 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFew-shot Medical Image Segmentation using a Global Correlation Network with Discriminative Embedding
Dec 10, 2020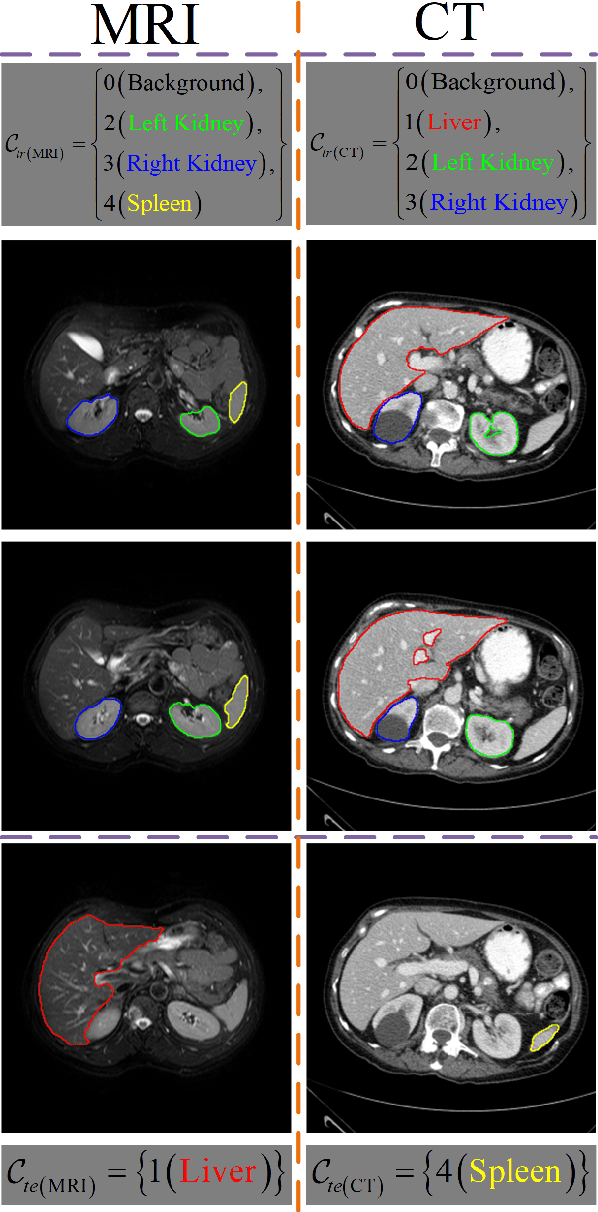
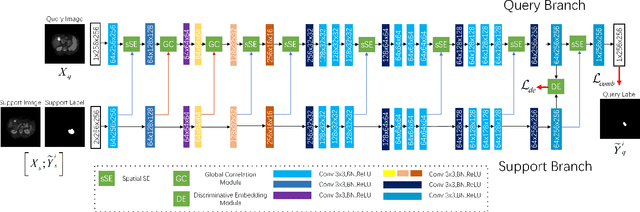
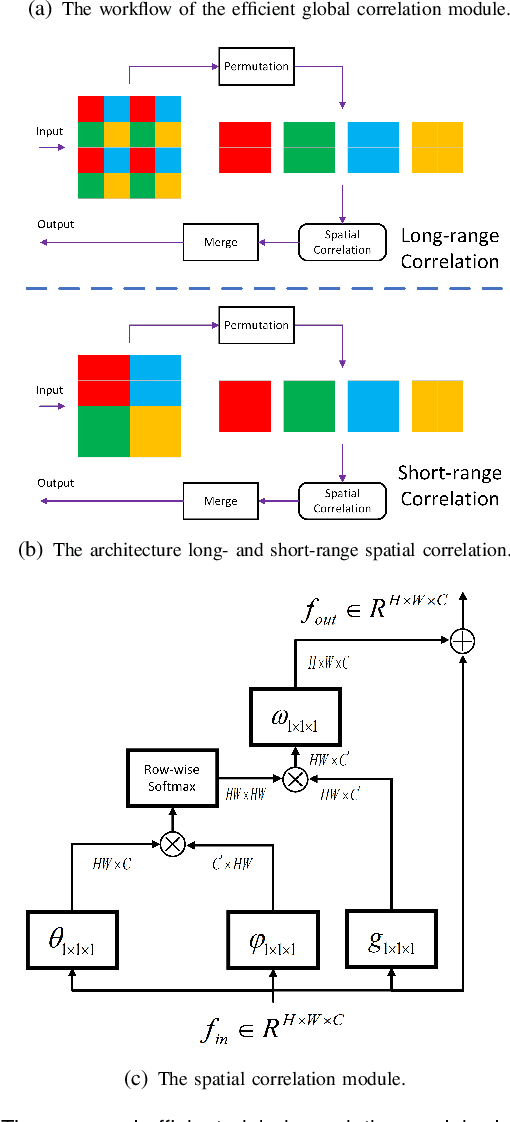
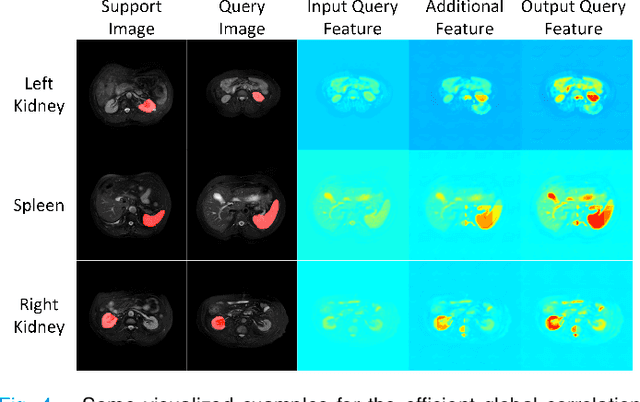
Despite deep convolutional neural networks achieved impressive progress in medical image computing and analysis, its paradigm of supervised learning demands a large number of annotations for training to avoid overfitting and achieving promising results. In clinical practices, massive semantic annotations are difficult to acquire in some conditions where specialized biomedical expert knowledge is required, and it is also a common condition where only few annotated classes are available. In this work, we proposed a novel method for few-shot medical image segmentation, which enables a segmentation model to fast generalize to an unseen class with few training images. We construct our few-shot image segmentor using a deep convolutional network trained episodically. Motivated by the spatial consistency and regularity in medical images, we developed an efficient global correlation module to capture the correlation between a support and query image and incorporate it into the deep network called global correlation network. Moreover, we enhance discriminability of deep embedding to encourage clustering of the feature domains of the same class while keep the feature domains of different organs far apart. Ablation Study proved the effectiveness of the proposed global correlation module and discriminative embedding loss. Extensive experiments on anatomical abdomen images on both CT and MRI modalities are performed to demonstrate the state-of-the-art performance of our proposed model.
Adaptive noise imitation for image denoising
Nov 30, 2020
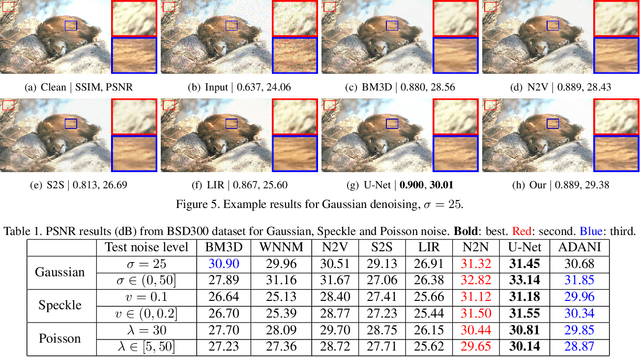
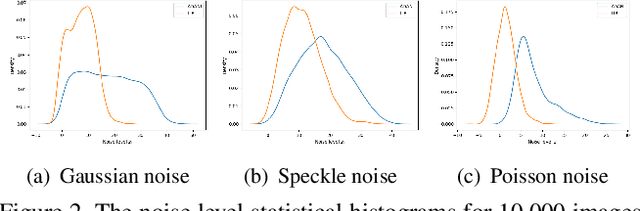

The effectiveness of existing denoising algorithms typically relies on accurate pre-defined noise statistics or plenty of paired data, which limits their practicality. In this work, we focus on denoising in the more common case where noise statistics and paired data are unavailable. Considering that denoising CNNs require supervision, we develop a new \textbf{adaptive noise imitation (ADANI)} algorithm that can synthesize noisy data from naturally noisy images. To produce realistic noise, a noise generator takes unpaired noisy/clean images as input, where the noisy image is a guide for noise generation. By imposing explicit constraints on the type, level and gradient of noise, the output noise of ADANI will be similar to the guided noise, while keeping the original clean background of the image. Coupling the noisy data output from ADANI with the corresponding ground-truth, a denoising CNN is then trained in a fully-supervised manner. Experiments show that the noisy data produced by ADANI are visually and statistically similar to real ones so that the denoising CNN in our method is competitive to other networks trained with external paired data.
A Teacher-Student Framework for Semi-supervised Medical Image Segmentation From Mixed Supervision
Oct 23, 2020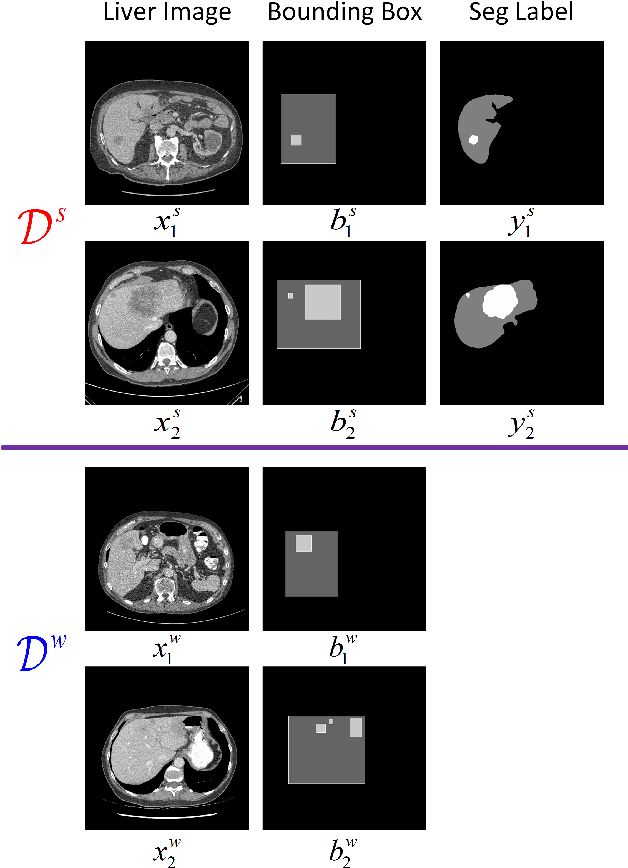
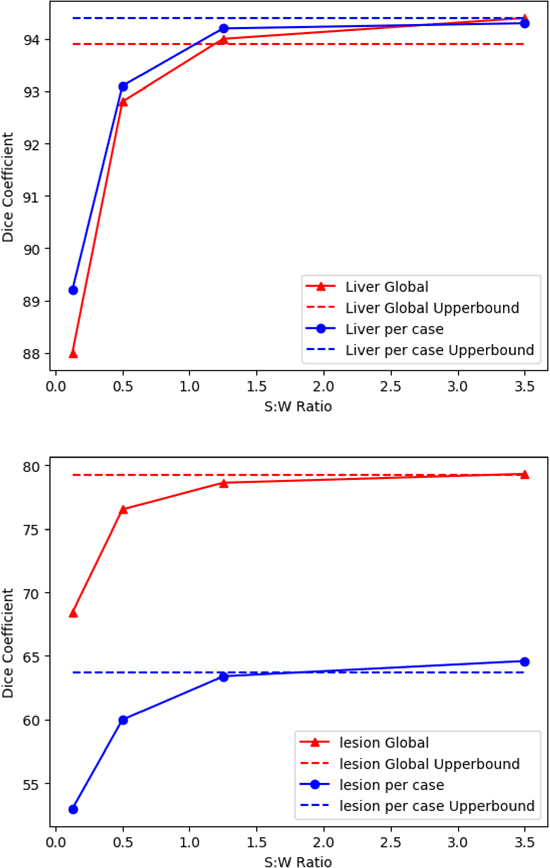
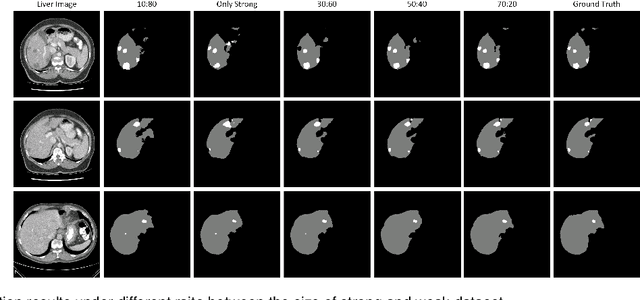
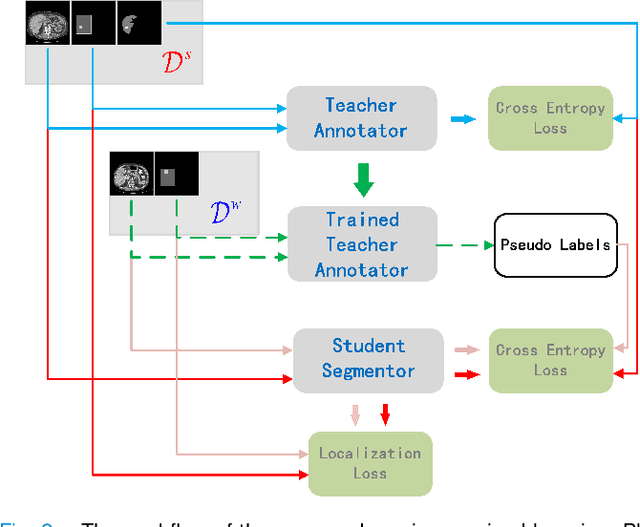
Standard segmentation of medical images based on full-supervised convolutional networks demands accurate dense annotations. Such learning framework is built on laborious manual annotation with restrict demands for expertise, leading to insufficient high-quality labels. To overcome such limitation and exploit massive weakly labeled data, we relaxed the rigid labeling requirement and developed a semi-supervised learning framework based on a teacher-student fashion for organ and lesion segmentation with partial dense-labeled supervision and supplementary loose bounding-box supervision which are easier to acquire. Observing the geometrical relation of an organ and its inner lesions in most cases, we propose a hierarchical organ-to-lesion (O2L) attention module in a teacher segmentor to produce pseudo-labels. Then a student segmentor is trained with combinations of manual-labeled and pseudo-labeled annotations. We further proposed a localization branch realized via an aggregation of high-level features in a deep decoder to predict locations of organ and lesion, which enriches student segmentor with precise localization information. We validated each design in our model on LiTS challenge datasets by ablation study and showed its state-of-the-art performance compared with recent methods. We show our model is robust to the quality of bounding box and achieves comparable performance compared with full-supervised learning methods.
The Detection of Thoracic Abnormalities ChestX-Det10 Challenge Results
Oct 22, 2020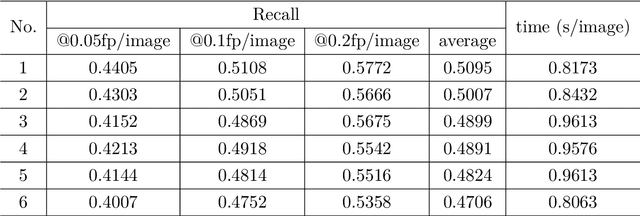
The detection of thoracic abnormalities challenge is organized by the Deepwise AI Lab. The challenge is divided into two rounds. In this paper, we present the results of 6 teams which reach the second round. The challenge adopts the ChestX-Det10 dateset proposed by the Deepwise AI Lab. ChestX-Det10 is the first chest X-Ray dataset with instance-level annotations, including 10 categories of disease/abnormality of 3,543 images. The annotations are located at https://github.com/Deepwise-AILab/ChestX-Det10-Dataset. In the challenge, we randomly split all data into 3001 images for training and 542 images for testing.
Contralaterally Enhanced Networks for Thoracic Disease Detection
Oct 09, 2020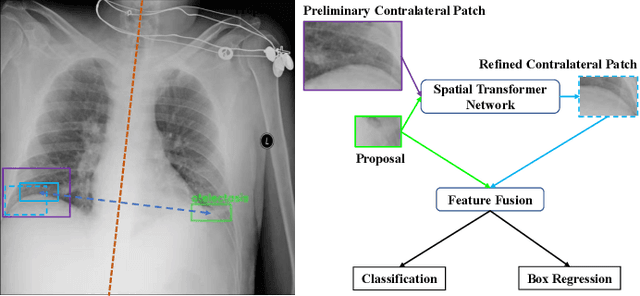

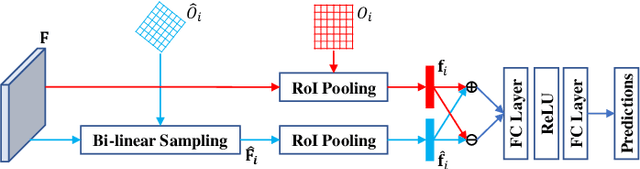
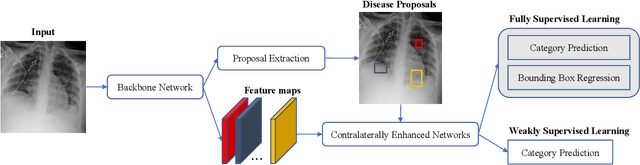
Identifying and locating diseases in chest X-rays are very challenging, due to the low visual contrast between normal and abnormal regions, and distortions caused by other overlapping tissues. An interesting phenomenon is that there exist many similar structures in the left and right parts of the chest, such as ribs, lung fields and bronchial tubes. This kind of similarities can be used to identify diseases in chest X-rays, according to the experience of broad-certificated radiologists. Aimed at improving the performance of existing detection methods, we propose a deep end-to-end module to exploit the contralateral context information for enhancing feature representations of disease proposals. First of all, under the guidance of the spine line, the spatial transformer network is employed to extract local contralateral patches, which can provide valuable context information for disease proposals. Then, we build up a specific module, based on both additive and subtractive operations, to fuse the features of the disease proposal and the contralateral patch. Our method can be integrated into both fully and weakly supervised disease detection frameworks. It achieves 33.17 AP50 on a carefully annotated private chest X-ray dataset which contains 31,000 images. Experiments on the NIH chest X-ray dataset indicate that our method achieves state-of-the-art performance in weakly-supervised disease localization.
Rethinking the Extraction and Interaction of Multi-Scale Features for Vessel Segmentation
Oct 09, 2020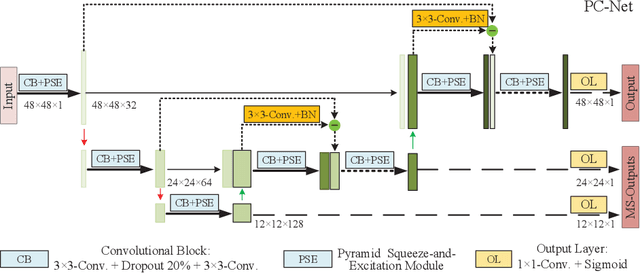
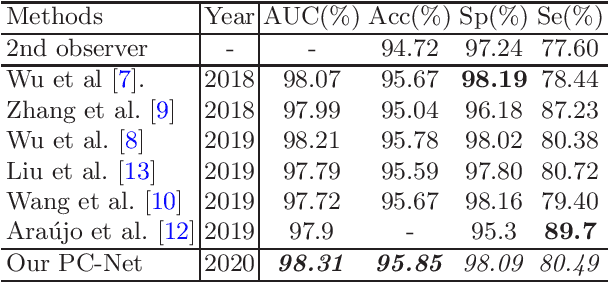
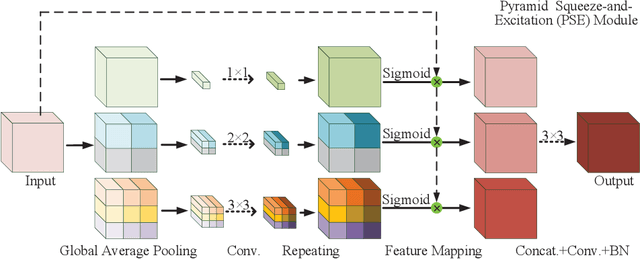
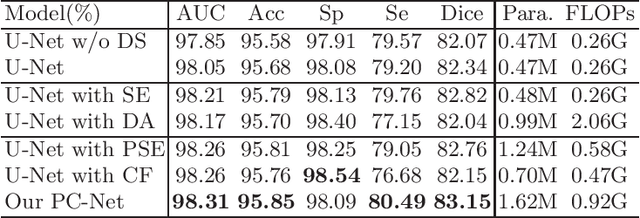
Analyzing the morphological attributes of blood vessels plays a critical role in the computer-aided diagnosis of many cardiovascular and ophthalmologic diseases. Although being extensively studied, segmentation of blood vessels, particularly thin vessels and capillaries, remains challenging mainly due to the lack of an effective interaction between local and global features. In this paper, we propose a novel deep learning model called PC-Net to segment retinal vessels and major arteries in 2D fundus image and 3D computed tomography angiography (CTA) scans, respectively. In PC-Net, the pyramid squeeze-and-excitation (PSE) module introduces spatial information to each convolutional block, boosting its ability to extract more effective multi-scale features, and the coarse-to-fine (CF) module replaces the conventional decoder to enhance the details of thin vessels and process hard-to-classify pixels again. We evaluated our PC-Net on the Digital Retinal Images for Vessel Extraction (DRIVE) database and an in-house 3D major artery (3MA) database against several recent methods. Our results not only demonstrate the effectiveness of the proposed PSE module and CF module, but also suggest that our proposed PC-Net sets new state of the art in the segmentation of retinal vessels (AUC: 98.31%) and major arteries (AUC: 98.35%) on both databases, respectively.
Bilateral Asymmetry Guided Counterfactual Generating Network for Mammogram Classification
Sep 30, 2020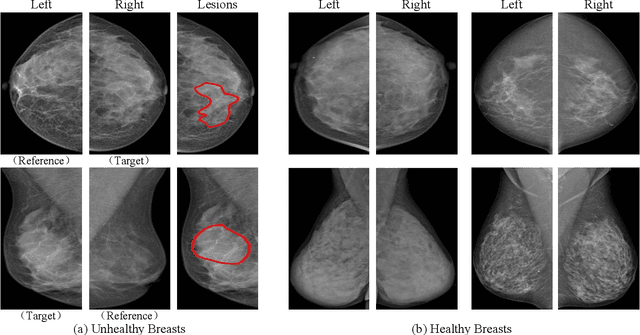
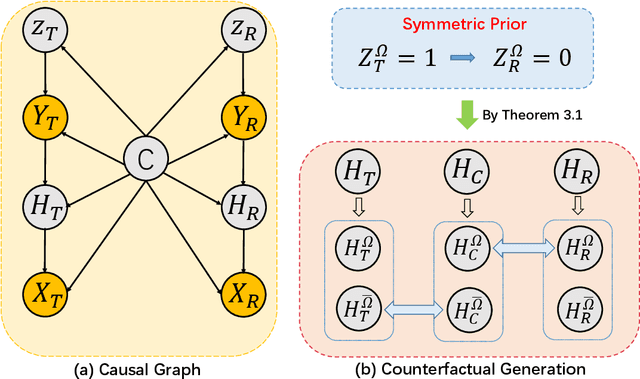
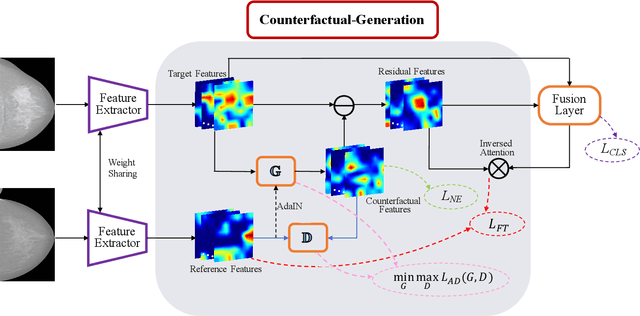
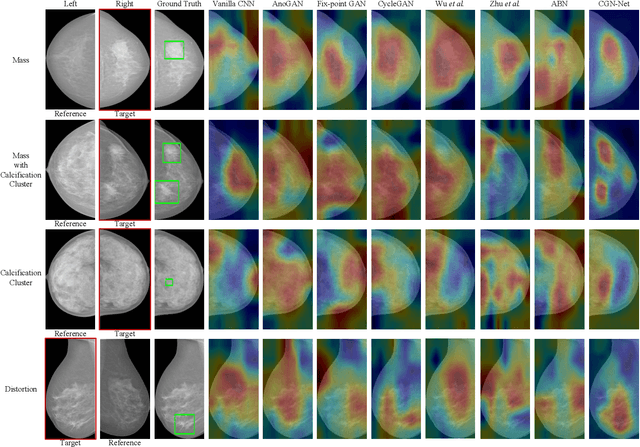
Mammogram benign or malignant classification with only image-level labels is challenging due to the absence of lesion annotations. Motivated by the symmetric prior that the lesions on one side of breasts rarely appear in the corresponding areas on the other side, given a diseased image, we can explore a counterfactual problem that how would the features have behaved if there were no lesions in the image, so as to identify the lesion areas. We derive a new theoretical result for counterfactual generation based on the symmetric prior. By building a causal model that entails such a prior for bilateral images, we obtain two optimization goals for counterfactual generation, which can be accomplished via our newly proposed counterfactual generative network. Our proposed model is mainly composed of Generator Adversarial Network and a \emph{prediction feedback mechanism}, they are optimized jointly and prompt each other. Specifically, the former can further improve the classification performance by generating counterfactual features to calculate lesion areas. On the other hand, the latter helps counterfactual generation by the supervision of classification loss. The utility of our method and the effectiveness of each module in our model can be verified by state-of-the-art performance on INBreast and an in-house dataset and ablation studies.
Online Alternate Generator against Adversarial Attacks
Sep 17, 2020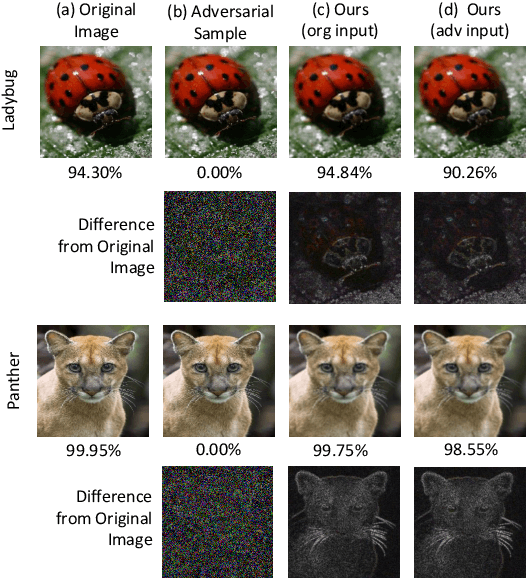

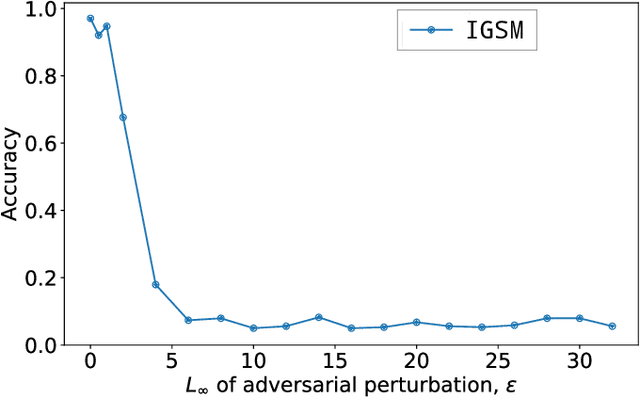
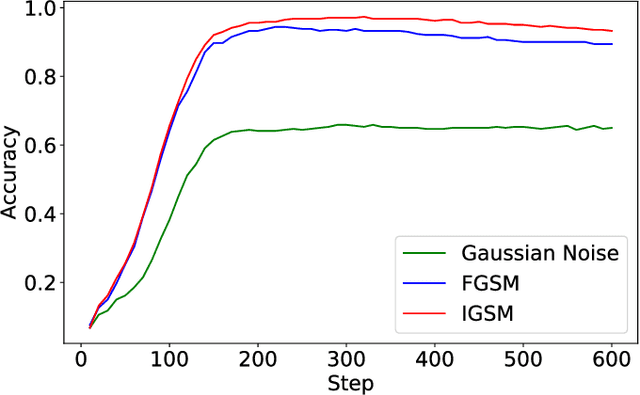
The field of computer vision has witnessed phenomenal progress in recent years partially due to the development of deep convolutional neural networks. However, deep learning models are notoriously sensitive to adversarial examples which are synthesized by adding quasi-perceptible noises on real images. Some existing defense methods require to re-train attacked target networks and augment the train set via known adversarial attacks, which is inefficient and might be unpromising with unknown attack types. To overcome the above issues, we propose a portable defense method, online alternate generator, which does not need to access or modify the parameters of the target networks. The proposed method works by online synthesizing another image from scratch for an input image, instead of removing or destroying adversarial noises. To avoid pretrained parameters exploited by attackers, we alternately update the generator and the synthesized image at the inference stage. Experimental results demonstrate that the proposed defensive scheme and method outperforms a series of state-of-the-art defending models against gray-box adversarial attacks.
Context-Aware Refinement Network Incorporating Structural Connectivity Prior for Brain Midline Delineation
Jul 10, 2020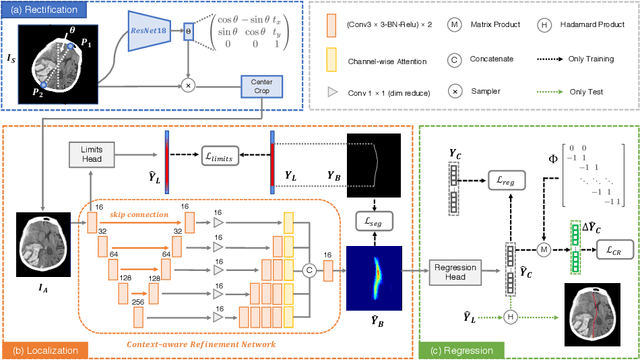
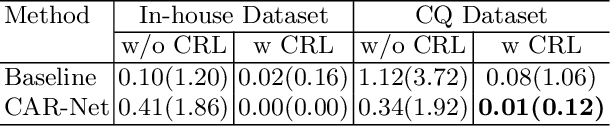
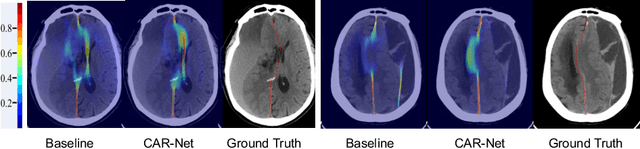
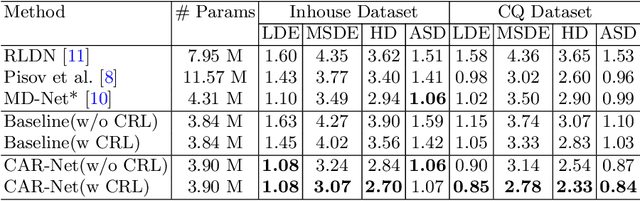
Brain midline delineation can facilitate the clinical evaluation of brain midline shift, which plays an important role in the diagnosis and prognosis of various brain pathology. Nevertheless, there are still great challenges with brain midline delineation, such as the largely deformed midline caused by the mass effect and the possible morphological failure that the predicted midline is not a connected curve. To address these challenges, we propose a context-aware refinement network (CAR-Net) to refine and integrate the feature pyramid representation generated by the UNet. Consequently, the proposed CAR-Net explores more discriminative contextual features and a larger receptive field, which is of great importance to predict largely deformed midline. For keeping the structural connectivity of the brain midline, we introduce a novel connectivity regular loss (CRL) to punish the disconnectivity between adjacent coordinates. Moreover, we address the ignored prerequisite of previous regression-based methods that the brain CT image must be in the standard pose. A simple pose rectification network is presented to align the source input image to the standard pose image. Extensive experimental results on the CQ dataset and one inhouse dataset show that the proposed method requires fewer parameters and outperforms three state-of-the-art methods in terms of four evaluation metrics. Code is available at https://github.com/ShawnBIT/Brain-Midline-Detection.
ChestX-Det10: Chest X-ray Dataset on Detection of Thoracic Abnormalities
Jun 19, 2020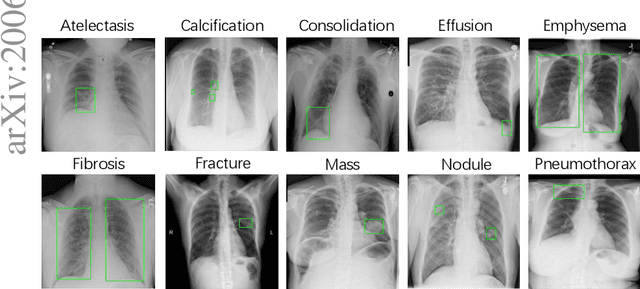

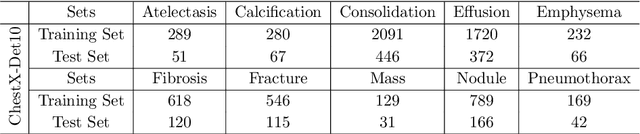

Instance level detection of thoracic diseases or abnormalities are crucial for automatic diagnosis in chest X-ray images. Most existing works on chest X-rays focus on disease classification and weakly supervised localization. In order to push forward the research on disease classification and localization on chest X-rays. We provide a new benchmark called ChestX-det10, including box-level annotations of 10 categories of disease/abnormality of $\sim$ 3,500 images. The annotations are located at https://github.com/Deepwise-AILab/ChestX-Det10-Dataset.