 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCF-VLA: Efficient Coarse-to-Fine Action Generation for Vision-Language-Action Policies
Apr 28, 2026Flow-based vision-language-action (VLA) policies offer strong expressivity for action generation, but suffer from a fundamental inefficiency: multi-step inference is required to recover action structure from uninformative Gaussian noise, leading to a poor efficiency-quality trade-off under real-time constraints. We address this issue by rethinking the role of the starting point in generative action modeling. Instead of shortening the sampling trajectory, we propose CF-VLA, a coarse-to-fine two-stage formulation that restructures action generation into a coarse initialization step that constructs an action-aware starting point, followed by a single-step local refinement that corrects residual errors. Concretely, the coarse stage learns a conditional posterior over endpoint velocity to transform Gaussian noise into a structured initialization, while the fine stage performs a fixed-time refinement from this initialization. To stabilize training, we introduce a stepwise strategy that first learns a controlled coarse predictor and then performs joint optimization. Experiments on CALVIN and LIBERO show that our method establishes a strong efficiency-performance frontier under low-NFE (Number of Function Evaluations) regimes: it consistently outperforms existing NFE=2 methods, matches or surpasses the NFE=10 $π_{0.5}$ baseline on several metrics, reduces action sampling latency by 75.4%, and achieves the best average real-robot success rate of 83.0%, outperforming MIP by 19.5 points and $π_{0.5}$ by 4.0 points. These results suggest that structured, coarse-to-fine generation enables both strong performance and efficient inference. Our code is available at https://github.com/EmbodiedAI-RoboTron/CF-VLA.
A Teacher-Student Framework for Semi-supervised Medical Image Segmentation From Mixed Supervision
Oct 23, 2020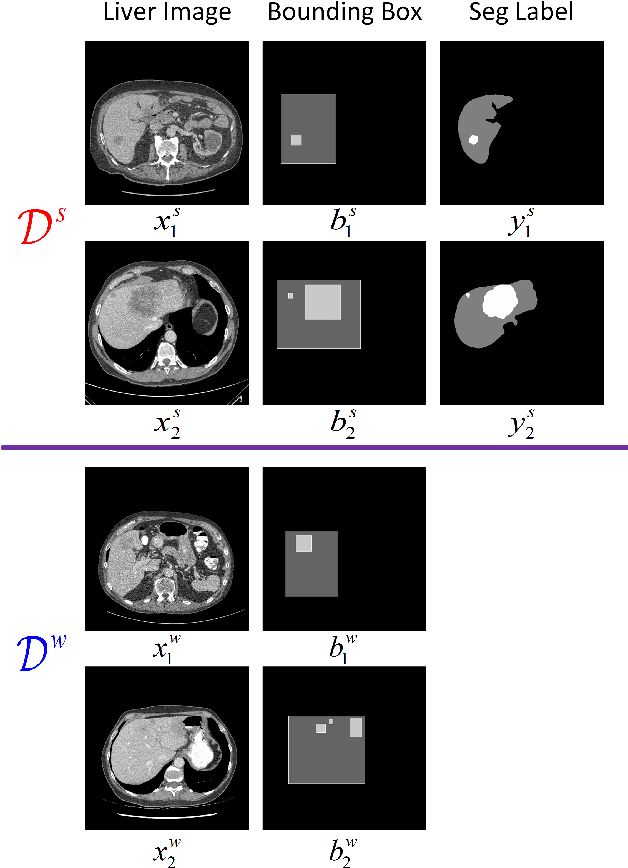
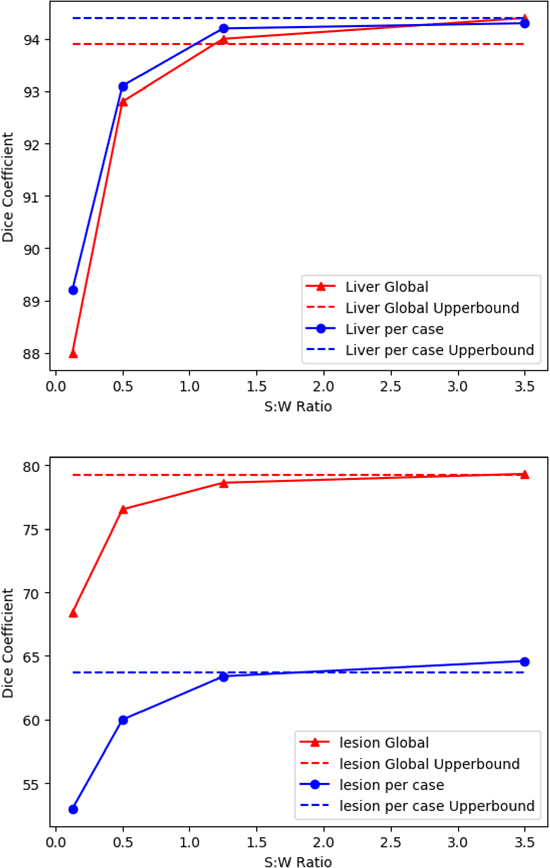
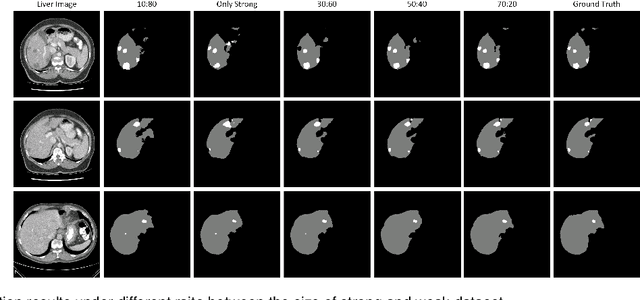
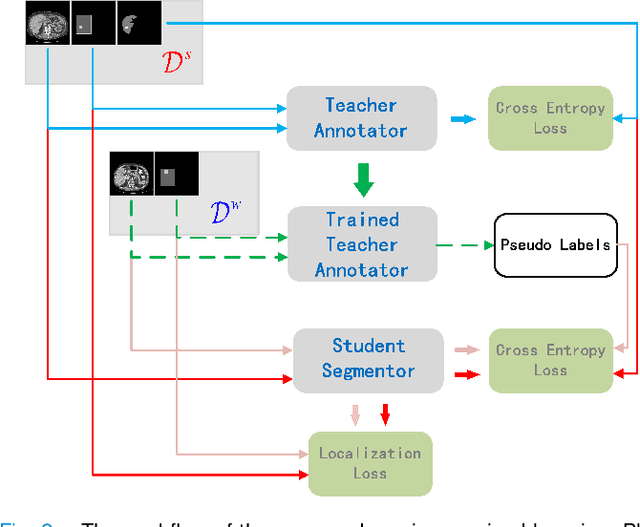
Standard segmentation of medical images based on full-supervised convolutional networks demands accurate dense annotations. Such learning framework is built on laborious manual annotation with restrict demands for expertise, leading to insufficient high-quality labels. To overcome such limitation and exploit massive weakly labeled data, we relaxed the rigid labeling requirement and developed a semi-supervised learning framework based on a teacher-student fashion for organ and lesion segmentation with partial dense-labeled supervision and supplementary loose bounding-box supervision which are easier to acquire. Observing the geometrical relation of an organ and its inner lesions in most cases, we propose a hierarchical organ-to-lesion (O2L) attention module in a teacher segmentor to produce pseudo-labels. Then a student segmentor is trained with combinations of manual-labeled and pseudo-labeled annotations. We further proposed a localization branch realized via an aggregation of high-level features in a deep decoder to predict locations of organ and lesion, which enriches student segmentor with precise localization information. We validated each design in our model on LiTS challenge datasets by ablation study and showed its state-of-the-art performance compared with recent methods. We show our model is robust to the quality of bounding box and achieves comparable performance compared with full-supervised learning methods.