 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEvent Stream-based Visual Object Tracking: HDETrack V2 and A High-Definition Benchmark
Feb 08, 2025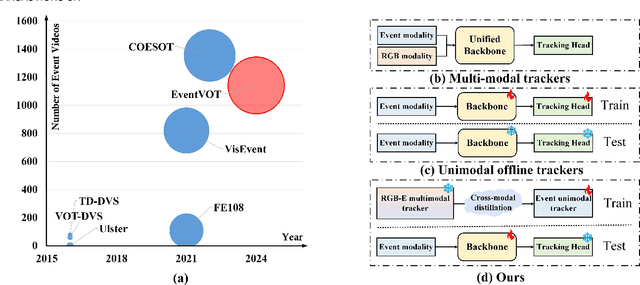

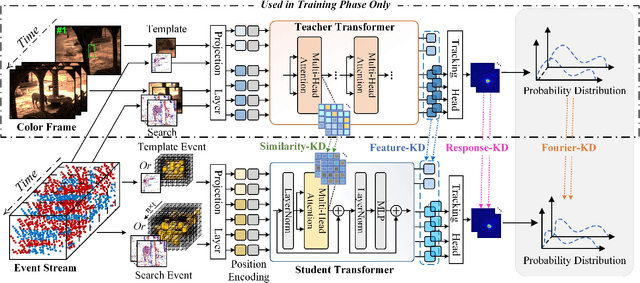

We then introduce a novel hierarchical knowledge distillation strategy that incorporates the similarity matrix, feature representation, and response map-based distillation to guide the learning of the student Transformer network. We also enhance the model's ability to capture temporal dependencies by applying the temporal Fourier transform to establish temporal relationships between video frames. We adapt the network model to specific target objects during testing via a newly proposed test-time tuning strategy to achieve high performance and flexibility in target tracking. Recognizing the limitations of existing event-based tracking datasets, which are predominantly low-resolution, we propose EventVOT, the first large-scale high-resolution event-based tracking dataset. It comprises 1141 videos spanning diverse categories such as pedestrians, vehicles, UAVs, ping pong, etc. Extensive experiments on both low-resolution (FE240hz, VisEvent, FELT), and our newly proposed high-resolution EventVOT dataset fully validated the effectiveness of our proposed method. Both the benchmark dataset and source code have been released on https://github.com/Event-AHU/EventVOT_Benchmark
Channel-wise Parallelizable Spiking Neuron with Multiplication-free Dynamics and Large Temporal Receptive Fields
Jan 24, 2025Spiking Neural Networks (SNNs) are distinguished from Artificial Neural Networks (ANNs) for their sophisticated neuronal dynamics and sparse binary activations (spikes) inspired by the biological neural system. Traditional neuron models use iterative step-by-step dynamics, resulting in serial computation and slow training speed of SNNs. Recently, parallelizable spiking neuron models have been proposed to fully utilize the massive parallel computing ability of graphics processing units to accelerate the training of SNNs. However, existing parallelizable spiking neuron models involve dense floating operations and can only achieve high long-term dependencies learning ability with a large order at the cost of huge computational and memory costs. To solve the dilemma of performance and costs, we propose the mul-free channel-wise Parallel Spiking Neuron, which is hardware-friendly and suitable for SNNs' resource-restricted application scenarios. The proposed neuron imports the channel-wise convolution to enhance the learning ability, induces the sawtooth dilations to reduce the neuron order, and employs the bit shift operation to avoid multiplications. The algorithm for design and implementation of acceleration methods is discussed meticulously. Our methods are validated in neuromorphic Spiking Heidelberg Digits voices, sequential CIFAR images, and neuromorphic DVS-Lip vision datasets, achieving the best accuracy among SNNs. Training speed results demonstrate the effectiveness of our acceleration methods, providing a practical reference for future research.
Language-Inspired Relation Transfer for Few-shot Class-Incremental Learning
Jan 10, 2025



Depicting novel classes with language descriptions by observing few-shot samples is inherent in human-learning systems. This lifelong learning capability helps to distinguish new knowledge from old ones through the increase of open-world learning, namely Few-Shot Class-Incremental Learning (FSCIL). Existing works to solve this problem mainly rely on the careful tuning of visual encoders, which shows an evident trade-off between the base knowledge and incremental ones. Motivated by human learning systems, we propose a new Language-inspired Relation Transfer (LRT) paradigm to understand objects by joint visual clues and text depictions, composed of two major steps. We first transfer the pretrained text knowledge to the visual domains by proposing a graph relation transformation module and then fuse the visual and language embedding by a text-vision prototypical fusion module. Second, to mitigate the domain gap caused by visual finetuning, we propose context prompt learning for fast domain alignment and imagined contrastive learning to alleviate the insufficient text data during alignment. With collaborative learning of domain alignments and text-image transfer, our proposed LRT outperforms the state-of-the-art models by over $13\%$ and $7\%$ on the final session of mini-ImageNet and CIFAR-100 FSCIL benchmarks.
Solving the Catastrophic Forgetting Problem in Generalized Category Discovery
Jan 09, 2025Generalized Category Discovery (GCD) aims to identify a mix of known and novel categories within unlabeled data sets, providing a more realistic setting for image recognition. Essentially, GCD needs to remember existing patterns thoroughly to recognize novel categories. Recent state-of-the-art method SimGCD transfers the knowledge from known-class data to the learning of novel classes through debiased learning. However, some patterns are catastrophically forgot during adaptation and thus lead to poor performance in novel categories classification. To address this issue, we propose a novel learning approach, LegoGCD, which is seamlessly integrated into previous methods to enhance the discrimination of novel classes while maintaining performance on previously encountered known classes. Specifically, we design two types of techniques termed as Local Entropy Regularization (LER) and Dual-views Kullback Leibler divergence constraint (DKL). The LER optimizes the distribution of potential known class samples in unlabeled data, thus ensuring the preservation of knowledge related to known categories while learning novel classes. Meanwhile, DKL introduces Kullback Leibler divergence to encourage the model to produce a similar prediction distribution of two view samples from the same image. In this way, it successfully avoids mismatched prediction and generates more reliable potential known class samples simultaneously. Extensive experiments validate that the proposed LegoGCD effectively addresses the known category forgetting issue across all datasets, eg, delivering a 7.74% and 2.51% accuracy boost on known and novel classes in CUB, respectively. Our code is available at: https://github.com/Cliffia123/LegoGCD.
Activating Associative Disease-Aware Vision Token Memory for LLM-Based X-ray Report Generation
Jan 07, 2025



X-ray image based medical report generation achieves significant progress in recent years with the help of the large language model, however, these models have not fully exploited the effective information in visual image regions, resulting in reports that are linguistically sound but insufficient in describing key diseases. In this paper, we propose a novel associative memory-enhanced X-ray report generation model that effectively mimics the process of professional doctors writing medical reports. It considers both the mining of global and local visual information and associates historical report information to better complete the writing of the current report. Specifically, given an X-ray image, we first utilize a classification model along with its activation maps to accomplish the mining of visual regions highly associated with diseases and the learning of disease query tokens. Then, we employ a visual Hopfield network to establish memory associations for disease-related tokens, and a report Hopfield network to retrieve report memory information. This process facilitates the generation of high-quality reports based on a large language model and achieves state-of-the-art performance on multiple benchmark datasets, including the IU X-ray, MIMIC-CXR, and Chexpert Plus. The source code of this work is released on \url{https://github.com/Event-AHU/Medical_Image_Analysis}.
AE-NeRF: Augmenting Event-Based Neural Radiance Fields for Non-ideal Conditions and Larger Scene
Jan 07, 2025Compared to frame-based methods, computational neuromorphic imaging using event cameras offers significant advantages, such as minimal motion blur, enhanced temporal resolution, and high dynamic range. The multi-view consistency of Neural Radiance Fields combined with the unique benefits of event cameras, has spurred recent research into reconstructing NeRF from data captured by moving event cameras. While showing impressive performance, existing methods rely on ideal conditions with the availability of uniform and high-quality event sequences and accurate camera poses, and mainly focus on the object level reconstruction, thus limiting their practical applications. In this work, we propose AE-NeRF to address the challenges of learning event-based NeRF from non-ideal conditions, including non-uniform event sequences, noisy poses, and various scales of scenes. Our method exploits the density of event streams and jointly learn a pose correction module with an event-based NeRF (e-NeRF) framework for robust 3D reconstruction from inaccurate camera poses. To generalize to larger scenes, we propose hierarchical event distillation with a proposal e-NeRF network and a vanilla e-NeRF network to resample and refine the reconstruction process. We further propose an event reconstruction loss and a temporal loss to improve the view consistency of the reconstructed scene. We established a comprehensive benchmark that includes large-scale scenes to simulate practical non-ideal conditions, incorporating both synthetic and challenging real-world event datasets. The experimental results show that our method achieves a new state-of-the-art in event-based 3D reconstruction.
VELoRA: A Low-Rank Adaptation Approach for Efficient RGB-Event based Recognition
Dec 28, 2024



Pattern recognition leveraging both RGB and Event cameras can significantly enhance performance by deploying deep neural networks that utilize a fine-tuning strategy. Inspired by the successful application of large models, the introduction of such large models can also be considered to further enhance the performance of multi-modal tasks. However, fully fine-tuning these models leads to inefficiency and lightweight fine-tuning methods such as LoRA and Adapter have been proposed to achieve a better balance between efficiency and performance. To our knowledge, there is currently no work that has conducted parameter-efficient fine-tuning (PEFT) for RGB-Event recognition based on pre-trained foundation models. To address this issue, this paper proposes a novel PEFT strategy to adapt the pre-trained foundation vision models for the RGB-Event-based classification. Specifically, given the RGB frames and event streams, we extract the RGB and event features based on the vision foundation model ViT with a modality-specific LoRA tuning strategy. The frame difference of the dual modalities is also considered to capture the motion cues via the frame difference backbone network. These features are concatenated and fed into high-level Transformer layers for efficient multi-modal feature learning via modality-shared LoRA tuning. Finally, we concatenate these features and feed them into a classification head to achieve efficient fine-tuning. The source code and pre-trained models will be released on \url{https://github.com/Event-AHU/VELoRA}.
RoomPainter: View-Integrated Diffusion for Consistent Indoor Scene Texturing
Dec 21, 2024Indoor scene texture synthesis has garnered significant interest due to its important potential applications in virtual reality, digital media, and creative arts. Existing diffusion model-based researches either rely on per-view inpainting techniques, which are plagued by severe cross-view inconsistencies and conspicuous seams, or they resort to optimization-based approaches that entail substantial computational overhead. In this work, we present RoomPainter, a framework that seamlessly integrates efficiency and consistency to achieve high-fidelity texturing of indoor scenes. The core of RoomPainter features a zero-shot technique that effectively adapts a 2D diffusion model for 3D-consistent texture synthesis, along with a two-stage generation strategy that ensures both global and local consistency. Specifically, we introduce Attention-Guided Multi-View Integrated Sampling (MVIS) combined with a neighbor-integrated attention mechanism for zero-shot texture map generation. Using the MVIS, we firstly generate texture map for the entire room to ensure global consistency, then adopt its variant, namely an attention-guided multi-view integrated repaint sampling (MVRS) to repaint individual instances within the room, thereby further enhancing local consistency. Experiments demonstrate that RoomPainter achieves superior performance for indoor scene texture synthesis in visual quality, global consistency, and generation efficiency.
High-speed and High-quality Vision Reconstruction of Spike Camera with Spike Stability Theorem
Dec 16, 2024



Neuromorphic vision sensors, such as the dynamic vision sensor (DVS) and spike camera, have gained increasing attention in recent years. The spike camera can detect fine textures by mimicking the fovea in the human visual system, and output a high-frequency spike stream. Real-time high-quality vision reconstruction from the spike stream can build a bridge to high-level vision task applications of the spike camera. To realize high-speed and high-quality vision reconstruction of the spike camera, we propose a new spike stability theorem that reveals the relationship between spike stream characteristics and stable light intensity. Based on the spike stability theorem, two parameter-free algorithms are designed for the real-time vision reconstruction of the spike camera. To demonstrate the performances of our algorithms, two datasets (a public dataset PKU-Spike-High-Speed and a newly constructed dataset SpikeCityPCL) are used to compare the reconstruction quality and speed of various reconstruction methods. Experimental results show that, compared with the current state-of-the-art (SOTA) reconstruction methods, our reconstruction methods obtain the best tradeoff between the reconstruction quality and speed. Additionally, we design the FPGA implementation method of our algorithms to realize the real-time (running at 20,000 FPS) visual reconstruction. Our work provides new theorem and algorithm foundations for the real-time edge-end vision processing of the spike camera.
A High Energy-Efficiency Multi-core Neuromorphic Architecture for Deep SNN Training
Dec 10, 2024



There is a growing necessity for edge training to adapt to dynamically changing environment. Neuromorphic computing represents a significant pathway for high-efficiency intelligent computation in energy-constrained edges, but existing neuromorphic architectures lack the ability of directly training spiking neural networks (SNNs) based on backpropagation. We develop a multi-core neuromorphic architecture with Feedforward-Propagation, Back-Propagation, and Weight-Gradient engines in each core, supporting high efficient parallel computing at both the engine and core levels. It combines various data flows and sparse computation optimization by fully leveraging the sparsity in SNN training, obtaining a high energy efficiency of 1.05TFLOPS/W@ FP16 @ 28nm, 55 ~ 85% reduction of DRAM access compared to A100 GPU in SNN trainings, and a 20-core deep SNN training and a 5-worker federated learning on FPGAs. Our study develops the first multi-core neuromorphic architecture supporting the direct SNN training, facilitating the neuromorphic computing in edge-learnable applications.