 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFederated Client-tailored Adapter for Medical Image Segmentation
Apr 25, 2025Medical image segmentation in X-ray images is beneficial for computer-aided diagnosis and lesion localization. Existing methods mainly fall into a centralized learning paradigm, which is inapplicable in the practical medical scenario that only has access to distributed data islands. Federated Learning has the potential to offer a distributed solution but struggles with heavy training instability due to client-wise domain heterogeneity (including distribution diversity and class imbalance). In this paper, we propose a novel Federated Client-tailored Adapter (FCA) framework for medical image segmentation, which achieves stable and client-tailored adaptive segmentation without sharing sensitive local data. Specifically, the federated adapter stirs universal knowledge in off-the-shelf medical foundation models to stabilize the federated training process. In addition, we develop two client-tailored federated updating strategies that adaptively decompose the adapter into common and individual components, then globally and independently update the parameter groups associated with common client-invariant and individual client-specific units, respectively. They further stabilize the heterogeneous federated learning process and realize optimal client-tailored instead of sub-optimal global-compromised segmentation models. Extensive experiments on three large-scale datasets demonstrate the effectiveness and superiority of the proposed FCA framework for federated medical segmentation.
Clinical Domain Knowledge-Derived Template Improves Post Hoc AI Explanations in Pneumothorax Classification
Mar 26, 2024



Background: Pneumothorax is an acute thoracic disease caused by abnormal air collection between the lungs and chest wall. To address the opaqueness often associated with deep learning (DL) models, explainable artificial intelligence (XAI) methods have been introduced to outline regions related to pneumothorax diagnoses made by DL models. However, these explanations sometimes diverge from actual lesion areas, highlighting the need for further improvement. Method: We propose a template-guided approach to incorporate the clinical knowledge of pneumothorax into model explanations generated by XAI methods, thereby enhancing the quality of these explanations. Utilizing one lesion delineation created by radiologists, our approach first generates a template that represents potential areas of pneumothorax occurrence. This template is then superimposed on model explanations to filter out extraneous explanations that fall outside the template's boundaries. To validate its efficacy, we carried out a comparative analysis of three XAI methods with and without our template guidance when explaining two DL models in two real-world datasets. Results: The proposed approach consistently improved baseline XAI methods across twelve benchmark scenarios built on three XAI methods, two DL models, and two datasets. The average incremental percentages, calculated by the performance improvements over the baseline performance, were 97.8% in Intersection over Union (IoU) and 94.1% in Dice Similarity Coefficient (DSC) when comparing model explanations and ground-truth lesion areas. Conclusions: In the context of pneumothorax diagnoses, we proposed a template-guided approach for improving AI explanations. We anticipate that our template guidance will forge a fresh approach to elucidating AI models by integrating clinical domain expertise.
Progressive Conservative Adaptation for Evolving Target Domains
Feb 07, 2024Conventional domain adaptation typically transfers knowledge from a source domain to a stationary target domain. However, in many real-world cases, target data usually emerge sequentially and have continuously evolving distributions. Restoring and adapting to such target data results in escalating computational and resource consumption over time. Hence, it is vital to devise algorithms to address the evolving domain adaptation (EDA) problem, \emph{i.e.,} adapting models to evolving target domains without access to historic target domains. To achieve this goal, we propose a simple yet effective approach, termed progressive conservative adaptation (PCAda). To manage new target data that diverges from previous distributions, we fine-tune the classifier head based on the progressively updated class prototypes. Moreover, as adjusting to the most recent target domain can interfere with the features learned from previous target domains, we develop a conservative sparse attention mechanism. This mechanism restricts feature adaptation within essential dimensions, thus easing the inference related to historical knowledge. The proposed PCAda is implemented with a meta-learning framework, which achieves the fast adaptation of the classifier with the help of the progressively updated class prototypes in the inner loop and learns a generalized feature without severely interfering with the historic knowledge via the conservative sparse attention in the outer loop. Experiments on Rotated MNIST, Caltran, and Portraits datasets demonstrate the effectiveness of our method.
Leveraging Frequency Domain Learning in 3D Vessel Segmentation
Jan 11, 2024Coronary microvascular disease constitutes a substantial risk to human health. Employing computer-aided analysis and diagnostic systems, medical professionals can intervene early in disease progression, with 3D vessel segmentation serving as a crucial component. Nevertheless, conventional U-Net architectures tend to yield incoherent and imprecise segmentation outcomes, particularly for small vessel structures. While models with attention mechanisms, such as Transformers and large convolutional kernels, demonstrate superior performance, their extensive computational demands during training and inference lead to increased time complexity. In this study, we leverage Fourier domain learning as a substitute for multi-scale convolutional kernels in 3D hierarchical segmentation models, which can reduce computational expenses while preserving global receptive fields within the network. Furthermore, a zero-parameter frequency domain fusion method is designed to improve the skip connections in U-Net architecture. Experimental results on a public dataset and an in-house dataset indicate that our novel Fourier transformation-based network achieves remarkable dice performance (84.37\% on ASACA500 and 80.32\% on ImageCAS) in tubular vessel segmentation tasks and substantially reduces computational requirements without compromising global receptive fields.
TeacherLM: Teaching to Fish Rather Than Giving the Fish, Language Modeling Likewise
Oct 31, 2023



Large Language Models (LLMs) exhibit impressive reasoning and data augmentation capabilities in various NLP tasks. However, what about small models? In this work, we propose TeacherLM-7.1B, capable of annotating relevant fundamentals, chain of thought, and common mistakes for most NLP samples, which makes annotation more than just an answer, thus allowing other models to learn "why" instead of just "what". The TeacherLM-7.1B model achieved a zero-shot score of 52.3 on MMLU, surpassing most models with over 100B parameters. Even more remarkable is its data augmentation ability. Based on TeacherLM-7.1B, we augmented 58 NLP datasets and taught various student models with different parameters from OPT and BLOOM series in a multi-task setting. The experimental results indicate that the data augmentation provided by TeacherLM has brought significant benefits. We will release the TeacherLM series of models and augmented datasets as open-source.
Identity-Preserving Talking Face Generation with Landmark and Appearance Priors
May 15, 2023



Generating talking face videos from audio attracts lots of research interest. A few person-specific methods can generate vivid videos but require the target speaker's videos for training or fine-tuning. Existing person-generic methods have difficulty in generating realistic and lip-synced videos while preserving identity information. To tackle this problem, we propose a two-stage framework consisting of audio-to-landmark generation and landmark-to-video rendering procedures. First, we devise a novel Transformer-based landmark generator to infer lip and jaw landmarks from the audio. Prior landmark characteristics of the speaker's face are employed to make the generated landmarks coincide with the facial outline of the speaker. Then, a video rendering model is built to translate the generated landmarks into face images. During this stage, prior appearance information is extracted from the lower-half occluded target face and static reference images, which helps generate realistic and identity-preserving visual content. For effectively exploring the prior information of static reference images, we align static reference images with the target face's pose and expression based on motion fields. Moreover, auditory features are reused to guarantee that the generated face images are well synchronized with the audio. Extensive experiments demonstrate that our method can produce more realistic, lip-synced, and identity-preserving videos than existing person-generic talking face generation methods.
Graph Convolution Based Cross-Network Multi-Scale Feature Fusion for Deep Vessel Segmentation
Jan 06, 2023



Vessel segmentation is widely used to help with vascular disease diagnosis. Vessels reconstructed using existing methods are often not sufficiently accurate to meet clinical use standards. This is because 3D vessel structures are highly complicated and exhibit unique characteristics, including sparsity and anisotropy. In this paper, we propose a novel hybrid deep neural network for vessel segmentation. Our network consists of two cascaded subnetworks performing initial and refined segmentation respectively. The second subnetwork further has two tightly coupled components, a traditional CNN-based U-Net and a graph U-Net. Cross-network multi-scale feature fusion is performed between these two U-shaped networks to effectively support high-quality vessel segmentation. The entire cascaded network can be trained from end to end. The graph in the second subnetwork is constructed according to a vessel probability map as well as appearance and semantic similarities in the original CT volume. To tackle the challenges caused by the sparsity and anisotropy of vessels, a higher percentage of graph nodes are distributed in areas that potentially contain vessels while a higher percentage of edges follow the orientation of potential nearbyvessels. Extensive experiments demonstrate our deep network achieves state-of-the-art 3D vessel segmentation performance on multiple public and in-house datasets.
Mix and Reason: Reasoning over Semantic Topology with Data Mixing for Domain Generalization
Oct 14, 2022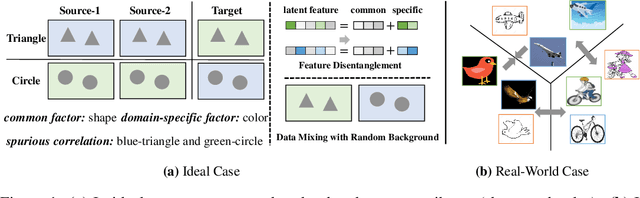
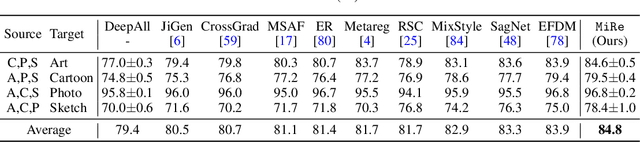
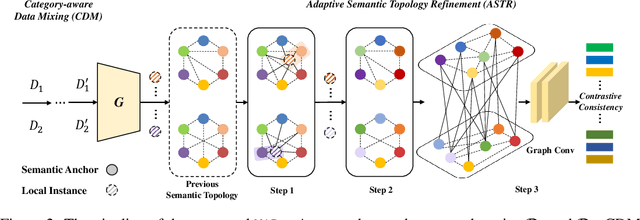
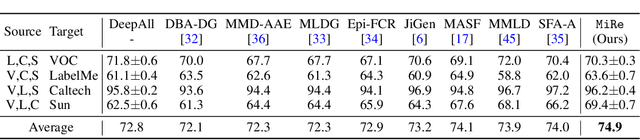
Domain generalization (DG) enables generalizing a learning machine from multiple seen source domains to an unseen target one. The general objective of DG methods is to learn semantic representations that are independent of domain labels, which is theoretically sound but empirically challenged due to the complex mixture of common and domain-specific factors. Although disentangling the representations into two disjoint parts has been gaining momentum in DG, the strong presumption over the data limits its efficacy in many real-world scenarios. In this paper, we propose Mix and Reason (\mire), a new DG framework that learns semantic representations via enforcing the structural invariance of semantic topology. \mire\ consists of two key components, namely, Category-aware Data Mixing (CDM) and Adaptive Semantic Topology Refinement (ASTR). CDM mixes two images from different domains in virtue of activation maps generated by two complementary classification losses, making the classifier focus on the representations of semantic objects. ASTR introduces relation graphs to represent semantic topology, which is progressively refined via the interactions between local feature aggregation and global cross-domain relational reasoning. Experiments on multiple DG benchmarks validate the effectiveness and robustness of the proposed \mire.
Deep 3D Vessel Segmentation based on Cross Transformer Network
Aug 23, 2022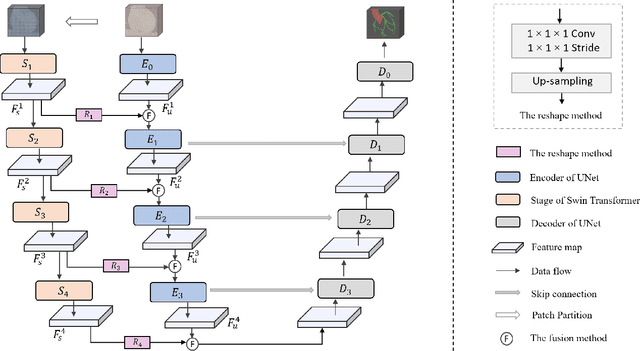
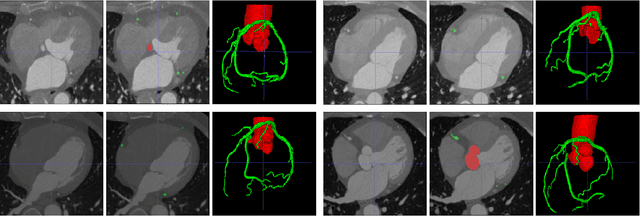
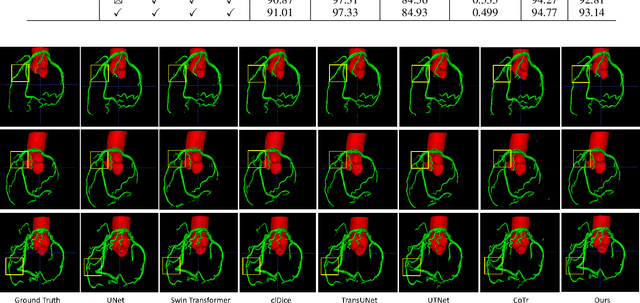
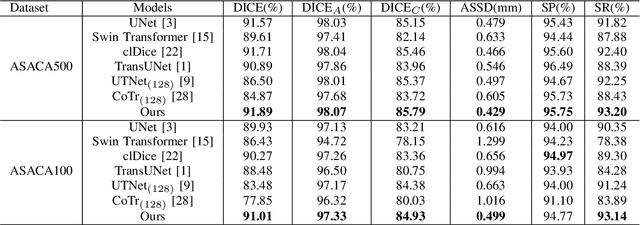
The coronary microvascular disease poses a great threat to human health. Computer-aided analysis/diagnosis systems help physicians intervene in the disease at early stages, where 3D vessel segmentation is a fundamental step. However, there is a lack of carefully annotated dataset to support algorithm development and evaluation. On the other hand, the commonly-used U-Net structures often yield disconnected and inaccurate segmentation results, especially for small vessel structures. In this paper, motivated by the data scarcity, we first construct two large-scale vessel segmentation datasets consisting of 100 and 500 computed tomography (CT) volumes with pixel-level annotations by experienced radiologists. To enhance the U-Net, we further propose the cross transformer network (CTN) for fine-grained vessel segmentation. In CTN, a transformer module is constructed in parallel to a U-Net to learn long-distance dependencies between different anatomical regions; and these dependencies are communicated to the U-Net at multiple stages to endow it with global awareness. Experimental results on the two in-house datasets indicate that this hybrid model alleviates unexpected disconnections by considering topological information across regions. Our codes, together with the trained models are made publicly available at https://github.com/qibaolian/ctn.
Structure Regularized Attentive Network for Automatic Femoral Head Necrosis Diagnosis and Localization
Aug 23, 2022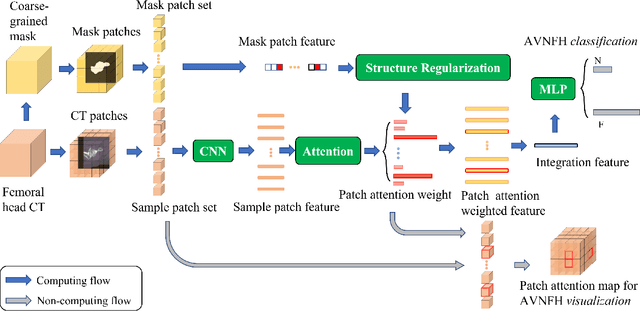
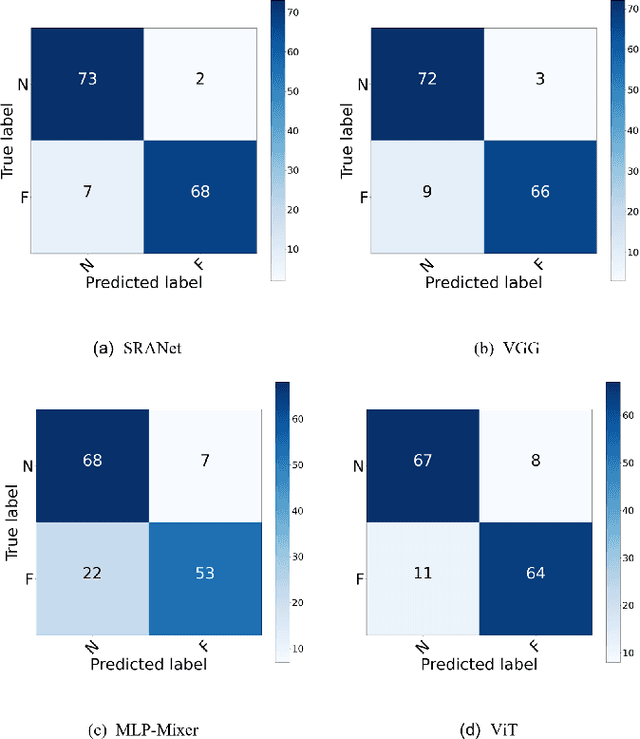
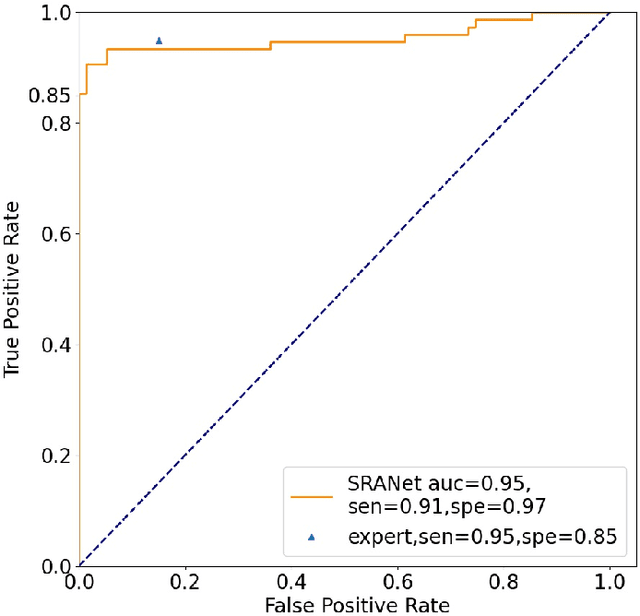
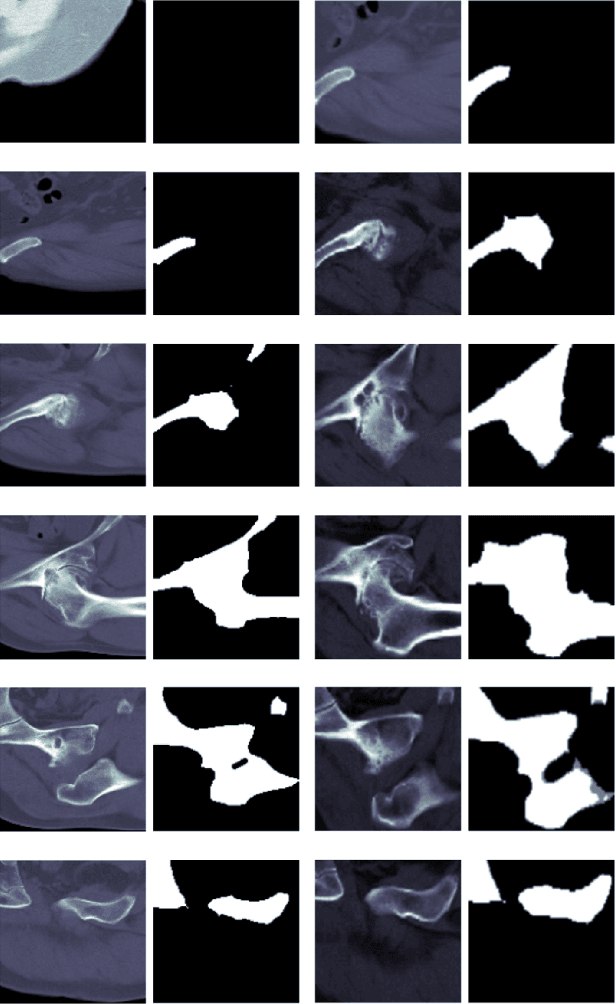
In recent years, several works have adopted the convolutional neural network (CNN) to diagnose the avascular necrosis of the femoral head (AVNFH) based on X-ray images or magnetic resonance imaging (MRI). However, due to the tissue overlap, X-ray images are difficult to provide fine-grained features for early diagnosis. MRI, on the other hand, has a long imaging time, is more expensive, making it impractical in mass screening. Computed tomography (CT) shows layer-wise tissues, is faster to image, and is less costly than MRI. However, to our knowledge, there is no work on CT-based automated diagnosis of AVNFH. In this work, we collected and labeled a large-scale dataset for AVNFH ranking. In addition, existing end-to-end CNNs only yields the classification result and are difficult to provide more information for doctors in diagnosis. To address this issue, we propose the structure regularized attentive network (SRANet), which is able to highlight the necrotic regions during classification based on patch attention. SRANet extracts features in chunks of images, obtains weight via the attention mechanism to aggregate the features, and constrains them by a structural regularizer with prior knowledge to improve the generalization. SRANet was evaluated on our AVNFH-CT dataset. Experimental results show that SRANet is superior to CNNs for AVNFH classification, moreover, it can localize lesions and provide more information to assist doctors in diagnosis. Our codes are made public at https://github.com/tomas-lilingfeng/SRANet.