 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Roadmap for Big Model
Apr 02, 2022



With the rapid development of deep learning, training Big Models (BMs) for multiple downstream tasks becomes a popular paradigm. Researchers have achieved various outcomes in the construction of BMs and the BM application in many fields. At present, there is a lack of research work that sorts out the overall progress of BMs and guides the follow-up research. In this paper, we cover not only the BM technologies themselves but also the prerequisites for BM training and applications with BMs, dividing the BM review into four parts: Resource, Models, Key Technologies and Application. We introduce 16 specific BM-related topics in those four parts, they are Data, Knowledge, Computing System, Parallel Training System, Language Model, Vision Model, Multi-modal Model, Theory&Interpretability, Commonsense Reasoning, Reliability&Security, Governance, Evaluation, Machine Translation, Text Generation, Dialogue and Protein Research. In each topic, we summarize clearly the current studies and propose some future research directions. At the end of this paper, we conclude the further development of BMs in a more general view.
LiDAR Distillation: Bridging the Beam-Induced Domain Gap for 3D Object Detection
Mar 28, 2022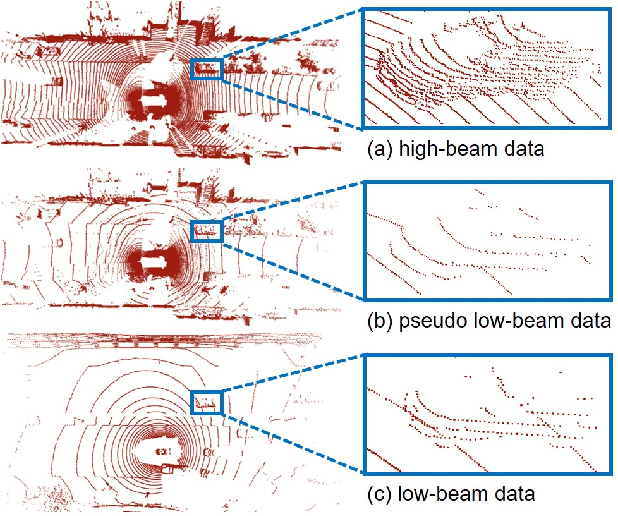
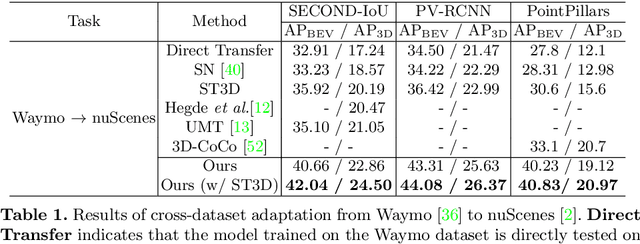
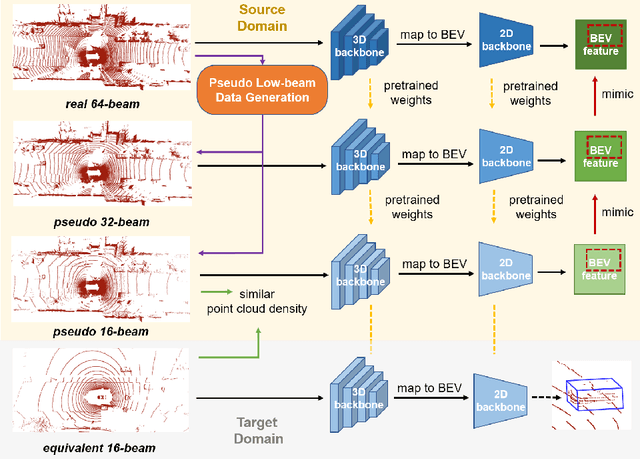

In this paper, we propose the LiDAR Distillation to bridge the domain gap induced by different LiDAR beams for 3D object detection. In many real-world applications, the LiDAR points used by mass-produced robots and vehicles usually have fewer beams than that in large-scale public datasets. Moreover, as the LiDARs are upgraded to other product models with different beam amount, it becomes challenging to utilize the labeled data captured by previous versions' high-resolution sensors. Despite the recent progress on domain adaptive 3D detection, most methods struggle to eliminate the beam-induced domain gap. We find that it is essential to align the point cloud density of the source domain with that of the target domain during the training process. Inspired by this discovery, we propose a progressive framework to mitigate the beam-induced domain shift. In each iteration, we first generate low-beam pseudo LiDAR by downsampling the high-beam point clouds. Then the teacher-student framework is employed to distill rich information from the data with more beams. Extensive experiments on Waymo, nuScenes and KITTI datasets with three different LiDAR-based detectors demonstrate the effectiveness of our LiDAR Distillation. Notably, our approach does not increase any additional computation cost for inference.
Back to Reality: Weakly-supervised 3D Object Detection with Shape-guided Label Enhancement
Mar 27, 2022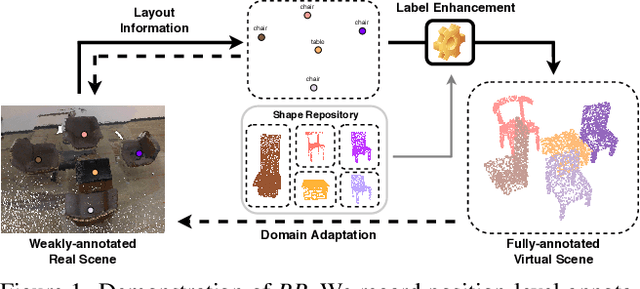

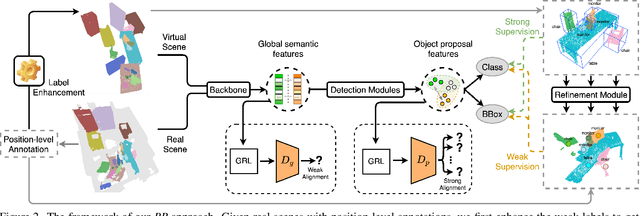

In this paper, we propose a weakly-supervised approach for 3D object detection, which makes it possible to train a strong 3D detector with position-level annotations (i.e. annotations of object centers). In order to remedy the information loss from box annotations to centers, our method, namely Back to Reality (BR), makes use of synthetic 3D shapes to convert the weak labels into fully-annotated virtual scenes as stronger supervision, and in turn utilizes the perfect virtual labels to complement and refine the real labels. Specifically, we first assemble 3D shapes into physically reasonable virtual scenes according to the coarse scene layout extracted from position-level annotations. Then we go back to reality by applying a virtual-to-real domain adaptation method, which refine the weak labels and additionally supervise the training of detector with the virtual scenes. Furthermore, we propose a more challenging benckmark for indoor 3D object detection with more diversity in object sizes to better show the potential of BR. With less than 5% of the labeling labor, we achieve comparable detection performance with some popular fully-supervised approaches on the widely used ScanNet dataset. Code is available at: https://github.com/wyf-ACCEPT/BackToReality
Stochastic Trajectory Prediction via Motion Indeterminacy Diffusion
Mar 25, 2022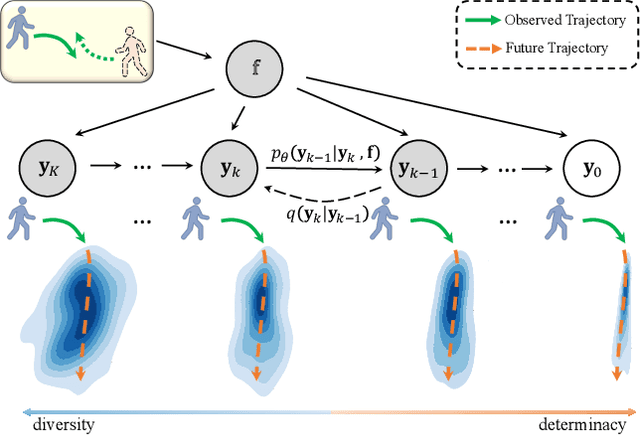
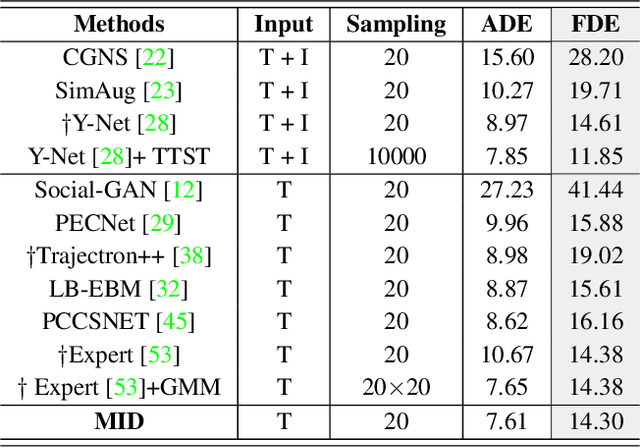
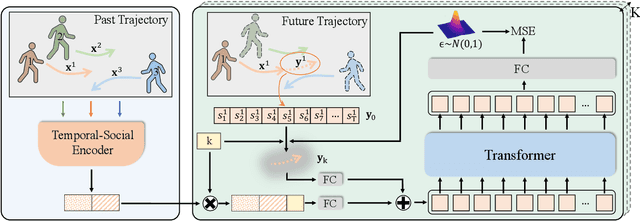
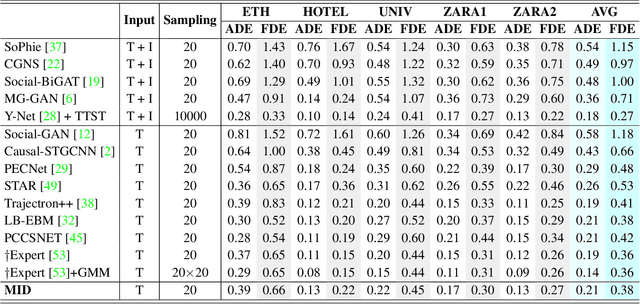
Human behavior has the nature of indeterminacy, which requires the pedestrian trajectory prediction system to model the multi-modality of future motion states. Unlike existing stochastic trajectory prediction methods which usually use a latent variable to represent multi-modality, we explicitly simulate the process of human motion variation from indeterminate to determinate. In this paper, we present a new framework to formulate the trajectory prediction task as a reverse process of motion indeterminacy diffusion (MID), in which we progressively discard indeterminacy from all the walkable areas until reaching the desired trajectory. This process is learned with a parameterized Markov chain conditioned by the observed trajectories. We can adjust the length of the chain to control the degree of indeterminacy and balance the diversity and determinacy of the predictions. Specifically, we encode the history behavior information and the social interactions as a state embedding and devise a Transformer-based diffusion model to capture the temporal dependencies of trajectories. Extensive experiments on the human trajectory prediction benchmarks including the Stanford Drone and ETH/UCY datasets demonstrate the superiority of our method. Code is available at https://github.com/gutianpei/MID.
Multi-View Partial Point Cloud Challenge 2021 on Completion and Registration: Methods and Results
Dec 22, 2021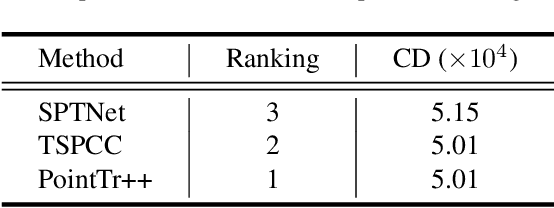
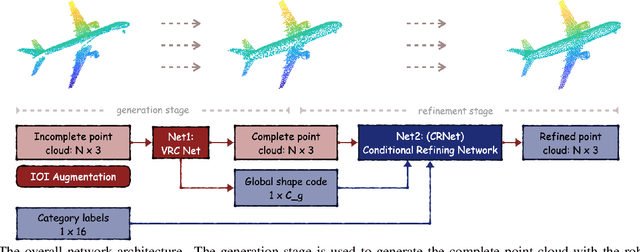
As real-scanned point clouds are mostly partial due to occlusions and viewpoints, reconstructing complete 3D shapes based on incomplete observations becomes a fundamental problem for computer vision. With a single incomplete point cloud, it becomes the partial point cloud completion problem. Given multiple different observations, 3D reconstruction can be addressed by performing partial-to-partial point cloud registration. Recently, a large-scale Multi-View Partial (MVP) point cloud dataset has been released, which consists of over 100,000 high-quality virtual-scanned partial point clouds. Based on the MVP dataset, this paper reports methods and results in the Multi-View Partial Point Cloud Challenge 2021 on Completion and Registration. In total, 128 participants registered for the competition, and 31 teams made valid submissions. The top-ranked solutions will be analyzed, and then we will discuss future research directions.
DenseCLIP: Language-Guided Dense Prediction with Context-Aware Prompting
Dec 02, 2021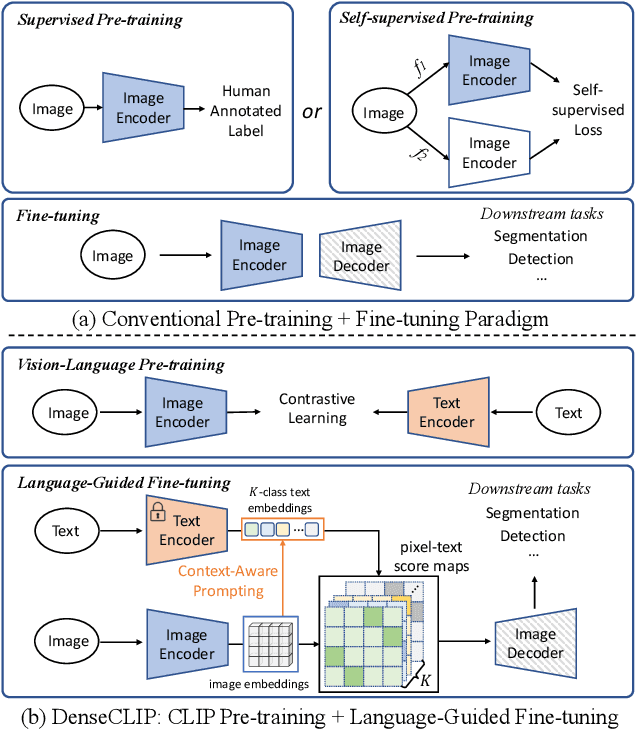
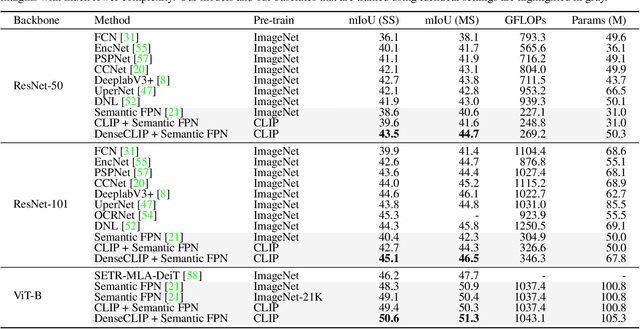
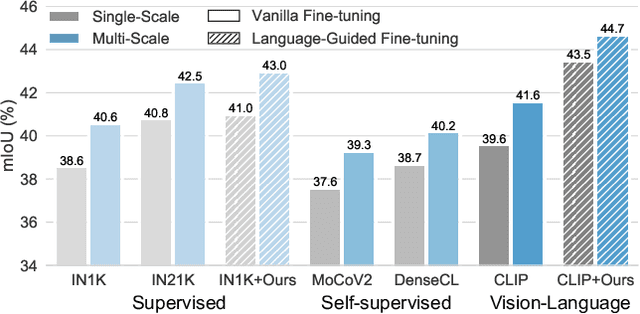

Recent progress has shown that large-scale pre-training using contrastive image-text pairs can be a promising alternative for high-quality visual representation learning from natural language supervision. Benefiting from a broader source of supervision, this new paradigm exhibits impressive transferability to downstream classification tasks and datasets. However, the problem of transferring the knowledge learned from image-text pairs to more complex dense prediction tasks has barely been visited. In this work, we present a new framework for dense prediction by implicitly and explicitly leveraging the pre-trained knowledge from CLIP. Specifically, we convert the original image-text matching problem in CLIP to a pixel-text matching problem and use the pixel-text score maps to guide the learning of dense prediction models. By further using the contextual information from the image to prompt the language model, we are able to facilitate our model to better exploit the pre-trained knowledge. Our method is model-agnostic, which can be applied to arbitrary dense prediction systems and various pre-trained visual backbones including both CLIP models and ImageNet pre-trained models. Extensive experiments demonstrate the superior performance of our methods on semantic segmentation, object detection, and instance segmentation tasks. Code is available at https://github.com/raoyongming/DenseCLIP
Point-BERT: Pre-training 3D Point Cloud Transformers with Masked Point Modeling
Nov 29, 2021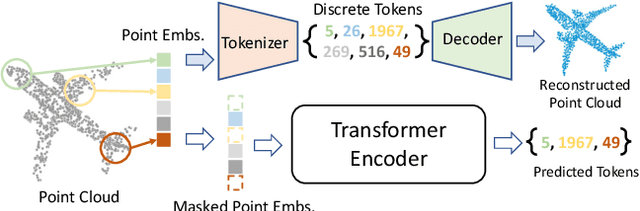
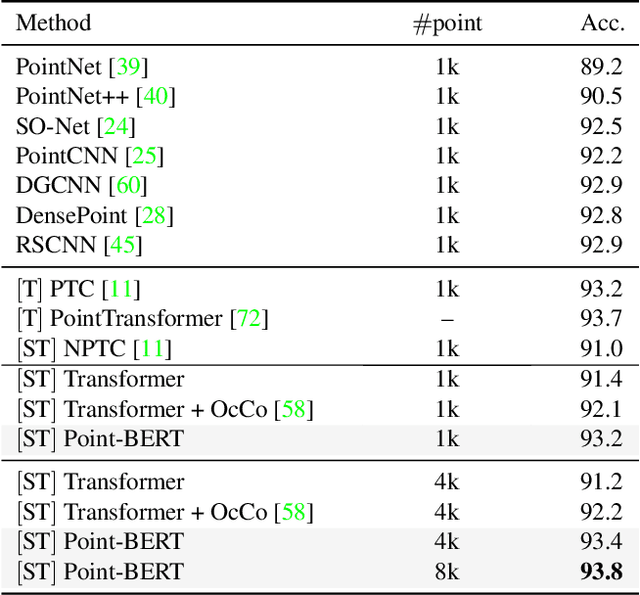
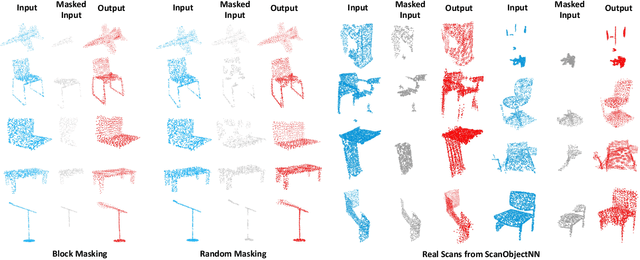
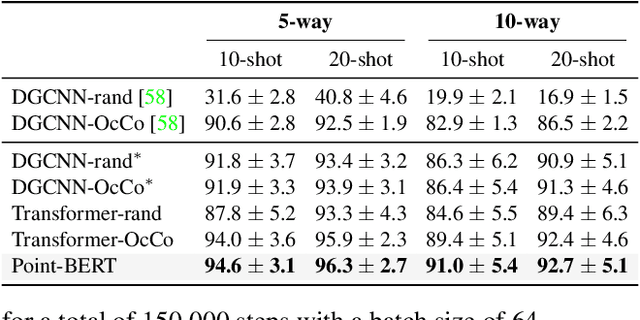
We present Point-BERT, a new paradigm for learning Transformers to generalize the concept of BERT to 3D point cloud. Inspired by BERT, we devise a Masked Point Modeling (MPM) task to pre-train point cloud Transformers. Specifically, we first divide a point cloud into several local point patches, and a point cloud Tokenizer with a discrete Variational AutoEncoder (dVAE) is designed to generate discrete point tokens containing meaningful local information. Then, we randomly mask out some patches of input point clouds and feed them into the backbone Transformers. The pre-training objective is to recover the original point tokens at the masked locations under the supervision of point tokens obtained by the Tokenizer. Extensive experiments demonstrate that the proposed BERT-style pre-training strategy significantly improves the performance of standard point cloud Transformers. Equipped with our pre-training strategy, we show that a pure Transformer architecture attains 93.8% accuracy on ModelNet40 and 83.1% accuracy on the hardest setting of ScanObjectNN, surpassing carefully designed point cloud models with much fewer hand-made designs. We also demonstrate that the representations learned by Point-BERT transfer well to new tasks and domains, where our models largely advance the state-of-the-art of few-shot point cloud classification task. The code and pre-trained models are available at https://github.com/lulutang0608/Point-BERT
Structure-Preserving Image Super-Resolution
Sep 26, 2021
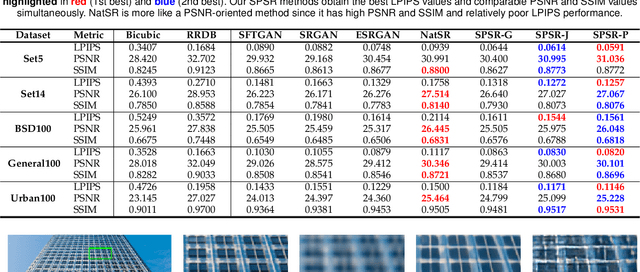
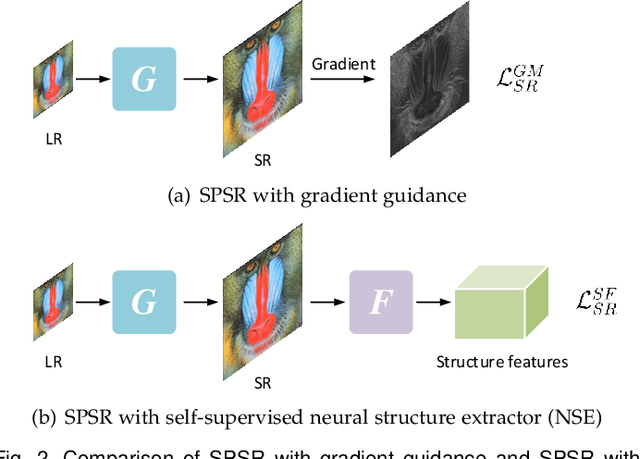

Structures matter in single image super-resolution (SISR). Benefiting from generative adversarial networks (GANs), recent studies have promoted the development of SISR by recovering photo-realistic images. However, there are still undesired structural distortions in the recovered images. In this paper, we propose a structure-preserving super-resolution (SPSR) method to alleviate the above issue while maintaining the merits of GAN-based methods to generate perceptual-pleasant details. Firstly, we propose SPSR with gradient guidance (SPSR-G) by exploiting gradient maps of images to guide the recovery in two aspects. On the one hand, we restore high-resolution gradient maps by a gradient branch to provide additional structure priors for the SR process. On the other hand, we propose a gradient loss to impose a second-order restriction on the super-resolved images, which helps generative networks concentrate more on geometric structures. Secondly, since the gradient maps are handcrafted and may only be able to capture limited aspects of structural information, we further extend SPSR-G by introducing a learnable neural structure extractor (NSE) to unearth richer local structures and provide stronger supervision for SR. We propose two self-supervised structure learning methods, contrastive prediction and solving jigsaw puzzles, to train the NSEs. Our methods are model-agnostic, which can be potentially used for off-the-shelf SR networks. Experimental results on five benchmark datasets show that the proposed methods outperform state-of-the-art perceptual-driven SR methods under LPIPS, PSNR, and SSIM metrics. Visual results demonstrate the superiority of our methods in restoring structures while generating natural SR images. Code is available at https://github.com/Maclory/SPSR.
NerfingMVS: Guided Optimization of Neural Radiance Fields for Indoor Multi-view Stereo
Sep 03, 2021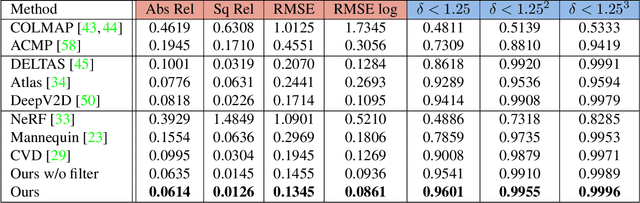
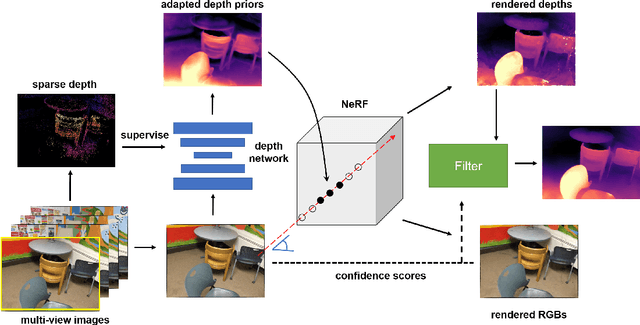
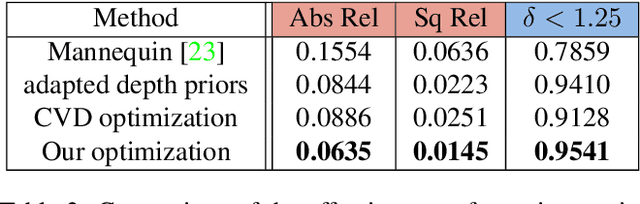
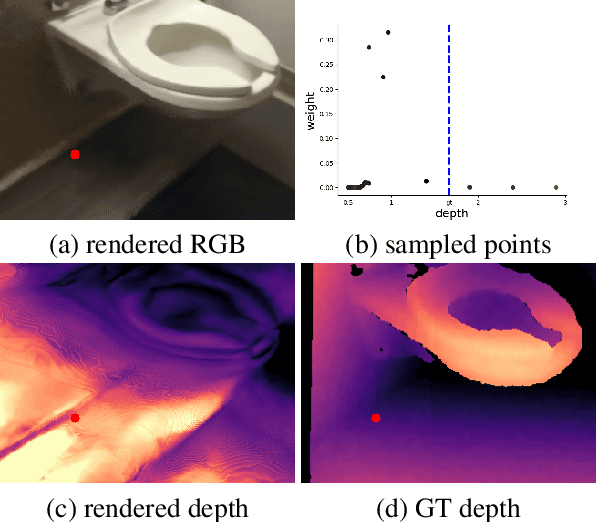
In this work, we present a new multi-view depth estimation method that utilizes both conventional SfM reconstruction and learning-based priors over the recently proposed neural radiance fields (NeRF). Unlike existing neural network based optimization method that relies on estimated correspondences, our method directly optimizes over implicit volumes, eliminating the challenging step of matching pixels in indoor scenes. The key to our approach is to utilize the learning-based priors to guide the optimization process of NeRF. Our system firstly adapts a monocular depth network over the target scene by finetuning on its sparse SfM reconstruction. Then, we show that the shape-radiance ambiguity of NeRF still exists in indoor environments and propose to address the issue by employing the adapted depth priors to monitor the sampling process of volume rendering. Finally, a per-pixel confidence map acquired by error computation on the rendered image can be used to further improve the depth quality. Experiments show that our proposed framework significantly outperforms state-of-the-art methods on indoor scenes, with surprising findings presented on the effectiveness of correspondence-based optimization and NeRF-based optimization over the adapted depth priors. In addition, we show that the guided optimization scheme does not sacrifice the original synthesis capability of neural radiance fields, improving the rendering quality on both seen and novel views. Code is available at https://github.com/weiyithu/NerfingMVS.
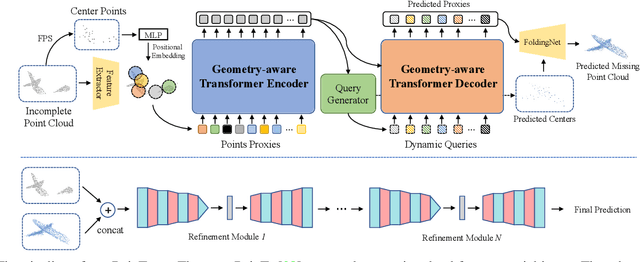
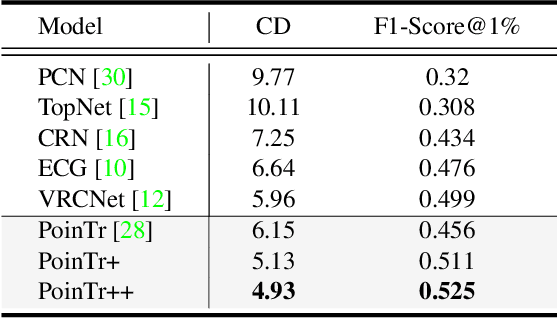
PoinTr: Diverse Point Cloud Completion with Geometry-Aware Transformers
Aug 19, 2021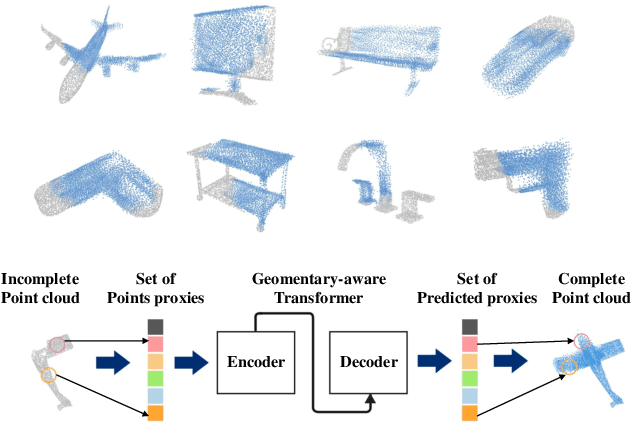

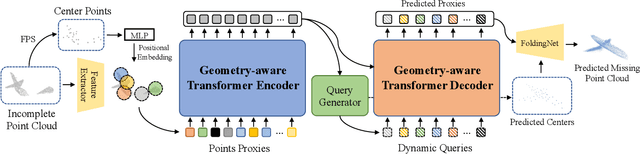
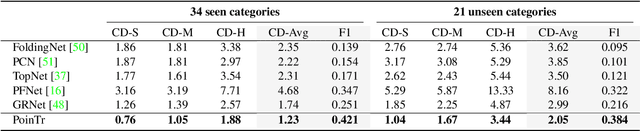
Point clouds captured in real-world applications are often incomplete due to the limited sensor resolution, single viewpoint, and occlusion. Therefore, recovering the complete point clouds from partial ones becomes an indispensable task in many practical applications. In this paper, we present a new method that reformulates point cloud completion as a set-to-set translation problem and design a new model, called PoinTr that adopts a transformer encoder-decoder architecture for point cloud completion. By representing the point cloud as a set of unordered groups of points with position embeddings, we convert the point cloud to a sequence of point proxies and employ the transformers for point cloud generation. To facilitate transformers to better leverage the inductive bias about 3D geometric structures of point clouds, we further devise a geometry-aware block that models the local geometric relationships explicitly. The migration of transformers enables our model to better learn structural knowledge and preserve detailed information for point cloud completion. Furthermore, we propose two more challenging benchmarks with more diverse incomplete point clouds that can better reflect the real-world scenarios to promote future research. Experimental results show that our method outperforms state-of-the-art methods by a large margin on both the new benchmarks and the existing ones. Code is available at https://github.com/yuxumin/PoinTr