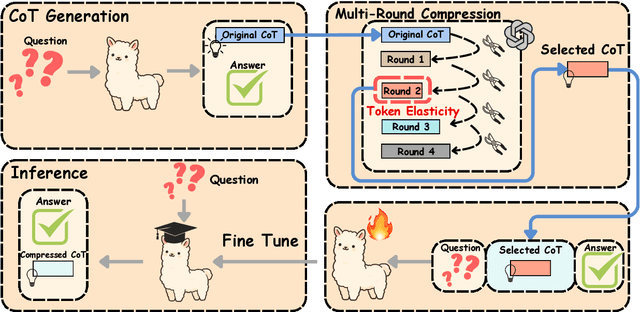
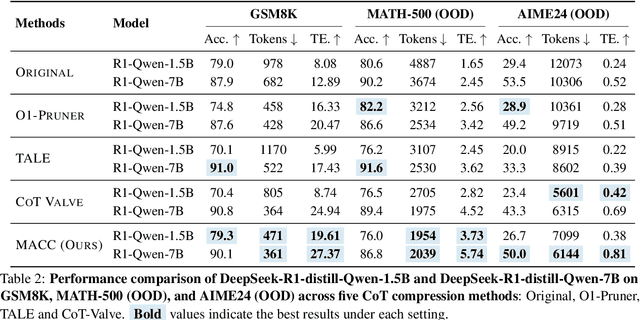
Chain-of-Thought (CoT) reasoning improves performance on complex tasks but introduces significant inference latency due to verbosity. We propose Multiround Adaptive Chain-of-Thought Compression (MACC), a framework that leverages the token elasticity phenomenon--where overly small token budgets can paradoxically increase output length--to progressively compress CoTs via multiround refinement. This adaptive strategy allows MACC to determine the optimal compression depth for each input. Our method achieves an average accuracy improvement of 5.6 percent over state-of-the-art baselines, while also reducing CoT length by an average of 47 tokens and significantly lowering latency. Furthermore, we show that test-time performance--accuracy and token length--can be reliably predicted using interpretable features like perplexity and compression rate on the training set. Evaluated across different models, our method enables efficient model selection and forecasting without repeated fine-tuning, demonstrating that CoT compression is both effective and predictable. Our code will be released in https://github.com/Leon221220/MACC.
MA-GTS: A Multi-Agent Framework for Solving Complex Graph Problems in Real-World Applications
Feb 25, 2025



Graph-theoretic problems arise in real-world applications like logistics, communication networks, and traffic optimization. These problems are often complex, noisy, and irregular, posing challenges for traditional algorithms. Large language models (LLMs) offer potential solutions but face challenges, including limited accuracy and input length constraints. To address these challenges, we propose MA-GTS (Multi-Agent Graph Theory Solver), a multi-agent framework that decomposes these complex problems through agent collaboration. MA-GTS maps the implicitly expressed text-based graph data into clear, structured graph representations and dynamically selects the most suitable algorithm based on problem constraints and graph structure scale. This approach ensures that the solution process remains efficient and the resulting reasoning path is interpretable. We validate MA-GTS using the G-REAL dataset, a real-world-inspired graph theory dataset we created. Experimental results show that MA-GTS outperforms state-of-the-art approaches in terms of efficiency, accuracy, and scalability, with strong results across multiple benchmarks (G-REAL 94.2%, GraCoRe 96.9%, NLGraph 98.4%).MA-GTS is open-sourced at https://github.com/ZIKEYUAN/MA-GTS.git.
GraCoRe: Benchmarking Graph Comprehension and Complex Reasoning in Large Language Models
Jul 03, 2024Evaluating the graph comprehension and reasoning abilities of Large Language Models (LLMs) is challenging and often incomplete. Existing benchmarks focus primarily on pure graph understanding, lacking a comprehensive evaluation across all graph types and detailed capability definitions. This paper presents GraCoRe, a benchmark for systematically assessing LLMs' graph comprehension and reasoning. GraCoRe uses a three-tier hierarchical taxonomy to categorize and test models on pure graph and heterogeneous graphs, subdividing capabilities into 10 distinct areas tested through 19 tasks. Our benchmark includes 11 datasets with 5,140 graphs of varying complexity. We evaluated three closed-source and seven open-source LLMs, conducting thorough analyses from both ability and task perspectives. Key findings reveal that semantic enrichment enhances reasoning performance, node ordering impacts task success, and the ability to process longer texts does not necessarily improve graph comprehension or reasoning. GraCoRe is open-sourced at https://github.com/ZIKEYUAN/GraCoRe
PowerGear: Early-Stage Power Estimation in FPGA HLS via Heterogeneous Edge-Centric GNNs
Jan 25, 2022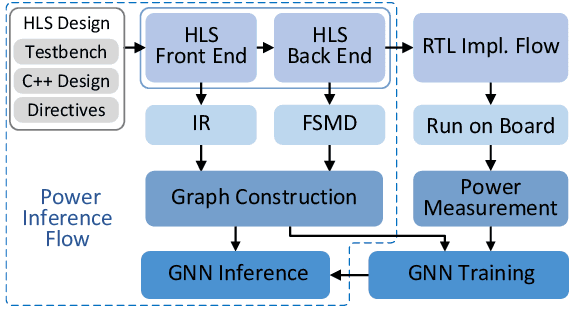
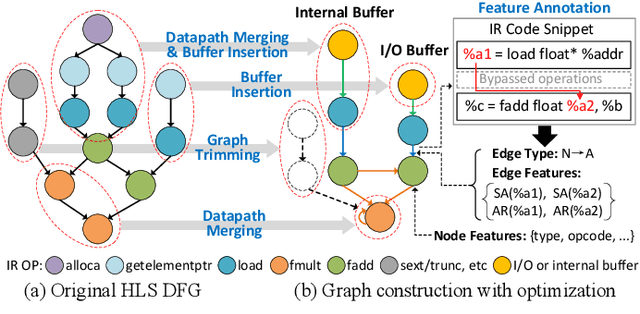
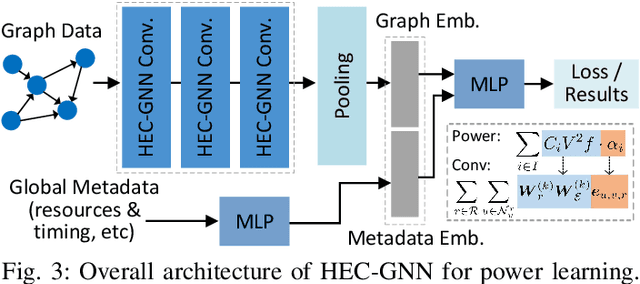
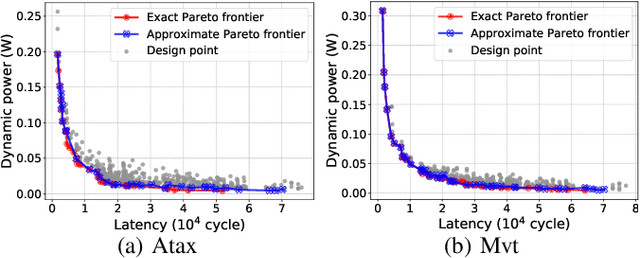
Power estimation is the basis of many hardware optimization strategies. However, it is still challenging to offer accurate power estimation at an early stage such as high-level synthesis (HLS). In this paper, we propose PowerGear, a graph-learning-assisted power estimation approach for FPGA HLS, which features high accuracy, efficiency and transferability. PowerGear comprises two main components: a graph construction flow and a customized graph neural network (GNN) model. Specifically, in the graph construction flow, we introduce buffer insertion, datapath merging, graph trimming and feature annotation techniques to transform HLS designs into graph-structured data, which encode both intra-operation micro-architectures and inter-operation interconnects annotated with switching activities. Furthermore, we propose a novel power-aware heterogeneous edge-centric GNN model which effectively learns heterogeneous edge semantics and structural properties of the constructed graphs via edge-centric neighborhood aggregation, and fits the formulation of dynamic power. Compared with on-board measurement, PowerGear estimates total and dynamic power for new HLS designs with errors of 3.60% and 8.81%, respectively, which outperforms the prior arts in research and the commercial product Vivado. In addition, PowerGear demonstrates a speedup of 4x over Vivado power estimator. Finally, we present a case study in which PowerGear is exploited to facilitate design space exploration for FPGA HLS, leading to a performance gain of up to 11.2%, compared with methods using state-of-the-art predictive models.