 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePushing Auto-regressive Models for 3D Shape Generation at Capacity and Scalability
Feb 19, 2024Auto-regressive models have achieved impressive results in 2D image generation by modeling joint distributions in grid space. In this paper, we extend auto-regressive models to 3D domains, and seek a stronger ability of 3D shape generation by improving auto-regressive models at capacity and scalability simultaneously. Firstly, we leverage an ensemble of publicly available 3D datasets to facilitate the training of large-scale models. It consists of a comprehensive collection of approximately 900,000 objects, with multiple properties of meshes, points, voxels, rendered images, and text captions. This diverse labeled dataset, termed Objaverse-Mix, empowers our model to learn from a wide range of object variations. However, directly applying 3D auto-regression encounters critical challenges of high computational demands on volumetric grids and ambiguous auto-regressive order along grid dimensions, resulting in inferior quality of 3D shapes. To this end, we then present a novel framework Argus3D in terms of capacity. Concretely, our approach introduces discrete representation learning based on a latent vector instead of volumetric grids, which not only reduces computational costs but also preserves essential geometric details by learning the joint distributions in a more tractable order. The capacity of conditional generation can thus be realized by simply concatenating various conditioning inputs to the latent vector, such as point clouds, categories, images, and texts. In addition, thanks to the simplicity of our model architecture, we naturally scale up our approach to a larger model with an impressive 3.6 billion parameters, further enhancing the quality of versatile 3D generation. Extensive experiments on four generation tasks demonstrate that Argus3D can synthesize diverse and faithful shapes across multiple categories, achieving remarkable performance.
PIXART-δ: Fast and Controllable Image Generation with Latent Consistency Models
Jan 10, 2024This technical report introduces PIXART-{\delta}, a text-to-image synthesis framework that integrates the Latent Consistency Model (LCM) and ControlNet into the advanced PIXART-{\alpha} model. PIXART-{\alpha} is recognized for its ability to generate high-quality images of 1024px resolution through a remarkably efficient training process. The integration of LCM in PIXART-{\delta} significantly accelerates the inference speed, enabling the production of high-quality images in just 2-4 steps. Notably, PIXART-{\delta} achieves a breakthrough 0.5 seconds for generating 1024x1024 pixel images, marking a 7x improvement over the PIXART-{\alpha}. Additionally, PIXART-{\delta} is designed to be efficiently trainable on 32GB V100 GPUs within a single day. With its 8-bit inference capability (von Platen et al., 2023), PIXART-{\delta} can synthesize 1024px images within 8GB GPU memory constraints, greatly enhancing its usability and accessibility. Furthermore, incorporating a ControlNet-like module enables fine-grained control over text-to-image diffusion models. We introduce a novel ControlNet-Transformer architecture, specifically tailored for Transformers, achieving explicit controllability alongside high-quality image generation. As a state-of-the-art, open-source image generation model, PIXART-{\delta} offers a promising alternative to the Stable Diffusion family of models, contributing significantly to text-to-image synthesis.
LCM-LoRA: A Universal Stable-Diffusion Acceleration Module
Nov 09, 2023



Latent Consistency Models (LCMs) have achieved impressive performance in accelerating text-to-image generative tasks, producing high-quality images with minimal inference steps. LCMs are distilled from pre-trained latent diffusion models (LDMs), requiring only ~32 A100 GPU training hours. This report further extends LCMs' potential in two aspects: First, by applying LoRA distillation to Stable-Diffusion models including SD-V1.5, SSD-1B, and SDXL, we have expanded LCM's scope to larger models with significantly less memory consumption, achieving superior image generation quality. Second, we identify the LoRA parameters obtained through LCM distillation as a universal Stable-Diffusion acceleration module, named LCM-LoRA. LCM-LoRA can be directly plugged into various Stable-Diffusion fine-tuned models or LoRAs without training, thus representing a universally applicable accelerator for diverse image generation tasks. Compared with previous numerical PF-ODE solvers such as DDIM, DPM-Solver, LCM-LoRA can be viewed as a plug-in neural PF-ODE solver that possesses strong generalization abilities. Project page: https://github.com/luosiallen/latent-consistency-model.
Large Trajectory Models are Scalable Motion Predictors and Planners
Oct 30, 2023



Motion prediction and planning are vital tasks in autonomous driving, and recent efforts have shifted to machine learning-based approaches. The challenges include understanding diverse road topologies, reasoning traffic dynamics over a long time horizon, interpreting heterogeneous behaviors, and generating policies in a large continuous state space. Inspired by the success of large language models in addressing similar complexities through model scaling, we introduce a scalable trajectory model called State Transformer (STR). STR reformulates the motion prediction and motion planning problems by arranging observations, states, and actions into one unified sequence modeling task. With a simple model design, STR consistently outperforms baseline approaches in both problems. Remarkably, experimental results reveal that large trajectory models (LTMs), such as STR, adhere to the scaling laws by presenting outstanding adaptability and learning efficiency. Qualitative results further demonstrate that LTMs are capable of making plausible predictions in scenarios that diverge significantly from the training data distribution. LTMs also learn to make complex reasonings for long-term planning, without explicit loss designs or costly high-level annotations.
Latent Consistency Models: Synthesizing High-Resolution Images with Few-Step Inference
Oct 06, 2023



Latent Diffusion models (LDMs) have achieved remarkable results in synthesizing high-resolution images. However, the iterative sampling process is computationally intensive and leads to slow generation. Inspired by Consistency Models (song et al.), we propose Latent Consistency Models (LCMs), enabling swift inference with minimal steps on any pre-trained LDMs, including Stable Diffusion (rombach et al). Viewing the guided reverse diffusion process as solving an augmented probability flow ODE (PF-ODE), LCMs are designed to directly predict the solution of such ODE in latent space, mitigating the need for numerous iterations and allowing rapid, high-fidelity sampling. Efficiently distilled from pre-trained classifier-free guided diffusion models, a high-quality 768 x 768 2~4-step LCM takes only 32 A100 GPU hours for training. Furthermore, we introduce Latent Consistency Fine-tuning (LCF), a novel method that is tailored for fine-tuning LCMs on customized image datasets. Evaluation on the LAION-5B-Aesthetics dataset demonstrates that LCMs achieve state-of-the-art text-to-image generation performance with few-step inference. Project Page: https://latent-consistency-models.github.io/
Diff-Foley: Synchronized Video-to-Audio Synthesis with Latent Diffusion Models
Jun 29, 2023



The Video-to-Audio (V2A) model has recently gained attention for its practical application in generating audio directly from silent videos, particularly in video/film production. However, previous methods in V2A have limited generation quality in terms of temporal synchronization and audio-visual relevance. We present Diff-Foley, a synchronized Video-to-Audio synthesis method with a latent diffusion model (LDM) that generates high-quality audio with improved synchronization and audio-visual relevance. We adopt contrastive audio-visual pretraining (CAVP) to learn more temporally and semantically aligned features, then train an LDM with CAVP-aligned visual features on spectrogram latent space. The CAVP-aligned features enable LDM to capture the subtler audio-visual correlation via a cross-attention module. We further significantly improve sample quality with `double guidance'. Diff-Foley achieves state-of-the-art V2A performance on current large scale V2A dataset. Furthermore, we demonstrate Diff-Foley practical applicability and generalization capabilities via downstream finetuning. Project Page: see https://diff-foley.github.io/
ChatDB: Augmenting LLMs with Databases as Their Symbolic Memory
Jun 07, 2023



Large language models (LLMs) with memory are computationally universal. However, mainstream LLMs are not taking full advantage of memory, and the designs are heavily influenced by biological brains. Due to their approximate nature and proneness to the accumulation of errors, conventional neural memory mechanisms cannot support LLMs to simulate complex reasoning. In this paper, we seek inspiration from modern computer architectures to augment LLMs with symbolic memory for complex multi-hop reasoning. Such a symbolic memory framework is instantiated as an LLM and a set of SQL databases, where the LLM generates SQL instructions to manipulate the SQL databases. We validate the effectiveness of the proposed memory framework on a synthetic dataset requiring complex reasoning. The project website is available at https://chatdatabase.github.io/ .
Learning Versatile 3D Shape Generation with Improved AR Models
Mar 26, 2023Auto-Regressive (AR) models have achieved impressive results in 2D image generation by modeling joint distributions in the grid space. While this approach has been extended to the 3D domain for powerful shape generation, it still has two limitations: expensive computations on volumetric grids and ambiguous auto-regressive order along grid dimensions. To overcome these limitations, we propose the Improved Auto-regressive Model (ImAM) for 3D shape generation, which applies discrete representation learning based on a latent vector instead of volumetric grids. Our approach not only reduces computational costs but also preserves essential geometric details by learning the joint distribution in a more tractable order. Moreover, thanks to the simplicity of our model architecture, we can naturally extend it from unconditional to conditional generation by concatenating various conditioning inputs, such as point clouds, categories, images, and texts. Extensive experiments demonstrate that ImAM can synthesize diverse and faithful shapes of multiple categories, achieving state-of-the-art performance.
QS-Craft: Learning to Quantize, Scrabble and Craft for Conditional Human Motion Animation
Mar 22, 2022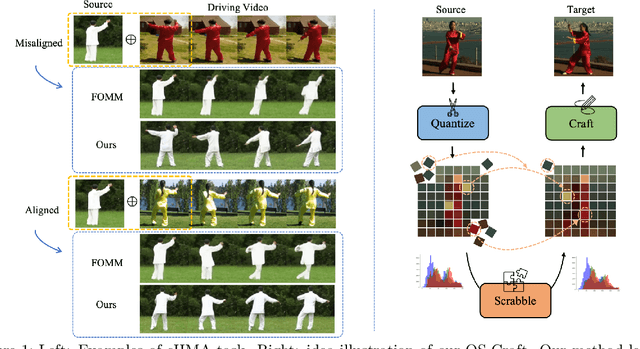
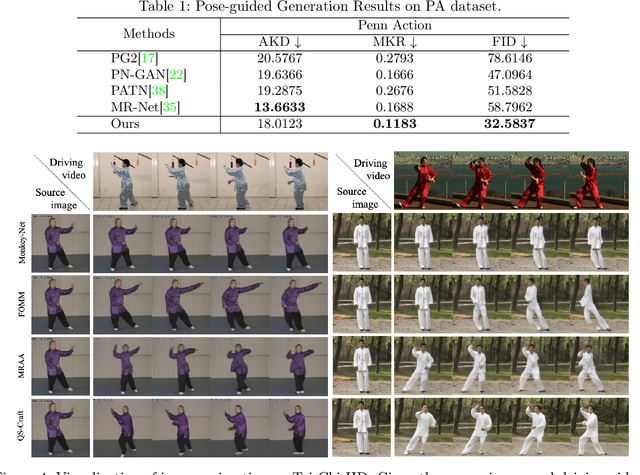
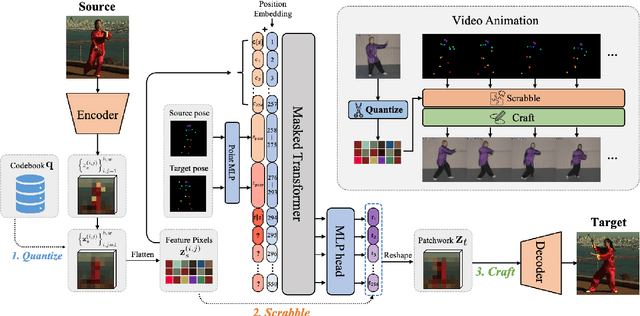
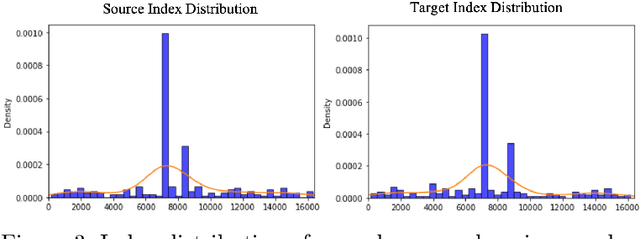
This paper studies the task of conditional Human Motion Animation (cHMA). Given a source image and a driving video, the model should animate the new frame sequence, in which the person in the source image should perform a similar motion as the pose sequence from the driving video. Despite the success of Generative Adversarial Network (GANs) methods in image and video synthesis, it is still very challenging to conduct cHMA due to the difficulty in efficiently utilizing the conditional guided information such as images or poses, and generating images of good visual quality. To this end, this paper proposes a novel model of learning to Quantize, Scrabble, and Craft (QS-Craft) for conditional human motion animation. The key novelties come from the newly introduced three key steps: quantize, scrabble and craft. Particularly, our QS-Craft employs transformer in its structure to utilize the attention architectures. The guided information is represented as a pose coordinate sequence extracted from the driving videos. Extensive experiments on human motion datasets validate the efficacy of our model.