 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMeta-information-aware Dual-path Transformer for Differential Diagnosis of Multi-type Pancreatic Lesions in Multi-phase CT
Mar 02, 2023Pancreatic cancer is one of the leading causes of cancer-related death. Accurate detection, segmentation, and differential diagnosis of the full taxonomy of pancreatic lesions, i.e., normal, seven major types of lesions, and other lesions, is critical to aid the clinical decision-making of patient management and treatment. However, existing works focus on segmentation and classification for very specific lesion types (PDAC) or groups. Moreover, none of the previous work considers using lesion prevalence-related non-imaging patient information to assist the differential diagnosis. To this end, we develop a meta-information-aware dual-path transformer and exploit the feasibility of classification and segmentation of the full taxonomy of pancreatic lesions. Specifically, the proposed method consists of a CNN-based segmentation path (S-path) and a transformer-based classification path (C-path). The S-path focuses on initial feature extraction by semantic segmentation using a UNet-based network. The C-path utilizes both the extracted features and meta-information for patient-level classification based on stacks of dual-path transformer blocks that enhance the modeling of global contextual information. A large-scale multi-phase CT dataset of 3,096 patients with pathology-confirmed pancreatic lesion class labels, voxel-wise manual annotations of lesions from radiologists, and patient meta-information, was collected for training and evaluations. Our results show that our method can enable accurate classification and segmentation of the full taxonomy of pancreatic lesions, approaching the accuracy of the radiologist's report and significantly outperforming previous baselines. Results also show that adding the common meta-information, i.e., gender and age, can boost the model's performance, thus demonstrating the importance of meta-information for aiding pancreatic disease diagnosis.
Towards a Single Unified Model for Effective Detection, Segmentation, and Diagnosis of Eight Major Cancers Using a Large Collection of CT Scans
Jan 28, 2023



Human readers or radiologists routinely perform full-body multi-organ multi-disease detection and diagnosis in clinical practice, while most medical AI systems are built to focus on single organs with a narrow list of a few diseases. This might severely limit AI's clinical adoption. A certain number of AI models need to be assembled non-trivially to match the diagnostic process of a human reading a CT scan. In this paper, we construct a Unified Tumor Transformer (UniT) model to detect (tumor existence and location) and diagnose (tumor characteristics) eight major cancer-prevalent organs in CT scans. UniT is a query-based Mask Transformer model with the output of multi-organ and multi-tumor semantic segmentation. We decouple the object queries into organ queries, detection queries and diagnosis queries, and further establish hierarchical relationships among the three groups. This clinically-inspired architecture effectively assists inter- and intra-organ representation learning of tumors and facilitates the resolution of these complex, anatomically related multi-organ cancer image reading tasks. UniT is trained end-to-end using a curated large-scale CT images of 10,042 patients including eight major types of cancers and occurring non-cancer tumors (all are pathology-confirmed with 3D tumor masks annotated by radiologists). On the test set of 631 patients, UniT has demonstrated strong performance under a set of clinically relevant evaluation metrics, substantially outperforming both multi-organ segmentation methods and an assembly of eight single-organ expert models in tumor detection, segmentation, and diagnosis. Such a unified multi-cancer image reading model (UniT) can significantly reduce the number of false positives produced by combined multi-system models. This moves one step closer towards a universal high-performance cancer screening tool.
Rethinking Architecture Design for Tackling Data Heterogeneity in Federated Learning
Jun 10, 2021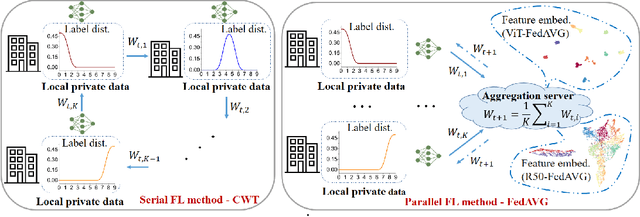
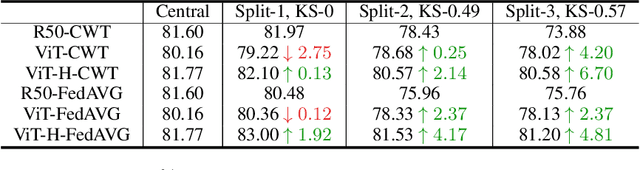
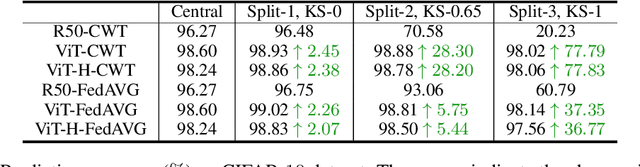

Federated learning is an emerging research paradigm enabling collaborative training of machine learning models among different organizations while keeping data private at each institution. Despite recent progress, there remain fundamental challenges such as lack of convergence and potential for catastrophic forgetting in federated learning across real-world heterogeneous devices. In this paper, we demonstrate that attention-based architectures (e.g., Transformers) are fairly robust to distribution shifts and hence improve federated learning over heterogeneous data. Concretely, we conduct the first rigorous empirical investigation of different neural architectures across a range of federated algorithms, real-world benchmarks, and heterogeneous data splits. Our experiments show that simply replacing convolutional networks with Transformers can greatly reduce catastrophic forgetting of previous devices, accelerate convergence, and reach a better global model, especially when dealing with heterogeneous data. We will release our code and pretrained models at https://github.com/Liangqiong/ViT-FL-main to encourage future exploration in robust architectures as an alternative to current research efforts on the optimization front.
The Medical Segmentation Decathlon
Jun 10, 2021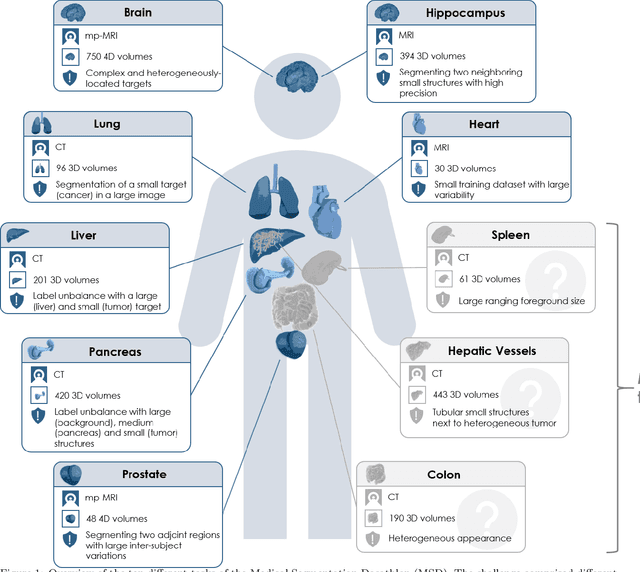
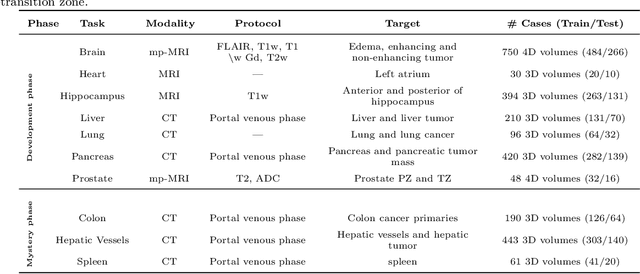
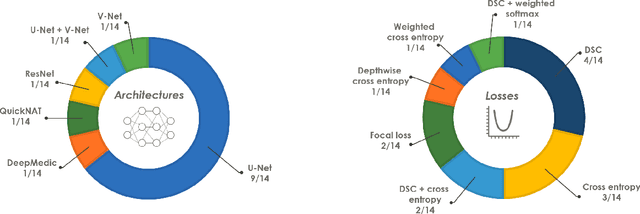
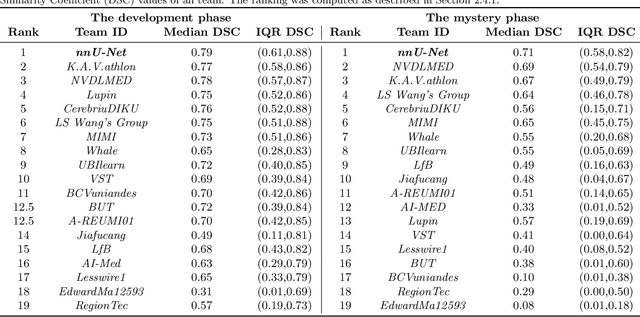
International challenges have become the de facto standard for comparative assessment of image analysis algorithms given a specific task. Segmentation is so far the most widely investigated medical image processing task, but the various segmentation challenges have typically been organized in isolation, such that algorithm development was driven by the need to tackle a single specific clinical problem. We hypothesized that a method capable of performing well on multiple tasks will generalize well to a previously unseen task and potentially outperform a custom-designed solution. To investigate the hypothesis, we organized the Medical Segmentation Decathlon (MSD) - a biomedical image analysis challenge, in which algorithms compete in a multitude of both tasks and modalities. The underlying data set was designed to explore the axis of difficulties typically encountered when dealing with medical images, such as small data sets, unbalanced labels, multi-site data and small objects. The MSD challenge confirmed that algorithms with a consistent good performance on a set of tasks preserved their good average performance on a different set of previously unseen tasks. Moreover, by monitoring the MSD winner for two years, we found that this algorithm continued generalizing well to a wide range of other clinical problems, further confirming our hypothesis. Three main conclusions can be drawn from this study: (1) state-of-the-art image segmentation algorithms are mature, accurate, and generalize well when retrained on unseen tasks; (2) consistent algorithmic performance across multiple tasks is a strong surrogate of algorithmic generalizability; (3) the training of accurate AI segmentation models is now commoditized to non AI experts.
Glance-and-Gaze Vision Transformer
Jun 04, 2021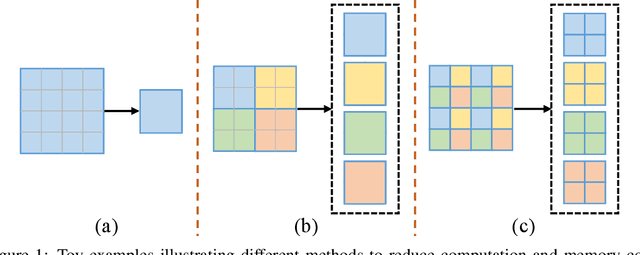
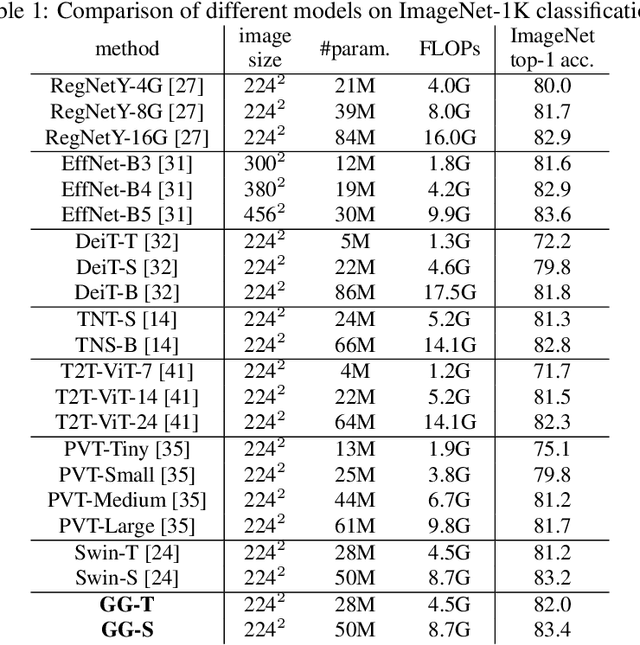
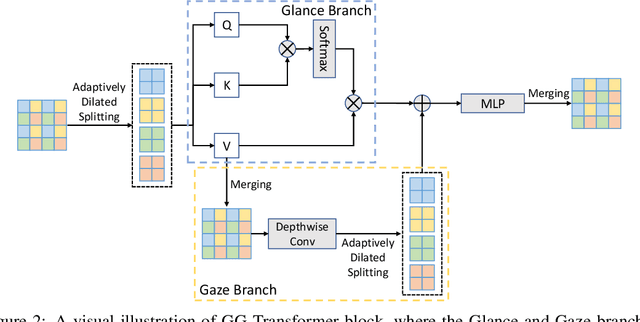
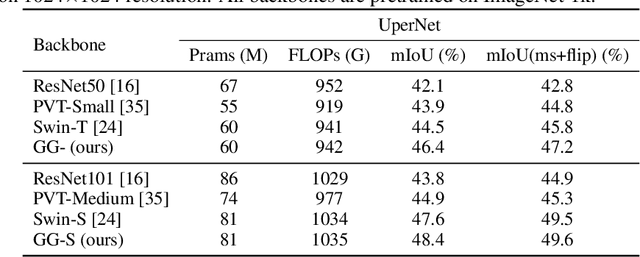
Recently, there emerges a series of vision Transformers, which show superior performance with a more compact model size than conventional convolutional neural networks, thanks to the strong ability of Transformers to model long-range dependencies. However, the advantages of vision Transformers also come with a price: Self-attention, the core part of Transformer, has a quadratic complexity to the input sequence length. This leads to a dramatic increase of computation and memory cost with the increase of sequence length, thus introducing difficulties when applying Transformers to the vision tasks that require dense predictions based on high-resolution feature maps. In this paper, we propose a new vision Transformer, named Glance-and-Gaze Transformer (GG-Transformer), to address the aforementioned issues. It is motivated by the Glance and Gaze behavior of human beings when recognizing objects in natural scenes, with the ability to efficiently model both long-range dependencies and local context. In GG-Transformer, the Glance and Gaze behavior is realized by two parallel branches: The Glance branch is achieved by performing self-attention on the adaptively-dilated partitions of the input, which leads to a linear complexity while still enjoying a global receptive field; The Gaze branch is implemented by a simple depth-wise convolutional layer, which compensates local image context to the features obtained by the Glance mechanism. We empirically demonstrate our method achieves consistently superior performance over previous state-of-the-art Transformers on various vision tasks and benchmarks. The codes and models will be made available at https://github.com/yucornetto/GG-Transformer.
Auto-FedAvg: Learnable Federated Averaging for Multi-Institutional Medical Image Segmentation
Apr 20, 2021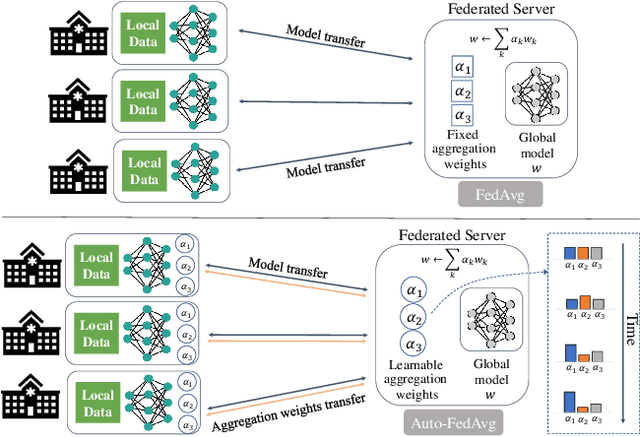
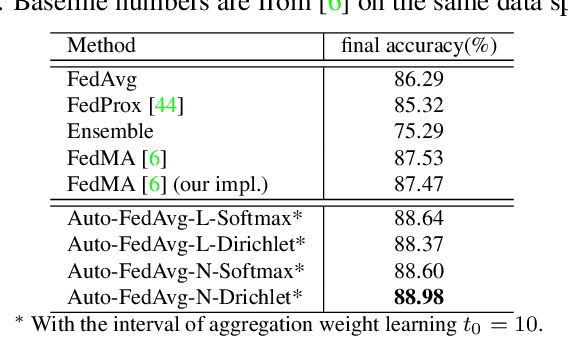
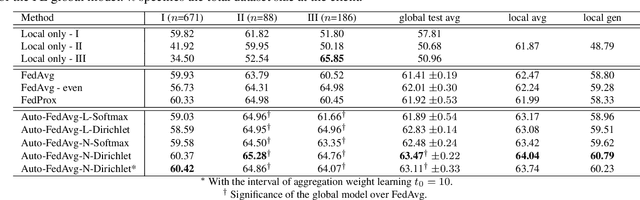
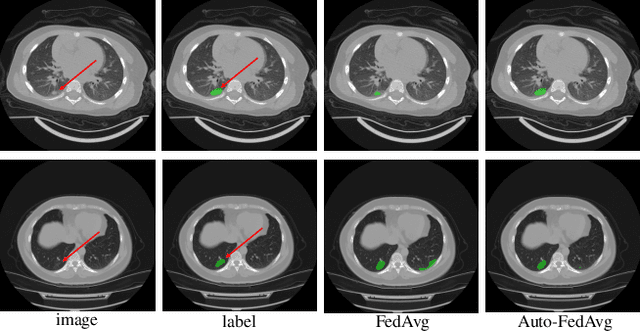
Federated learning (FL) enables collaborative model training while preserving each participant's privacy, which is particularly beneficial to the medical field. FedAvg is a standard algorithm that uses fixed weights, often originating from the dataset sizes at each client, to aggregate the distributed learned models on a server during the FL process. However, non-identical data distribution across clients, known as the non-i.i.d problem in FL, could make this assumption for setting fixed aggregation weights sub-optimal. In this work, we design a new data-driven approach, namely Auto-FedAvg, where aggregation weights are dynamically adjusted, depending on data distributions across data silos and the current training progress of the models. We disentangle the parameter set into two parts, local model parameters and global aggregation parameters, and update them iteratively with a communication-efficient algorithm. We first show the validity of our approach by outperforming state-of-the-art FL methods for image recognition on a heterogeneous data split of CIFAR-10. Furthermore, we demonstrate our algorithm's effectiveness on two multi-institutional medical image analysis tasks, i.e., COVID-19 lesion segmentation in chest CT and pancreas segmentation in abdominal CT.
Volumetric Medical Image Segmentation: A 3D Deep Coarse-to-fine Framework and Its Adversarial Examples
Oct 29, 2020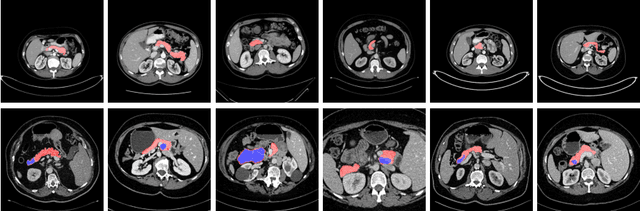
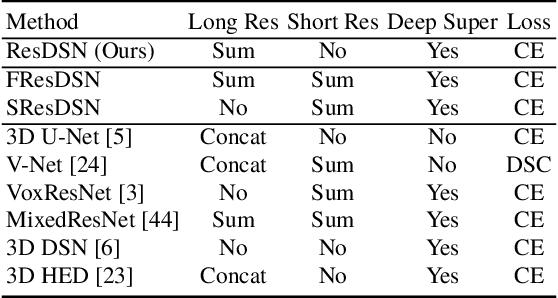

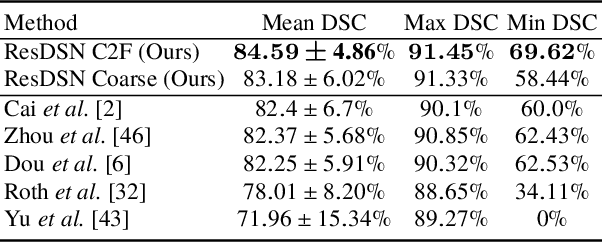
Although deep neural networks have been a dominant method for many 2D vision tasks, it is still challenging to apply them to 3D tasks, such as medical image segmentation, due to the limited amount of annotated 3D data and limited computational resources. In this chapter, by rethinking the strategy to apply 3D Convolutional Neural Networks to segment medical images, we propose a novel 3D-based coarse-to-fine framework to efficiently tackle these challenges. The proposed 3D-based framework outperforms their 2D counterparts by a large margin since it can leverage the rich spatial information along all three axes. We further analyze the threat of adversarial attacks on the proposed framework and show how to defense against the attack. We conduct experiments on three datasets, the NIH pancreas dataset, the JHMI pancreas dataset and the JHMI pathological cyst dataset, where the first two and the last one contain healthy and pathological pancreases respectively, and achieve the current state-of-the-art in terms of Dice-Sorensen Coefficient (DSC) on all of them. Especially, on the NIH pancreas segmentation dataset, we outperform the previous best by an average of over $2\%$, and the worst case is improved by $7\%$ to reach almost $70\%$, which indicates the reliability of our framework in clinical applications.
Uncertainty-aware multi-view co-training for semi-supervised medical image segmentation and domain adaptation
Jun 28, 2020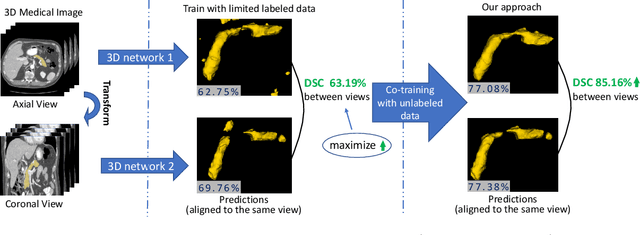
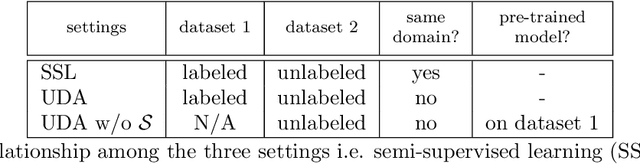
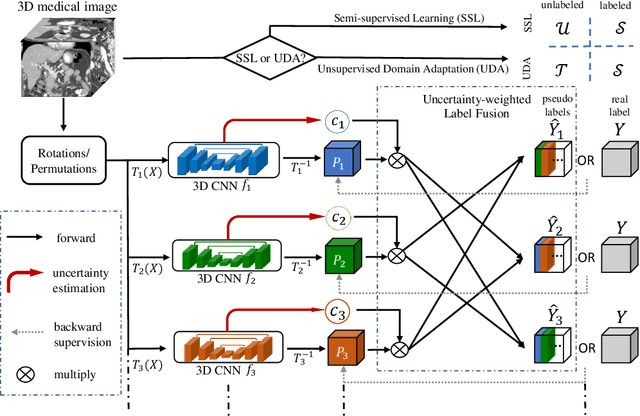
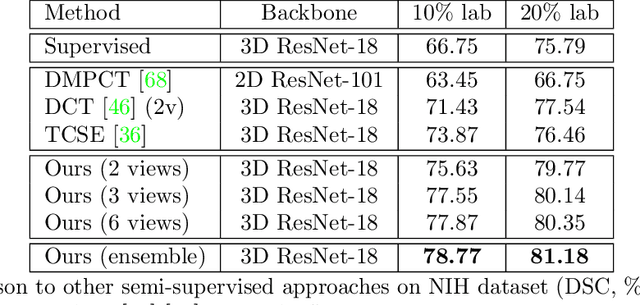
Although having achieved great success in medical image segmentation, deep learning-based approaches usually require large amounts of well-annotated data, which can be extremely expensive in the field of medical image analysis. Unlabeled data, on the other hand, is much easier to acquire. Semi-supervised learning and unsupervised domain adaptation both take the advantage of unlabeled data, and they are closely related to each other. In this paper, we propose uncertainty-aware multi-view co-training (UMCT), a unified framework that addresses these two tasks for volumetric medical image segmentation. Our framework is capable of efficiently utilizing unlabeled data for better performance. We firstly rotate and permute the 3D volumes into multiple views and train a 3D deep network on each view. We then apply co-training by enforcing multi-view consistency on unlabeled data, where an uncertainty estimation of each view is utilized to achieve accurate labeling. Experiments on the NIH pancreas segmentation dataset and a multi-organ segmentation dataset show state-of-the-art performance of the proposed framework on semi-supervised medical image segmentation. Under unsupervised domain adaptation settings, we validate the effectiveness of this work by adapting our multi-organ segmentation model to two pathological organs from the Medical Segmentation Decathlon Datasets. Additionally, we show that our UMCT-DA model can even effectively handle the challenging situation where labeled source data is inaccessible, demonstrating strong potentials for real-world applications.
* 19 pages, 6 figures, to appear in Medical Image Analysis. This article is an extension of the conference paper arXiv:1811.12506
Detecting Pancreatic Adenocarcinoma in Multi-phase CT Scans via Alignment Ensemble
Apr 03, 2020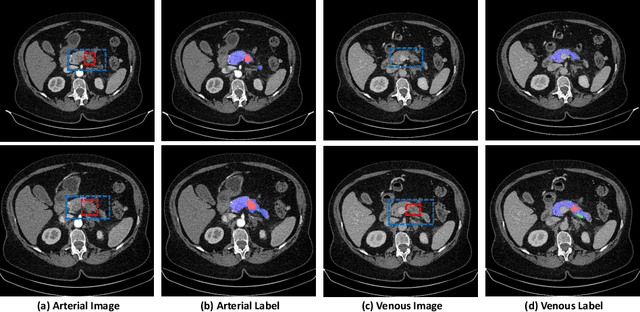
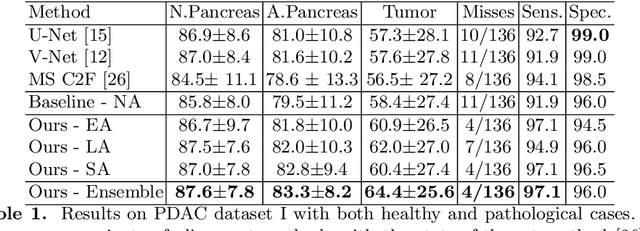
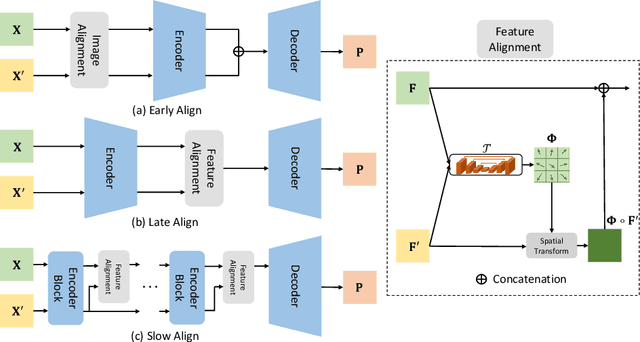
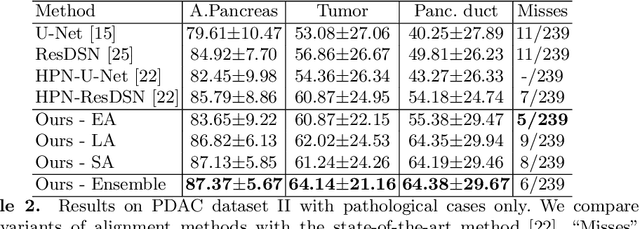
Pancreatic ductal adenocarcinoma (PDAC) is one of the most lethal cancers among population. Screening for PDACs in dynamic contrast-enhanced CT is beneficial for early diagnose. In this paper, we investigate the problem of automated detecting PDACs in multi-phase (arterial and venous) CT scans. Multiple phases provide more information than single phase, but they are unaligned and inhomogeneous in texture, making it difficult to combine cross-phase information seamlessly. We study multiple phase alignment strategies, i.e., early alignment (image registration), late alignment (high-level feature registration) and slow alignment (multi-level feature registration), and suggest an ensemble of all these alignments as a promising way to boost the performance of PDAC detection. We provide an extensive empirical evaluation on two PDAC datasets and show that the proposed alignment ensemble significantly outperforms previous state-of-the-art approaches, illustrating strong potential for clinical use.
Synthesize then Compare: Detecting Failures and Anomalies for Semantic Segmentation
Mar 18, 2020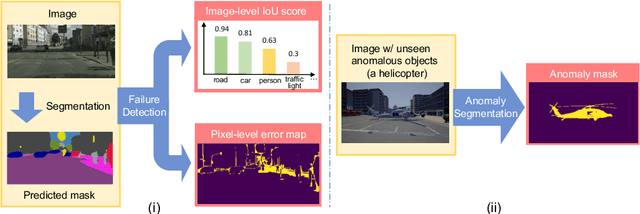
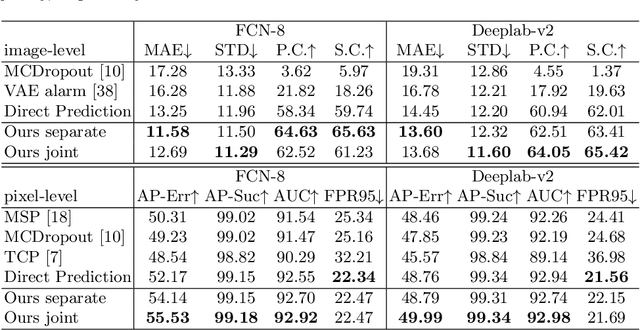
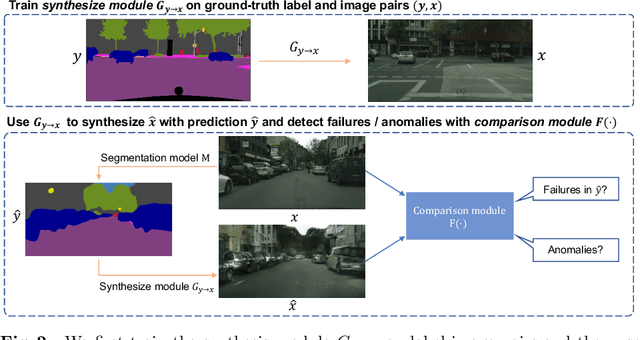
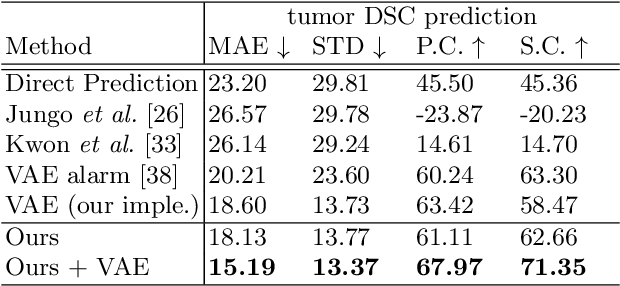
The ability to detect failures and anomalies are fundamental requirements for building reliable systems for computer vision applications, especially safety-critical applications of semantic segmentation, such as autonomous driving and medical image analysis. In this paper, we systematically study failure and anomaly detection for semantic segmentation and propose a unified framework, consisting of two modules, to address these two related problems. The first module is an image synthesis module, which generates a synthesized image from a segmentation layout map, and the second is a comparison module, which computes the difference between the synthesized image and the input image. We validate our framework on three challenging datasets and improve the state-of-the-arts by large margins, i.e., 6% AUPR-Error on Cityscapes, 10% DSC correlation on pancreatic tumor segmentation in MSD and 20% AUPR on StreetHazards anomaly segmentation.