 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeYong Liu
Toward Multi-class Anomaly Detection: Exploring Class-aware Unified Model against Inter-class Interference
Mar 21, 2024
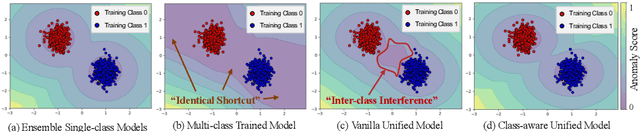
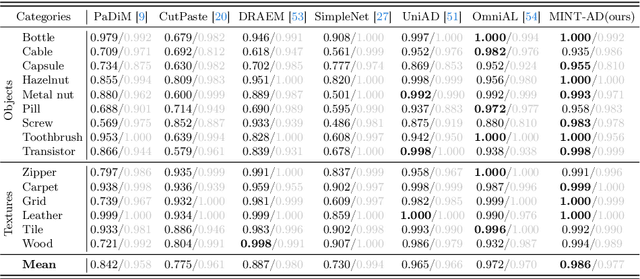
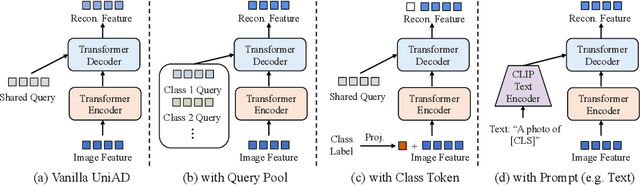
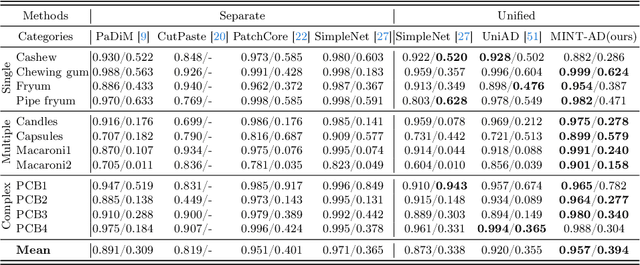
In the context of high usability in single-class anomaly detection models, recent academic research has become concerned about the more complex multi-class anomaly detection. Although several papers have designed unified models for this task, they often overlook the utility of class labels, a potent tool for mitigating inter-class interference. To address this issue, we introduce a Multi-class Implicit Neural representation Transformer for unified Anomaly Detection (MINT-AD), which leverages the fine-grained category information in the training stage. By learning the multi-class distributions, the model generates class-aware query embeddings for the transformer decoder, mitigating inter-class interference within the reconstruction model. Utilizing such an implicit neural representation network, MINT-AD can project category and position information into a feature embedding space, further supervised by classification and prior probability loss functions. Experimental results on multiple datasets demonstrate that MINT-AD outperforms existing unified training models.
Tuning-Free Image Customization with Image and Text Guidance
Mar 19, 2024
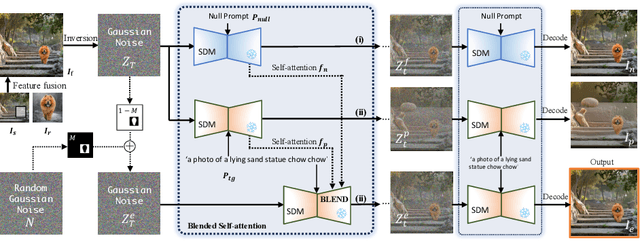


Despite significant advancements in image customization with diffusion models, current methods still have several limitations: 1) unintended changes in non-target areas when regenerating the entire image; 2) guidance solely by a reference image or text descriptions; and 3) time-consuming fine-tuning, which limits their practical application. In response, we introduce a tuning-free framework for simultaneous text-image-guided image customization, enabling precise editing of specific image regions within seconds. Our approach preserves the semantic features of the reference image subject while allowing modification of detailed attributes based on text descriptions. To achieve this, we propose an innovative attention blending strategy that blends self-attention features in the UNet decoder during the denoising process. To our knowledge, this is the first tuning-free method that concurrently utilizes text and image guidance for image customization in specific regions. Our approach outperforms previous methods in both human and quantitative evaluations, providing an efficient solution for various practical applications, such as image synthesis, design, and creative photography.
HCPM: Hierarchical Candidates Pruning for Efficient Detector-Free Matching
Mar 19, 2024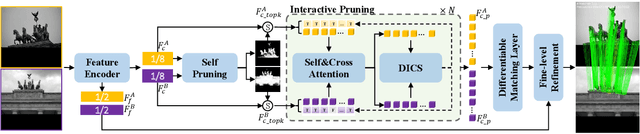
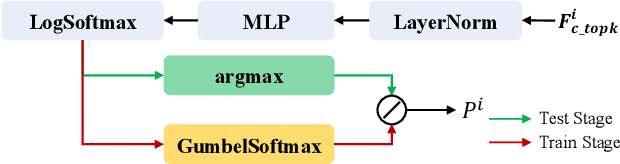
Deep learning-based image matching methods play a crucial role in computer vision, yet they often suffer from substantial computational demands. To tackle this challenge, we present HCPM, an efficient and detector-free local feature-matching method that employs hierarchical pruning to optimize the matching pipeline. In contrast to recent detector-free methods that depend on an exhaustive set of coarse-level candidates for matching, HCPM selectively concentrates on a concise subset of informative candidates, resulting in fewer computational candidates and enhanced matching efficiency. The method comprises a self-pruning stage for selecting reliable candidates and an interactive-pruning stage that identifies correlated patches at the coarse level. Our results reveal that HCPM significantly surpasses existing methods in terms of speed while maintaining high accuracy. The source code will be made available upon publication.
Interactive $360^{\circ}$ Video Streaming Using FoV-Adaptive Coding with Temporal Prediction
Mar 17, 2024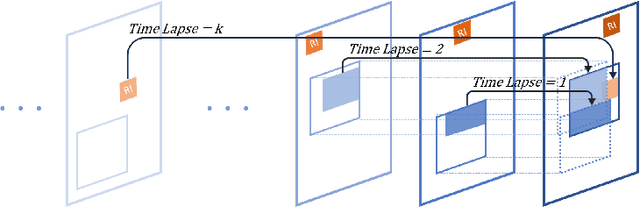
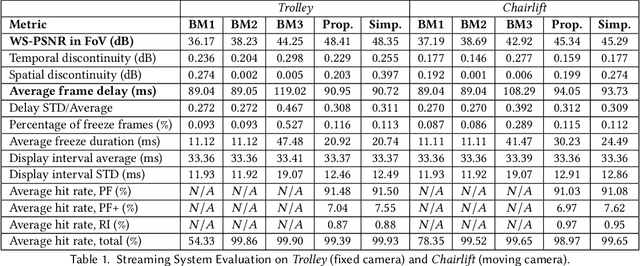
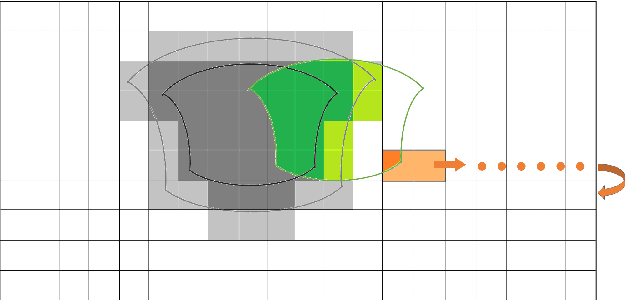

For $360^{\circ}$ video streaming, FoV-adaptive coding that allocates more bits for the predicted user's field of view (FoV) is an effective way to maximize the rendered video quality under the limited bandwidth. We develop a low-latency FoV-adaptive coding and streaming system for interactive applications that is robust to bandwidth variations and FoV prediction errors. To minimize the end-to-end delay and yet maximize the coding efficiency, we propose a frame-level FoV-adaptive inter-coding structure. In each frame, regions that are in or near the predicted FoV are coded using temporal and spatial prediction, while a small rotating region is coded with spatial prediction only. This rotating intra region periodically refreshes the entire frame, thereby providing robustness to both FoV prediction errors and frame losses due to transmission errors. The system adapts the sizes and rates of different regions for each video segment to maximize the rendered video quality under the predicted bandwidth constraint. Integrating such frame-level FoV adaptation with temporal prediction is challenging due to the temporal variations of the FoV. We propose novel ways for modeling the influence of FoV dynamics on the quality-rate performance of temporal predictive coding.We further develop LSTM-based machine learning models to predict the user's FoV and network bandwidth.The proposed system is compared with three benchmark systems, using real-world network bandwidth traces and FoV traces, and is shown to significantly improve the rendered video quality, while achieving very low end-to-end delay and low frame-freeze probability.
Performance Analysis on RIS-Aided Wideband Massive MIMO OFDM Systems with Low-Resolution ADCs
Mar 14, 2024This paper investigates a reconfigurable intelligent surface (RIS)-aided wideband massive multiple-input multiple-output (MIMO) orthogonal frequency division multiplexing (OFDM) system with low-resolution analog-to-digital converters (ADCs). Frequency-selective Rician fading channels are considered, and the OFDM data transmission process is presented in time domain. This paper derives the closed-form approximate expression of the uplink achievable rate, based on which the asymptotic system performance is analyzed when the number of the antennas at the base station and the number of reflecting elements at the RIS grow to infinity. Besides, the power scaling laws of the considered system are revealed to provide energy-saving insights. Furthermore, this paper proposes a gradient ascent-based algorithm to design the phase shifts of the RIS for maximizing the minimum user rate. Finally, numerical results are presented to verify the correctness of analytical conclusions and draw insights.
AutoDFP: Automatic Data-Free Pruning via Channel Similarity Reconstruction
Mar 13, 2024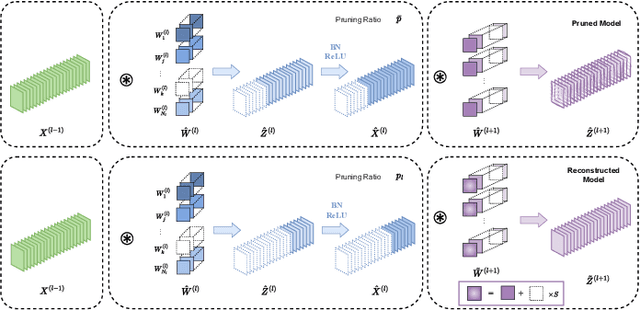
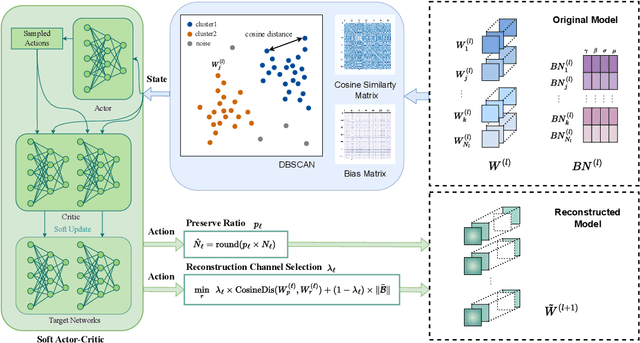
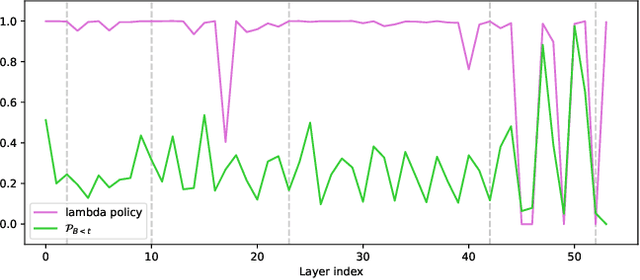
Structured pruning methods are developed to bridge the gap between the massive scale of neural networks and the limited hardware resources. Most current structured pruning methods rely on training datasets to fine-tune the compressed model, resulting in high computational burdens and being inapplicable for scenarios with stringent requirements on privacy and security. As an alternative, some data-free methods have been proposed, however, these methods often require handcraft parameter tuning and can only achieve inflexible reconstruction. In this paper, we propose the Automatic Data-Free Pruning (AutoDFP) method that achieves automatic pruning and reconstruction without fine-tuning. Our approach is based on the assumption that the loss of information can be partially compensated by retaining focused information from similar channels. Specifically, We formulate data-free pruning as an optimization problem, which can be effectively addressed through reinforcement learning. AutoDFP assesses the similarity of channels for each layer and provides this information to the reinforcement learning agent, guiding the pruning and reconstruction process of the network. We evaluate AutoDFP with multiple networks on multiple datasets, achieving impressive compression results. For instance, on the CIFAR-10 dataset, AutoDFP demonstrates a 2.87\% reduction in accuracy loss compared to the recently proposed data-free pruning method DFPC with fewer FLOPs on VGG-16. Furthermore, on the ImageNet dataset, AutoDFP achieves 43.17\% higher accuracy than the SOTA method with the same 80\% preserved ratio on MobileNet-V1.
DO3D: Self-supervised Learning of Decomposed Object-aware 3D Motion and Depth from Monocular Videos
Mar 09, 2024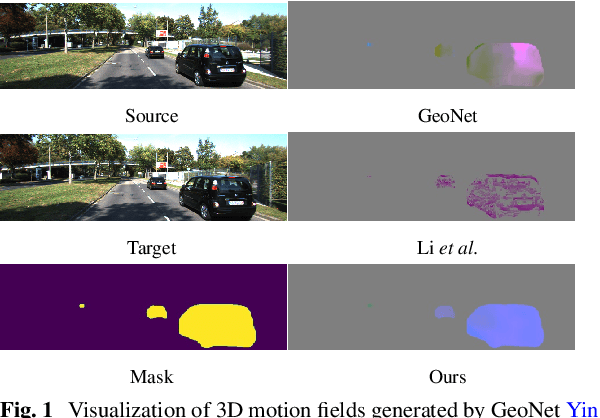
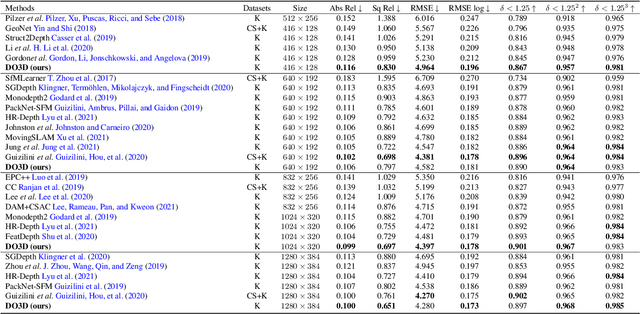
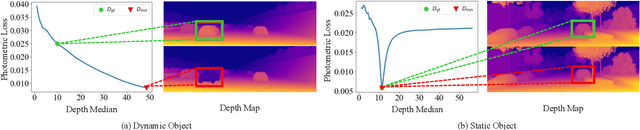

Although considerable advancements have been attained in self-supervised depth estimation from monocular videos, most existing methods often treat all objects in a video as static entities, which however violates the dynamic nature of real-world scenes and fails to model the geometry and motion of moving objects. In this paper, we propose a self-supervised method to jointly learn 3D motion and depth from monocular videos. Our system contains a depth estimation module to predict depth, and a new decomposed object-wise 3D motion (DO3D) estimation module to predict ego-motion and 3D object motion. Depth and motion networks work collaboratively to faithfully model the geometry and dynamics of real-world scenes, which, in turn, benefits both depth and 3D motion estimation. Their predictions are further combined to synthesize a novel video frame for self-supervised training. As a core component of our framework, DO3D is a new motion disentanglement module that learns to predict camera ego-motion and instance-aware 3D object motion separately. To alleviate the difficulties in estimating non-rigid 3D object motions, they are decomposed to object-wise 6-DoF global transformations and a pixel-wise local 3D motion deformation field. Qualitative and quantitative experiments are conducted on three benchmark datasets, including KITTI, Cityscapes, and VKITTI2, where our model delivers superior performance in all evaluated settings. For the depth estimation task, our model outperforms all compared research works in the high-resolution setting, attaining an absolute relative depth error (abs rel) of 0.099 on the KITTI benchmark. Besides, our optical flow estimation results (an overall EPE of 7.09 on KITTI) also surpass state-of-the-art methods and largely improve the estimation of dynamic regions, demonstrating the effectiveness of our motion model. Our code will be available.
RLPeri: Accelerating Visual Perimetry Test with Reinforcement Learning and Convolutional Feature Extraction
Mar 08, 2024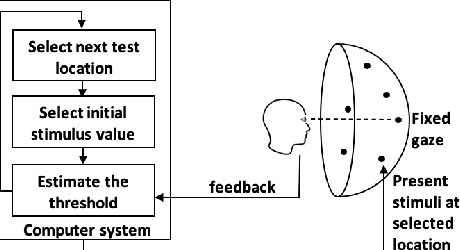
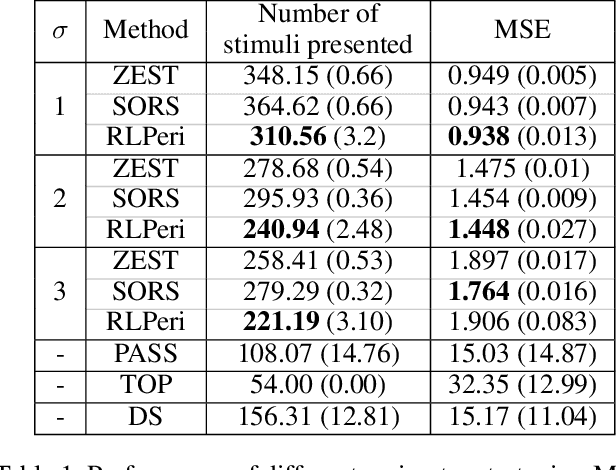
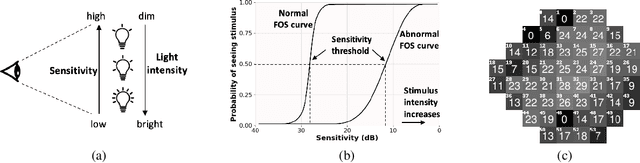
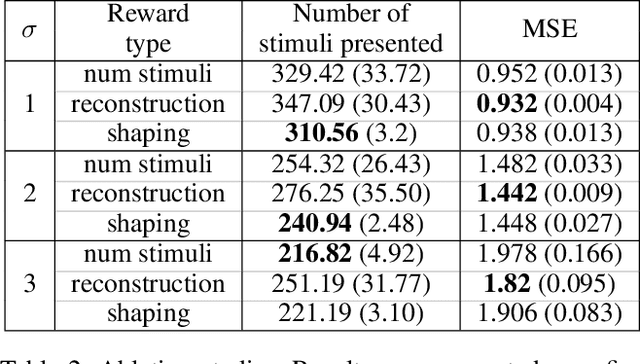
Visual perimetry is an important eye examination that helps detect vision problems caused by ocular or neurological conditions. During the test, a patient's gaze is fixed at a specific location while light stimuli of varying intensities are presented in central and peripheral vision. Based on the patient's responses to the stimuli, the visual field mapping and sensitivity are determined. However, maintaining high levels of concentration throughout the test can be challenging for patients, leading to increased examination times and decreased accuracy. In this work, we present RLPeri, a reinforcement learning-based approach to optimize visual perimetry testing. By determining the optimal sequence of locations and initial stimulus values, we aim to reduce the examination time without compromising accuracy. Additionally, we incorporate reward shaping techniques to further improve the testing performance. To monitor the patient's responses over time during testing, we represent the test's state as a pair of 3D matrices. We apply two different convolutional kernels to extract spatial features across locations as well as features across different stimulus values for each location. Through experiments, we demonstrate that our approach results in a 10-20% reduction in examination time while maintaining the accuracy as compared to state-of-the-art methods. With the presented approach, we aim to make visual perimetry testing more efficient and patient-friendly, while still providing accurate results.
* Published at AAAI-24
The 2nd Workshop on Recommendation with Generative Models
Mar 07, 2024
The rise of generative models has driven significant advancements in recommender systems, leaving unique opportunities for enhancing users' personalized recommendations. This workshop serves as a platform for researchers to explore and exchange innovative concepts related to the integration of generative models into recommender systems. It primarily focuses on five key perspectives: (i) improving recommender algorithms, (ii) generating personalized content, (iii) evolving the user-system interaction paradigm, (iv) enhancing trustworthiness checks, and (v) refining evaluation methodologies for generative recommendations. With generative models advancing rapidly, an increasing body of research is emerging in these domains, underscoring the timeliness and critical importance of this workshop. The related research will introduce innovative technologies to recommender systems and contribute to fresh challenges in both academia and industry. In the long term, this research direction has the potential to revolutionize the traditional recommender paradigms and foster the development of next-generation recommender systems.
LORS: Low-rank Residual Structure for Parameter-Efficient Network Stacking
Mar 07, 2024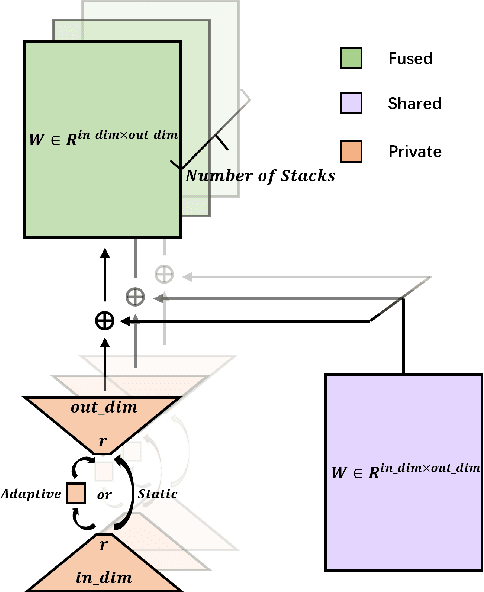
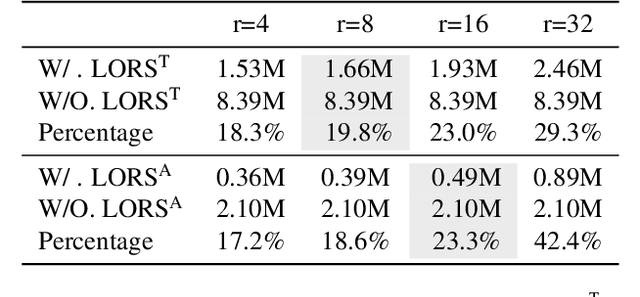


Deep learning models, particularly those based on transformers, often employ numerous stacked structures, which possess identical architectures and perform similar functions. While effective, this stacking paradigm leads to a substantial increase in the number of parameters, posing challenges for practical applications. In today's landscape of increasingly large models, stacking depth can even reach dozens, further exacerbating this issue. To mitigate this problem, we introduce LORS (LOw-rank Residual Structure). LORS allows stacked modules to share the majority of parameters, requiring a much smaller number of unique ones per module to match or even surpass the performance of using entirely distinct ones, thereby significantly reducing parameter usage. We validate our method by applying it to the stacked decoders of a query-based object detector, and conduct extensive experiments on the widely used MS COCO dataset. Experimental results demonstrate the effectiveness of our method, as even with a 70\% reduction in the parameters of the decoder, our method still enables the model to achieve comparable or