 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePolarVSR: A Unified Framework and Benchmark for Continuous Space-Time Polarization Video Reconstruction
May 11, 2026Polarimetric imaging captures surface polarization characteristics, such as the Degree of Linear Polarization (DoLP) and the Angle of Polarization (AoP). In mainstream Division of-Focal-Plane (DoFP) color polarization imaging, recovering polarization parameters from captured mosaic arrays remains a challenging inverse problem. Existing DoFP cameras also face hardware bottlenecks and often cannot support high-frame-rate acquisition, limiting polarimetric imaging in dynamic video tasks. These limitations motivate joint spatial and temporal enhancement. To this end, we propose the first space-time polarization video reconstruction architecture. The method jointly models polarization directions in space and time and uses a polarization-aware implicit neural representation for continuous, high-fidelity upsampling. By analyzing temporal variations in polarization parameters, we further introduce a flow-guided polarization variation loss to supervise polarization dynamics. We also establish the first large-scale color DoFP polarization video benchmark to support this research direction. Extensive experiments on this benchmark demonstrate the effectiveness of the method.
Single-Stage Signal Attenuation Diffusion Model for Low-Light Image Enhancement and Denoising
Apr 07, 2026Diffusion models excel at image restoration via probabilistic modeling of forward noise addition and reverse denoising, and their ability to handle complex noise while preserving fine details makes them well-suited for Low-Light Image Enhancement (LLIE). Mainstream diffusion based LLIE methods either adopt a two-stage pipeline or an auxiliary correction network to refine U-Net outputs, which severs the intrinsic link between enhancement and denoising and leads to suboptimal performance owing to inconsistent optimization objectives. To address these issues, we propose the Signal Attenuation Diffusion Model (SADM), a novel diffusion process that integrates the signal attenuation mechanism into the diffusion pipeline, enabling simultaneous brightness adjustment and noise suppression in a single stage. Specifically, the signal attenuation coefficient simulates the inherent signal attenuation of low-light degradation in the forward noise addition process, encoding the physical priors of low-light degradation to explicitly guide reverse denoising toward the concurrent optimization of brightness recovery and noise suppression, thereby eliminating the need for extra correction modules or staged training relied on by existing methods. We validate that our design maintains consistency with Denoising Diffusion Implicit Models(DDIM) via multi-scale pyramid sampling, balancing interpretability, restoration quality, and computational efficiency.
PolarAPP: Beyond Polarization Demosaicking for Polarimetric Applications
Mar 24, 2026Polarimetric imaging enables advanced vision applications such as normal estimation and de-reflection by capturing unique surface-material interactions. However, existing applications (alternatively called downstream tasks) rely on datasets constructed by naively regrouping raw measurements from division-of-focal-plane sensors, where pixels of the same polarization angle are extracted and aligned into sparse images without proper demosaicking. This reconstruction strategy results in suboptimal, incomplete targets that limit downstream performance. Moreover, current demosaicking methods are task-agnostic, optimizing only for photometric fidelity rather than utility in downstream tasks. Towards this end, we propose PolarAPP, the first framework to jointly optimize demosaicking and its downstream tasks. PolarAPP introduces a feature alignment mechanism that semantically aligns the representations of demosaicking and downstream networks via meta-learning, guiding the reconstruction to be task-aware. It further employs an equivalent imaging constraint for demosaicking training, enabling direct regression to physically meaningful outputs without relying on rearranged data. Finally, a task-refinement stage fine-tunes the task network using the stable demosaicking front-end to further enhance accuracy. Extensive experimental results demonstrate that PolarAPP outperforms existing methods in both demosaicking quality and downstream performance. Code is available upon acceptance.
An Agentic Evaluation Framework for AI-Generated Scientific Code in PETSc
Mar 16, 2026While large language models have significantly accelerated scientific code generation, comprehensively evaluating the generated code remains a major challenge. Traditional benchmarks reduce evaluation to test-case matching, an approach insufficient for library code in HPC where solver selection, API conventions, memory management, and performance are just as critical as functional correctness. To address this gap, we introduce petscagent-bench, an agentic framework built on an agents-evaluating-agents paradigm. Instead of relying on static scripts, petscagent-bench deploys a tool-augmented evaluator agent that compiles, executes, and measures code produced by a separate model-under-test agent, orchestrating a 14-evaluator pipeline across five scoring categories: correctness, performance, code quality, algorithmic appropriateness, and library-specific conventions. Because the agents communicate through standardized protocols (A2A and MCP), the framework enables black-box evaluation of any coding agent without requiring access to its source code. We demonstrate the framework on a benchmark suite of realistic problems using the PETSc library for HPC. Our empirical analysis of frontier models reveals that while current models generate readable, well-structured code, they consistently struggle with library-specific conventions that traditional pass/fail metrics completely miss.
Polarization Uncertainty-Guided Diffusion Model for Color Polarization Image Demosaicking
Feb 27, 2026Color polarization demosaicking (CPDM) aims to reconstruct full-resolution polarization images of four directions from the color-polarization filter array (CPFA) raw image. Due to the challenge of predicting numerous missing pixels and the scarcity of high-quality training data, existing network-based methods, despite effectively recovering scene intensity information, still exhibit significant errors in reconstructing polarization characteristics (degree of polarization, DOP, and angle of polarization, AOP). To address this problem, we introduce the image diffusion prior from text-to-image (T2I) models to overcome the performance bottleneck of network-based methods, with the additional diffusion prior compensating for limited representational capacity caused by restricted data distribution. To effectively leverage the diffusion prior, we explicitly model the polarization uncertainty during reconstruction and use uncertainty to guide the diffusion model in recovering high error regions. Extensive experiments demonstrate that the proposed method accurately recovers scene polarization characteristics with both high fidelity and strong visual perception.
AI Assistants to Enhance and Exploit the PETSc Knowledge Base
Jun 25, 2025Generative AI, especially through large language models (LLMs), is transforming how technical knowledge can be accessed, reused, and extended. PETSc, a widely used numerical library for high-performance scientific computing, has accumulated a rich but fragmented knowledge base over its three decades of development, spanning source code, documentation, mailing lists, GitLab issues, Discord conversations, technical papers, and more. Much of this knowledge remains informal and inaccessible to users and new developers. To activate and utilize this knowledge base more effectively, the PETSc team has begun building an LLM-powered system that combines PETSc content with custom LLM tools -- including retrieval-augmented generation (RAG), reranking algorithms, and chatbots -- to assist users, support developers, and propose updates to formal documentation. This paper presents initial experiences designing and evaluating these tools, focusing on system architecture, using RAG and reranking for PETSc-specific information, evaluation methodologies for various LLMs and embedding models, and user interface design. Leveraging the Argonne Leadership Computing Facility resources, we analyze how LLM responses can enhance the development and use of numerical software, with an initial focus on scalable Krylov solvers. Our goal is to establish an extensible framework for knowledge-centered AI in scientific software, enabling scalable support, enriched documentation, and enhanced workflows for research and development. We conclude by outlining directions for expanding this system into a robust, evolving platform that advances software ecosystems to accelerate scientific discovery.
A High Energy-Efficiency Multi-core Neuromorphic Architecture for Deep SNN Training
Dec 10, 2024



There is a growing necessity for edge training to adapt to dynamically changing environment. Neuromorphic computing represents a significant pathway for high-efficiency intelligent computation in energy-constrained edges, but existing neuromorphic architectures lack the ability of directly training spiking neural networks (SNNs) based on backpropagation. We develop a multi-core neuromorphic architecture with Feedforward-Propagation, Back-Propagation, and Weight-Gradient engines in each core, supporting high efficient parallel computing at both the engine and core levels. It combines various data flows and sparse computation optimization by fully leveraging the sparsity in SNN training, obtaining a high energy efficiency of 1.05TFLOPS/W@ FP16 @ 28nm, 55 ~ 85% reduction of DRAM access compared to A100 GPU in SNN trainings, and a 20-core deep SNN training and a 5-worker federated learning on FPGAs. Our study develops the first multi-core neuromorphic architecture supporting the direct SNN training, facilitating the neuromorphic computing in edge-learnable applications.
One Step Diffusion-based Super-Resolution with Time-Aware Distillation
Aug 14, 2024Diffusion-based image super-resolution (SR) methods have shown promise in reconstructing high-resolution images with fine details from low-resolution counterparts. However, these approaches typically require tens or even hundreds of iterative samplings, resulting in significant latency. Recently, techniques have been devised to enhance the sampling efficiency of diffusion-based SR models via knowledge distillation. Nonetheless, when aligning the knowledge of student and teacher models, these solutions either solely rely on pixel-level loss constraints or neglect the fact that diffusion models prioritize varying levels of information at different time steps. To accomplish effective and efficient image super-resolution, we propose a time-aware diffusion distillation method, named TAD-SR. Specifically, we introduce a novel score distillation strategy to align the data distribution between the outputs of the student and teacher models after minor noise perturbation. This distillation strategy enables the student network to concentrate more on the high-frequency details. Furthermore, to mitigate performance limitations stemming from distillation, we integrate a latent adversarial loss and devise a time-aware discriminator that leverages diffusion priors to effectively distinguish between real images and generated images. Extensive experiments conducted on synthetic and real-world datasets demonstrate that the proposed method achieves comparable or even superior performance compared to both previous state-of-the-art (SOTA) methods and the teacher model in just one sampling step. Codes are available at https://github.com/LearningHx/TAD-SR.
Weighted Encoding Based Image Interpolation With Nonlocal Linear Regression Model
Mar 04, 2020



Image interpolation is a special case of image super-resolution, where the low-resolution image is directly down-sampled from its high-resolution counterpart without blurring and noise. Therefore, assumptions adopted in super-resolution models are not valid for image interpolation. To address this problem, we propose a novel image interpolation model based on sparse representation. Two widely used priors including sparsity and nonlocal self-similarity are used as the regularization terms to enhance the stability of interpolation model. Meanwhile, we incorporate the nonlocal linear regression into this model since nonlocal similar patches could provide a better approximation to a given patch. Moreover, we propose a new approach to learn adaptive sub-dictionary online instead of clustering. For each patch, similar patches are grouped to learn adaptive sub-dictionary, generating a more sparse and accurate representation. Finally, the weighted encoding is introduced to suppress tailing of fitting residuals in data fidelity. Abundant experimental results demonstrate that our proposed method outperforms several state-of-the-art methods in terms of quantitative measures and visual quality.
Object-aware Aggregation with Bidirectional Temporal Graph for Video Captioning
Jun 11, 2019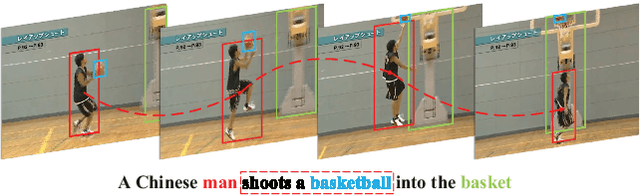
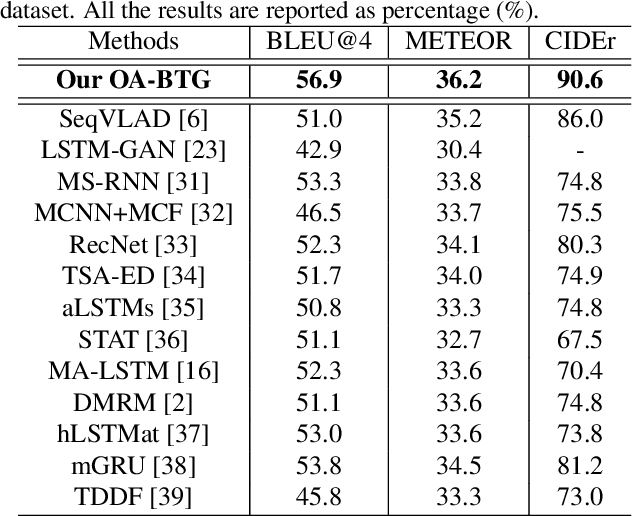
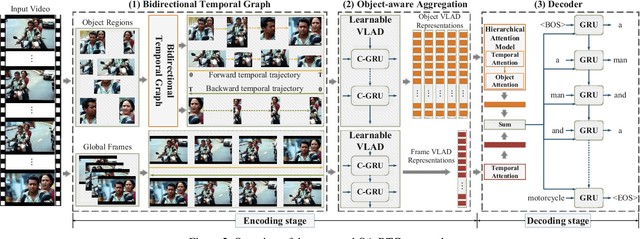
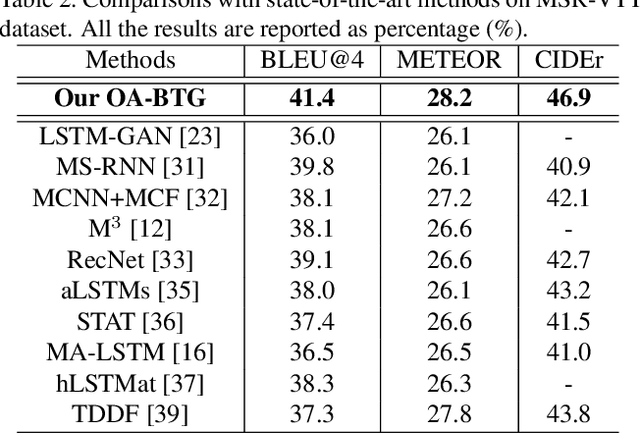
Video captioning aims to automatically generate natural language descriptions of video content, which has drawn a lot of attention recent years. Generating accurate and fine-grained captions needs to not only understand the global content of video, but also capture the detailed object information. Meanwhile, video representations have great impact on the quality of generated captions. Thus, it is important for video captioning to capture salient objects with their detailed temporal dynamics, and represent them using discriminative spatio-temporal representations. In this paper, we propose a new video captioning approach based on object-aware aggregation with bidirectional temporal graph (OA-BTG), which captures detailed temporal dynamics for salient objects in video, and learns discriminative spatio-temporal representations by performing object-aware local feature aggregation on detected object regions. The main novelties and advantages are: (1) Bidirectional temporal graph: A bidirectional temporal graph is constructed along and reversely along the temporal order, which provides complementary ways to capture the temporal trajectories for each salient object. (2) Object-aware aggregation: Learnable VLAD (Vector of Locally Aggregated Descriptors) models are constructed on object temporal trajectories and global frame sequence, which performs object-aware aggregation to learn discriminative representations. A hierarchical attention mechanism is also developed to distinguish different contributions of multiple objects. Experiments on two widely-used datasets demonstrate our OA-BTG achieves state-of-the-art performance in terms of BLEU@4, METEOR and CIDEr metrics.