 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePushing Auto-regressive Models for 3D Shape Generation at Capacity and Scalability
Feb 19, 2024Auto-regressive models have achieved impressive results in 2D image generation by modeling joint distributions in grid space. In this paper, we extend auto-regressive models to 3D domains, and seek a stronger ability of 3D shape generation by improving auto-regressive models at capacity and scalability simultaneously. Firstly, we leverage an ensemble of publicly available 3D datasets to facilitate the training of large-scale models. It consists of a comprehensive collection of approximately 900,000 objects, with multiple properties of meshes, points, voxels, rendered images, and text captions. This diverse labeled dataset, termed Objaverse-Mix, empowers our model to learn from a wide range of object variations. However, directly applying 3D auto-regression encounters critical challenges of high computational demands on volumetric grids and ambiguous auto-regressive order along grid dimensions, resulting in inferior quality of 3D shapes. To this end, we then present a novel framework Argus3D in terms of capacity. Concretely, our approach introduces discrete representation learning based on a latent vector instead of volumetric grids, which not only reduces computational costs but also preserves essential geometric details by learning the joint distributions in a more tractable order. The capacity of conditional generation can thus be realized by simply concatenating various conditioning inputs to the latent vector, such as point clouds, categories, images, and texts. In addition, thanks to the simplicity of our model architecture, we naturally scale up our approach to a larger model with an impressive 3.6 billion parameters, further enhancing the quality of versatile 3D generation. Extensive experiments on four generation tasks demonstrate that Argus3D can synthesize diverse and faithful shapes across multiple categories, achieving remarkable performance.
A Generalist FaceX via Learning Unified Facial Representation
Dec 31, 2023



This work presents FaceX framework, a novel facial generalist model capable of handling diverse facial tasks simultaneously. To achieve this goal, we initially formulate a unified facial representation for a broad spectrum of facial editing tasks, which macroscopically decomposes a face into fundamental identity, intra-personal variation, and environmental factors. Based on this, we introduce Facial Omni-Representation Decomposing (FORD) for seamless manipulation of various facial components, microscopically decomposing the core aspects of most facial editing tasks. Furthermore, by leveraging the prior of a pretrained StableDiffusion (SD) to enhance generation quality and accelerate training, we design Facial Omni-Representation Steering (FORS) to first assemble unified facial representations and then effectively steer the SD-aware generation process by the efficient Facial Representation Controller (FRC). %Without any additional features, Our versatile FaceX achieves competitive performance compared to elaborate task-specific models on popular facial editing tasks. Full codes and models will be available at https://github.com/diffusion-facex/FaceX.
PortraitBooth: A Versatile Portrait Model for Fast Identity-preserved Personalization
Dec 11, 2023



Recent advancements in personalized image generation using diffusion models have been noteworthy. However, existing methods suffer from inefficiencies due to the requirement for subject-specific fine-tuning. This computationally intensive process hinders efficient deployment, limiting practical usability. Moreover, these methods often grapple with identity distortion and limited expression diversity. In light of these challenges, we propose PortraitBooth, an innovative approach designed for high efficiency, robust identity preservation, and expression-editable text-to-image generation, without the need for fine-tuning. PortraitBooth leverages subject embeddings from a face recognition model for personalized image generation without fine-tuning. It eliminates computational overhead and mitigates identity distortion. The introduced dynamic identity preservation strategy further ensures close resemblance to the original image identity. Moreover, PortraitBooth incorporates emotion-aware cross-attention control for diverse facial expressions in generated images, supporting text-driven expression editing. Its scalability enables efficient and high-quality image creation, including multi-subject generation. Extensive results demonstrate superior performance over other state-of-the-art methods in both single and multiple image generation scenarios.
Dynamic Frame Interpolation in Wavelet Domain
Sep 21, 2023



Video frame interpolation is an important low-level vision task, which can increase frame rate for more fluent visual experience. Existing methods have achieved great success by employing advanced motion models and synthesis networks. However, the spatial redundancy when synthesizing the target frame has not been fully explored, that can result in lots of inefficient computation. On the other hand, the computation compression degree in frame interpolation is highly dependent on both texture distribution and scene motion, which demands to understand the spatial-temporal information of each input frame pair for a better compression degree selection. In this work, we propose a novel two-stage frame interpolation framework termed WaveletVFI to address above problems. It first estimates intermediate optical flow with a lightweight motion perception network, and then a wavelet synthesis network uses flow aligned context features to predict multi-scale wavelet coefficients with sparse convolution for efficient target frame reconstruction, where the sparse valid masks that control computation in each scale are determined by a crucial threshold ratio. Instead of setting a fixed value like previous methods, we find that embedding a classifier in the motion perception network to learn a dynamic threshold for each sample can achieve more computation reduction with almost no loss of accuracy. On the common high resolution and animation frame interpolation benchmarks, proposed WaveletVFI can reduce computation up to 40% while maintaining similar accuracy, making it perform more efficiently against other state-of-the-arts. Code is available at https://github.com/ltkong218/WaveletVFI.
Multimodal-driven Talking Face Generation via a Unified Diffusion-based Generator
May 09, 2023



Multimodal-driven talking face generation refers to animating a portrait with the given pose, expression, and gaze transferred from the driving image and video, or estimated from the text and audio. However, existing methods ignore the potential of text modal, and their generators mainly follow the source-oriented feature rearrange paradigm coupled with unstable GAN frameworks. In this work, we first represent the emotion in the text prompt, which could inherit rich semantics from the CLIP, allowing flexible and generalized emotion control. We further reorganize these tasks as the target-oriented texture transfer and adopt the Diffusion Models. More specifically, given a textured face as the source and the rendered face projected from the desired 3DMM coefficients as the target, our proposed Texture-Geometry-aware Diffusion Model decomposes the complex transfer problem into multi-conditional denoising process, where a Texture Attention-based module accurately models the correspondences between appearance and geometry cues contained in source and target conditions, and incorporate extra implicit information for high-fidelity talking face generation. Additionally, TGDM can be gracefully tailored for face swapping. We derive a novel paradigm free of unstable seesaw-style optimization, resulting in simple, stable, and effective training and inference schemes. Extensive experiments demonstrate the superiority of our method.
High-fidelity Generalized Emotional Talking Face Generation with Multi-modal Emotion Space Learning
May 04, 2023



Recently, emotional talking face generation has received considerable attention. However, existing methods only adopt one-hot coding, image, or audio as emotion conditions, thus lacking flexible control in practical applications and failing to handle unseen emotion styles due to limited semantics. They either ignore the one-shot setting or the quality of generated faces. In this paper, we propose a more flexible and generalized framework. Specifically, we supplement the emotion style in text prompts and use an Aligned Multi-modal Emotion encoder to embed the text, image, and audio emotion modality into a unified space, which inherits rich semantic prior from CLIP. Consequently, effective multi-modal emotion space learning helps our method support arbitrary emotion modality during testing and could generalize to unseen emotion styles. Besides, an Emotion-aware Audio-to-3DMM Convertor is proposed to connect the emotion condition and the audio sequence to structural representation. A followed style-based High-fidelity Emotional Face generator is designed to generate arbitrary high-resolution realistic identities. Our texture generator hierarchically learns flow fields and animated faces in a residual manner. Extensive experiments demonstrate the flexibility and generalization of our method in emotion control and the effectiveness of high-quality face synthesis.
Learning Versatile 3D Shape Generation with Improved AR Models
Mar 26, 2023Auto-Regressive (AR) models have achieved impressive results in 2D image generation by modeling joint distributions in the grid space. While this approach has been extended to the 3D domain for powerful shape generation, it still has two limitations: expensive computations on volumetric grids and ambiguous auto-regressive order along grid dimensions. To overcome these limitations, we propose the Improved Auto-regressive Model (ImAM) for 3D shape generation, which applies discrete representation learning based on a latent vector instead of volumetric grids. Our approach not only reduces computational costs but also preserves essential geometric details by learning the joint distribution in a more tractable order. Moreover, thanks to the simplicity of our model architecture, we can naturally extend it from unconditional to conditional generation by concatenating various conditioning inputs, such as point clouds, categories, images, and texts. Extensive experiments demonstrate that ImAM can synthesize diverse and faithful shapes of multiple categories, achieving state-of-the-art performance.
High-Resolution GAN Inversion for Degraded Images in Large Diverse Datasets
Feb 07, 2023The last decades are marked by massive and diverse image data, which shows increasingly high resolution and quality. However, some images we obtained may be corrupted, affecting the perception and the application of downstream tasks. A generic method for generating a high-quality image from the degraded one is in demand. In this paper, we present a novel GAN inversion framework that utilizes the powerful generative ability of StyleGAN-XL for this problem. To ease the inversion challenge with StyleGAN-XL, Clustering \& Regularize Inversion (CRI) is proposed. Specifically, the latent space is firstly divided into finer-grained sub-spaces by clustering. Instead of initializing the inversion with the average latent vector, we approximate a centroid latent vector from the clusters, which generates an image close to the input image. Then, an offset with a regularization term is introduced to keep the inverted latent vector within a certain range. We validate our CRI scheme on multiple restoration tasks (i.e., inpainting, colorization, and super-resolution) of complex natural images, and show preferable quantitative and qualitative results. We further demonstrate our technique is robust in terms of data and different GAN models. To our best knowledge, we are the first to adopt StyleGAN-XL for generating high-quality natural images from diverse degraded inputs. Code is available at https://github.com/Booooooooooo/CRI.
Joint Learning Content and Degradation Aware Feature for Blind Super-Resolution
Aug 29, 2022
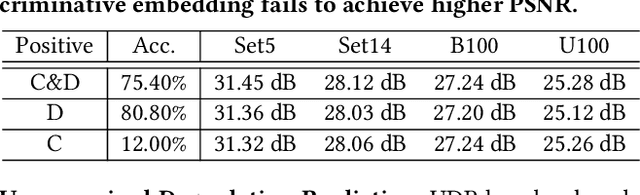
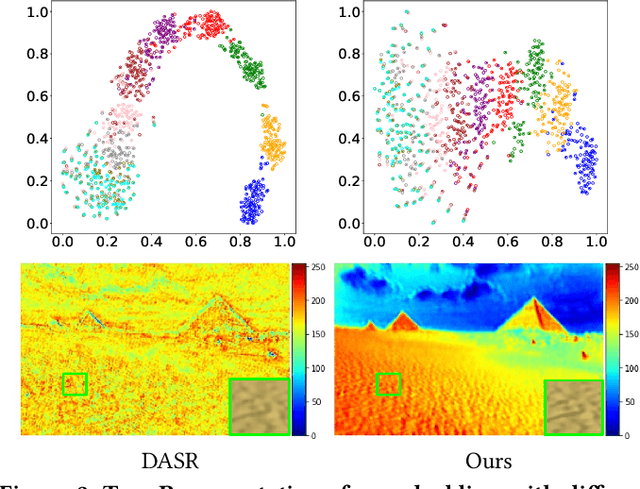
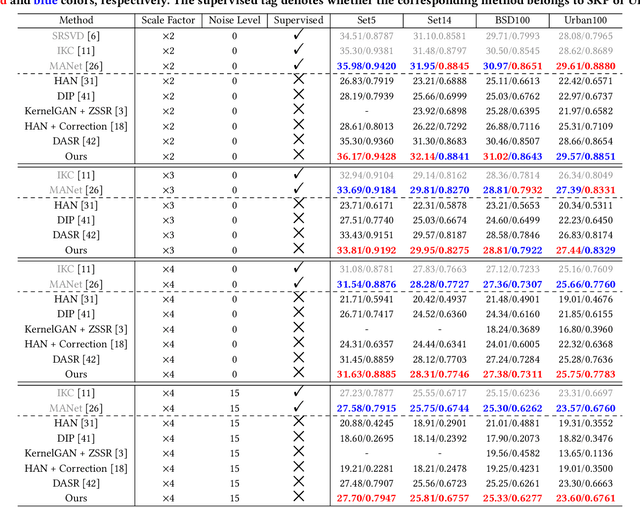
To achieve promising results on blind image super-resolution (SR), some attempts leveraged the low resolution (LR) images to predict the kernel and improve the SR performance. However, these Supervised Kernel Prediction (SKP) methods are impractical due to the unavailable real-world blur kernels. Although some Unsupervised Degradation Prediction (UDP) methods are proposed to bypass this problem, the \textit{inconsistency} between degradation embedding and SR feature is still challenging. By exploring the correlations between degradation embedding and SR feature, we observe that jointly learning the content and degradation aware feature is optimal. Based on this observation, a Content and Degradation aware SR Network dubbed CDSR is proposed. Specifically, CDSR contains three newly-established modules: (1) a Lightweight Patch-based Encoder (LPE) is applied to jointly extract content and degradation features; (2) a Domain Query Attention based module (DQA) is employed to adaptively reduce the inconsistency; (3) a Codebook-based Space Compress module (CSC) that can suppress the redundant information. Extensive experiments on several benchmarks demonstrate that the proposed CDSR outperforms the existing UDP models and achieves competitive performance on PSNR and SSIM even compared with the state-of-the-art SKP methods.
SeedFormer: Patch Seeds based Point Cloud Completion with Upsample Transformer
Jul 21, 2022
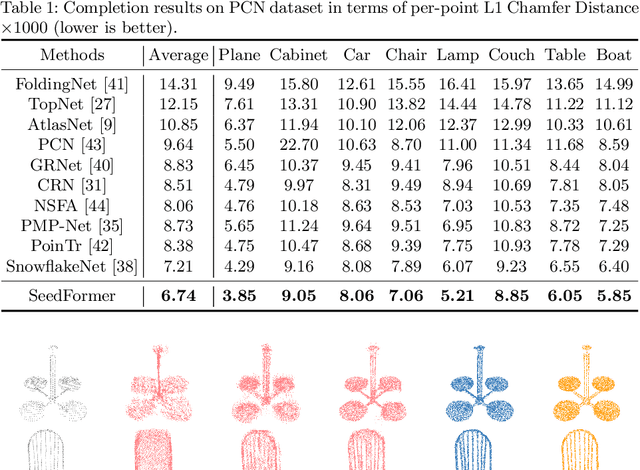
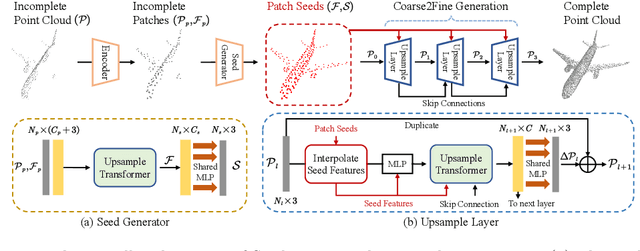
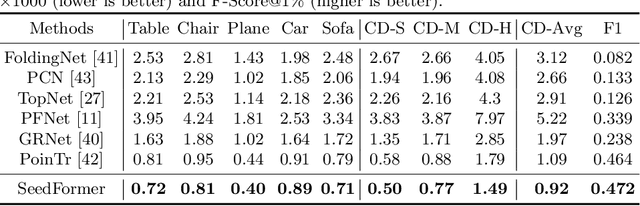
Point cloud completion has become increasingly popular among generation tasks of 3D point clouds, as it is a challenging yet indispensable problem to recover the complete shape of a 3D object from its partial observation. In this paper, we propose a novel SeedFormer to improve the ability of detail preservation and recovery in point cloud completion. Unlike previous methods based on a global feature vector, we introduce a new shape representation, namely Patch Seeds, which not only captures general structures from partial inputs but also preserves regional information of local patterns. Then, by integrating seed features into the generation process, we can recover faithful details for complete point clouds in a coarse-to-fine manner. Moreover, we devise an Upsample Transformer by extending the transformer structure into basic operations of point generators, which effectively incorporates spatial and semantic relationships between neighboring points. Qualitative and quantitative evaluations demonstrate that our method outperforms state-of-the-art completion networks on several benchmark datasets. Our code is available at https://github.com/hrzhou2/seedformer.