 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDynamic Parsing and Updating Natural Language Specification using VLMs for Robust Vision-Language Tracking
Jun 28, 2026Vision-language tracking guided by natural language specifications leverages high-level semantic cues of target objects to substantially boost tracking accuracy and robustness. Existing studies have verified that adaptively optimizing textual descriptions throughout the tracking process can effectively mitigate the semantic-visual mismatch induced by dynamic variations in target appearance, position, and other inherent attributes. Nevertheless, mainstream methods that directly generate textual information via sequence models or large language models inevitably suffer from inherent defects, including erroneous target updating, excessive background distraction, and pervasive hallucination artifacts. To address the aforementioned limitations, this paper proposes a novel language dependency parsing mechanism to precisely distill core tracking principal components, encompassing target objects, semantic concepts, and background contextual information. On this basis, we perform component-aware adaptive textual description updates by exploiting the powerful cross-modal understanding capability of the pre-trained vision-language model Qwen-VL. By integrating the proposed elaborately designed modules into the baseline framework, our method achieves consistent and superior tracking performance on multiple large-scale vision-language tracking benchmarks, including TNL2K, LaSOT, TNLLT, and OTB-LANG. The source code and pre-trained models will be released at https://github.com/Event-AHU/Open_VLTrack.
ReasoningTrack: Chain-of-Thought Reasoning for Long-term Vision-Language Tracking
Aug 07, 2025Vision-language tracking has received increasing attention in recent years, as textual information can effectively address the inflexibility and inaccuracy associated with specifying the target object to be tracked. Existing works either directly fuse the fixed language with vision features or simply modify using attention, however, their performance is still limited. Recently, some researchers have explored using text generation to adapt to the variations in the target during tracking, however, these works fail to provide insights into the model's reasoning process and do not fully leverage the advantages of large models, which further limits their overall performance. To address the aforementioned issues, this paper proposes a novel reasoning-based vision-language tracking framework, named ReasoningTrack, based on a pre-trained vision-language model Qwen2.5-VL. Both SFT (Supervised Fine-Tuning) and reinforcement learning GRPO are used for the optimization of reasoning and language generation. We embed the updated language descriptions and feed them into a unified tracking backbone network together with vision features. Then, we adopt a tracking head to predict the specific location of the target object. In addition, we propose a large-scale long-term vision-language tracking benchmark dataset, termed TNLLT, which contains 200 video sequences. 20 baseline visual trackers are re-trained and evaluated on this dataset, which builds a solid foundation for the vision-language visual tracking task. Extensive experiments on multiple vision-language tracking benchmark datasets fully validated the effectiveness of our proposed reasoning-based natural language generation strategy. The source code of this paper will be released on https://github.com/Event-AHU/Open_VLTrack
Towards Low-Latency Event Stream-based Visual Object Tracking: A Slow-Fast Approach
May 19, 2025Existing tracking algorithms typically rely on low-frame-rate RGB cameras coupled with computationally intensive deep neural network architectures to achieve effective tracking. However, such frame-based methods inherently face challenges in achieving low-latency performance and often fail in resource-constrained environments. Visual object tracking using bio-inspired event cameras has emerged as a promising research direction in recent years, offering distinct advantages for low-latency applications. In this paper, we propose a novel Slow-Fast Tracking paradigm that flexibly adapts to different operational requirements, termed SFTrack. The proposed framework supports two complementary modes, i.e., a high-precision slow tracker for scenarios with sufficient computational resources, and an efficient fast tracker tailored for latency-aware, resource-constrained environments. Specifically, our framework first performs graph-based representation learning from high-temporal-resolution event streams, and then integrates the learned graph-structured information into two FlashAttention-based vision backbones, yielding the slow and fast trackers, respectively. The fast tracker achieves low latency through a lightweight network design and by producing multiple bounding box outputs in a single forward pass. Finally, we seamlessly combine both trackers via supervised fine-tuning and further enhance the fast tracker's performance through a knowledge distillation strategy. Extensive experiments on public benchmarks, including FE240, COESOT, and EventVOT, demonstrate the effectiveness and efficiency of our proposed method across different real-world scenarios. The source code has been released on https://github.com/Event-AHU/SlowFast_Event_Track.
XiHeFusion: Harnessing Large Language Models for Science Communication in Nuclear Fusion
Feb 08, 2025



Nuclear fusion is one of the most promising ways for humans to obtain infinite energy. Currently, with the rapid development of artificial intelligence, the mission of nuclear fusion has also entered a critical period of its development. How to let more people to understand nuclear fusion and join in its research is one of the effective means to accelerate the implementation of fusion. This paper proposes the first large model in the field of nuclear fusion, XiHeFusion, which is obtained through supervised fine-tuning based on the open-source large model Qwen2.5-14B. We have collected multi-source knowledge about nuclear fusion tasks to support the training of this model, including the common crawl, eBooks, arXiv, dissertation, etc. After the model has mastered the knowledge of the nuclear fusion field, we further used the chain of thought to enhance its logical reasoning ability, making XiHeFusion able to provide more accurate and logical answers. In addition, we propose a test questionnaire containing 180+ questions to assess the conversational ability of this science popularization large model. Extensive experimental results show that our nuclear fusion dialogue model, XiHeFusion, can perform well in answering science popularization knowledge. The pre-trained XiHeFusion model is released on https://github.com/Event-AHU/XiHeFusion.
Event Stream-based Visual Object Tracking: HDETrack V2 and A High-Definition Benchmark
Feb 08, 2025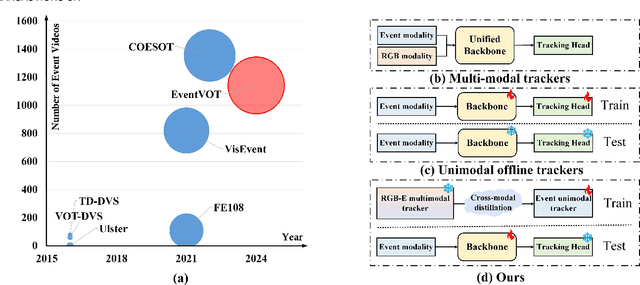

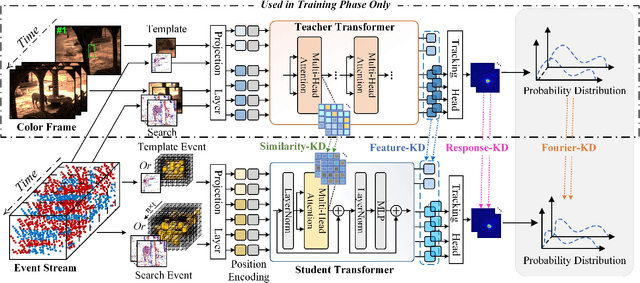

We then introduce a novel hierarchical knowledge distillation strategy that incorporates the similarity matrix, feature representation, and response map-based distillation to guide the learning of the student Transformer network. We also enhance the model's ability to capture temporal dependencies by applying the temporal Fourier transform to establish temporal relationships between video frames. We adapt the network model to specific target objects during testing via a newly proposed test-time tuning strategy to achieve high performance and flexibility in target tracking. Recognizing the limitations of existing event-based tracking datasets, which are predominantly low-resolution, we propose EventVOT, the first large-scale high-resolution event-based tracking dataset. It comprises 1141 videos spanning diverse categories such as pedestrians, vehicles, UAVs, ping pong, etc. Extensive experiments on both low-resolution (FE240hz, VisEvent, FELT), and our newly proposed high-resolution EventVOT dataset fully validated the effectiveness of our proposed method. Both the benchmark dataset and source code have been released on https://github.com/Event-AHU/EventVOT_Benchmark