 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAn Interpretability Evaluation Benchmark for Pre-trained Language Models
Jul 28, 2022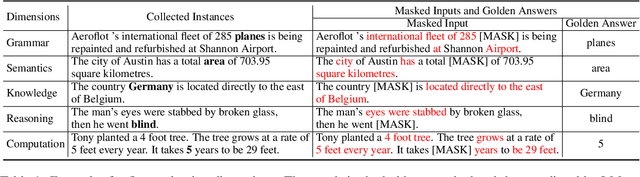
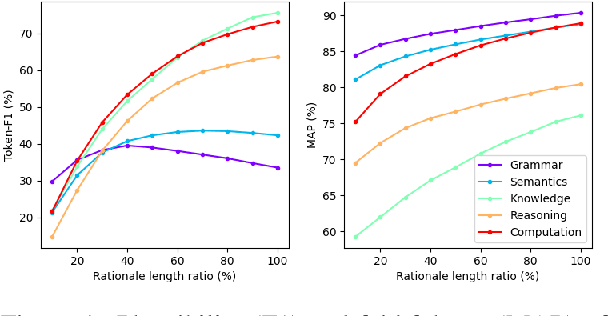

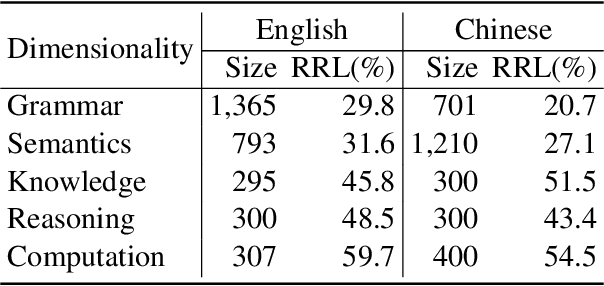
While pre-trained language models (LMs) have brought great improvements in many NLP tasks, there is increasing attention to explore capabilities of LMs and interpret their predictions. However, existing works usually focus only on a certain capability with some downstream tasks. There is a lack of datasets for directly evaluating the masked word prediction performance and the interpretability of pre-trained LMs. To fill in the gap, we propose a novel evaluation benchmark providing with both English and Chinese annotated data. It tests LMs abilities in multiple dimensions, i.e., grammar, semantics, knowledge, reasoning and computation. In addition, it provides carefully annotated token-level rationales that satisfy sufficiency and compactness. It contains perturbed instances for each original instance, so as to use the rationale consistency under perturbations as the metric for faithfulness, a perspective of interpretability. We conduct experiments on several widely-used pre-trained LMs. The results show that they perform very poorly on the dimensions of knowledge and computation. And their plausibility in all dimensions is far from satisfactory, especially when the rationale is short. In addition, the pre-trained LMs we evaluated are not robust on syntax-aware data. We will release this evaluation benchmark at \url{http://xyz}, and hope it can facilitate the research progress of pre-trained LMs.
Adaptive Assignment for Geometry Aware Local Feature Matching
Jul 18, 2022
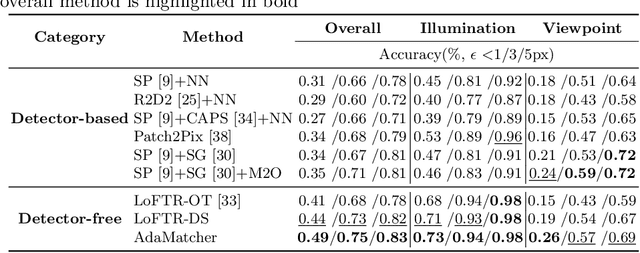
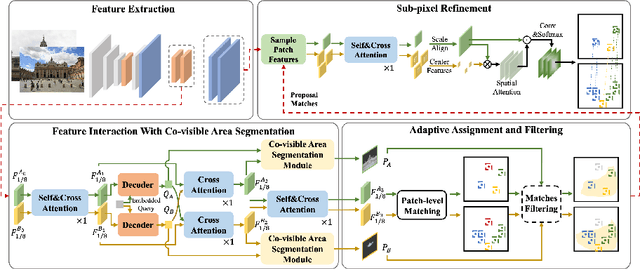
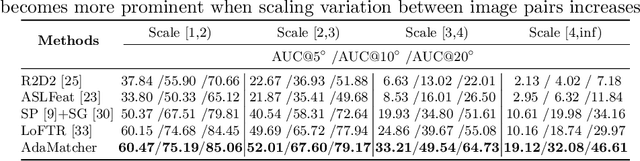
Local image feature matching, aiming to identify and correspond similar regions from image pairs, is an essential concept in computer vision. Most existing image matching approaches follow a one-to-one assignment principle and employ mutual nearest neighbor to guarantee unique correspondence between local features across images. However, images from different conditions may hold large-scale variations or viewpoint diversification so that one-to-one assignment may cause ambiguous or missing representations in dense matching. In this paper, we introduce AdaMatcher, a novel detector-free local feature matching method, which first correlates dense features by a lightweight feature interaction module and estimates co-visible area of the paired images, then performs a patch-level many-to-one assignment to predict match proposals, and finally refines them based on a one-to-one refinement module. Extensive experiments show that AdaMatcher outperforms solid baselines and achieves state-of-the-art results on many downstream tasks. Additionally, the many-to-one assignment and one-to-one refinement module can be used as a refinement network for other matching methods, such as SuperGlue, to boost their performance further. Code will be available upon publication.
SepLUT: Separable Image-adaptive Lookup Tables for Real-time Image Enhancement
Jul 18, 2022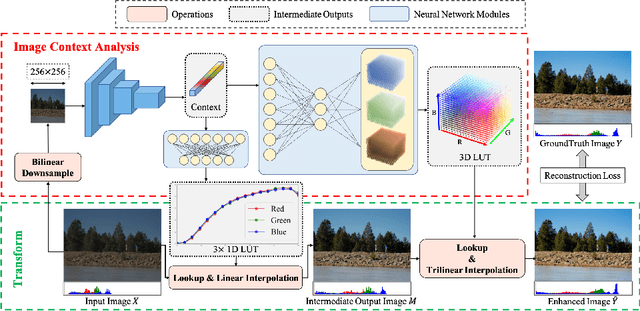
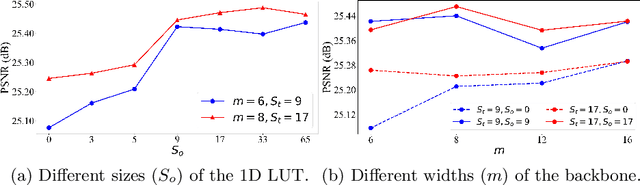
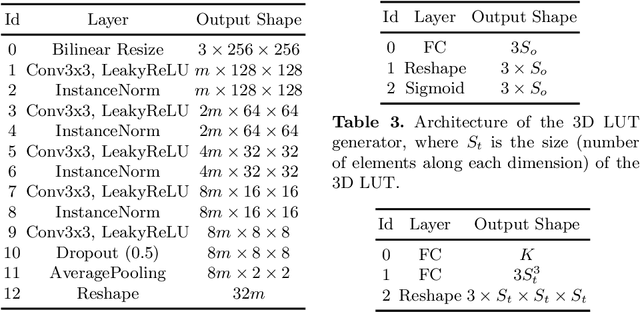
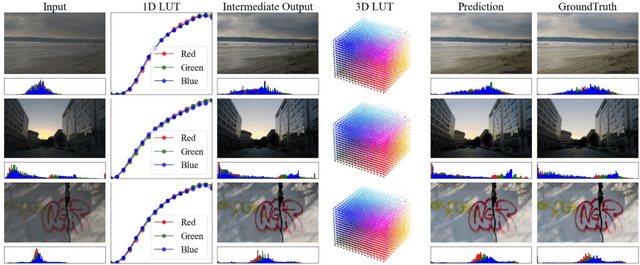
Image-adaptive lookup tables (LUTs) have achieved great success in real-time image enhancement tasks due to their high efficiency for modeling color transforms. However, they embed the complete transform, including the color component-independent and the component-correlated parts, into only a single type of LUTs, either 1D or 3D, in a coupled manner. This scheme raises a dilemma of improving model expressiveness or efficiency due to two factors. On the one hand, the 1D LUTs provide high computational efficiency but lack the critical capability of color components interaction. On the other, the 3D LUTs present enhanced component-correlated transform capability but suffer from heavy memory footprint, high training difficulty, and limited cell utilization. Inspired by the conventional divide-and-conquer practice in the image signal processor, we present SepLUT (separable image-adaptive lookup table) to tackle the above limitations. Specifically, we separate a single color transform into a cascade of component-independent and component-correlated sub-transforms instantiated as 1D and 3D LUTs, respectively. In this way, the capabilities of two sub-transforms can facilitate each other, where the 3D LUT complements the ability to mix up color components, and the 1D LUT redistributes the input colors to increase the cell utilization of the 3D LUT and thus enable the use of a more lightweight 3D LUT. Experiments demonstrate that the proposed method presents enhanced performance on photo retouching benchmark datasets than the current state-of-the-art and achieves real-time processing on both GPUs and CPUs.
Dynamic Low-Resolution Distillation for Cost-Efficient End-to-End Text Spotting
Jul 15, 2022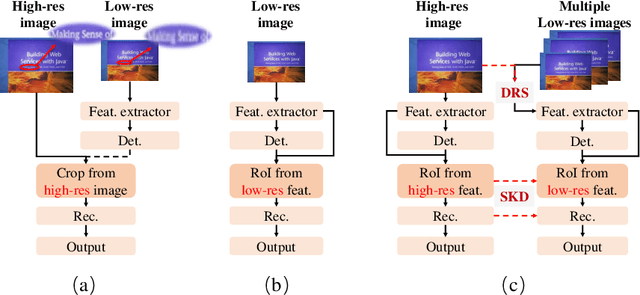
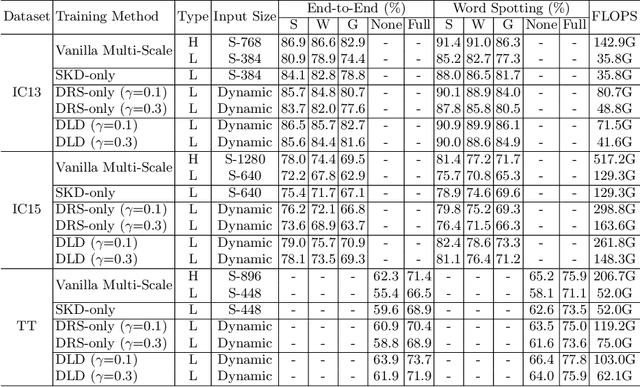
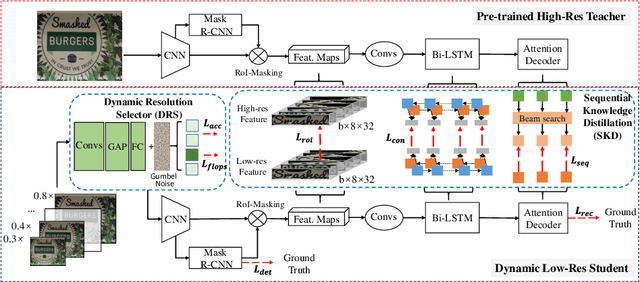
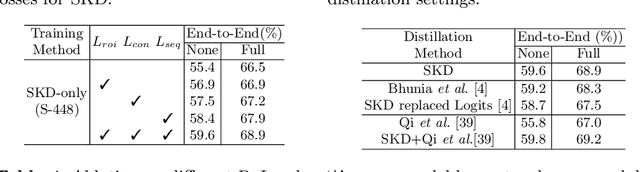
End-to-end text spotting has attached great attention recently due to its benefits on global optimization and high maintainability for real applications. However, the input scale has always been a tough trade-off since recognizing a small text instance usually requires enlarging the whole image, which brings high computational costs. In this paper, to address this problem, we propose a novel cost-efficient Dynamic Low-resolution Distillation (DLD) text spotting framework, which aims to infer images in different small but recognizable resolutions and achieve a better balance between accuracy and efficiency. Concretely, we adopt a resolution selector to dynamically decide the input resolutions for different images, which is constraint by both inference accuracy and computational cost. Another sequential knowledge distillation strategy is conducted on the text recognition branch, making the low-res input obtains comparable performance to a high-res image. The proposed method can be optimized end-to-end and adopted in any current text spotting framework to improve the practicability. Extensive experiments on several text spotting benchmarks show that the proposed method vastly improves the usability of low-res models. The code is available at https://github.com/hikopensource/DAVAR-Lab-OCR/.
DavarOCR: A Toolbox for OCR and Multi-Modal Document Understanding
Jul 14, 2022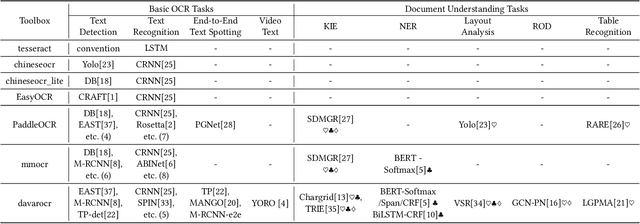


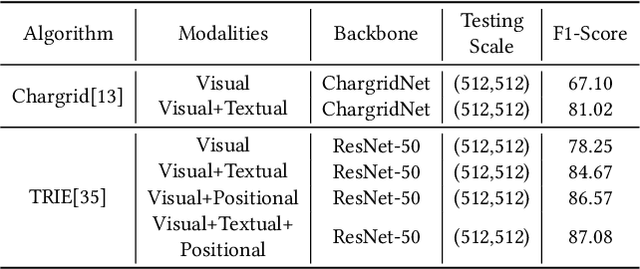
This paper presents DavarOCR, an open-source toolbox for OCR and document understanding tasks. DavarOCR currently implements 19 advanced algorithms, covering 9 different task forms. DavarOCR provides detailed usage instructions and the trained models for each algorithm. Compared with the previous opensource OCR toolbox, DavarOCR has relatively more complete support for the sub-tasks of the cutting-edge technology of document understanding. In order to promote the development and application of OCR technology in academia and industry, we pay more attention to the use of modules that different sub-domains of technology can share. DavarOCR is publicly released at https://github.com/hikopensource/Davar-Lab-OCR.
Snow Mask Guided Adaptive Residual Network for Image Snow Removal
Jul 11, 2022



Image restoration under severe weather is a challenging task. Most of the past works focused on removing rain and haze phenomena in images. However, snow is also an extremely common atmospheric phenomenon that will seriously affect the performance of high-level computer vision tasks, such as object detection and semantic segmentation. Recently, some methods have been proposed for snow removing, and most methods deal with snow images directly as the optimization object. However, the distribution of snow location and shape is complex. Therefore, failure to detect snowflakes / snow streak effectively will affect snow removing and limit the model performance. To solve these issues, we propose a Snow Mask Guided Adaptive Residual Network (SMGARN). Specifically, SMGARN consists of three parts, Mask-Net, Guidance-Fusion Network (GF-Net), and Reconstruct-Net. Firstly, we build a Mask-Net with Self-pixel Attention (SA) and Cross-pixel Attention (CA) to capture the features of snowflakes and accurately localized the location of the snow, thus predicting an accurate snow mask. Secondly, the predicted snow mask is sent into the specially designed GF-Net to adaptively guide the model to remove snow. Finally, an efficient Reconstruct-Net is used to remove the veiling effect and correct the image to reconstruct the final snow-free image. Extensive experiments show that our SMGARN numerically outperforms all existing snow removal methods, and the reconstructed images are clearer in visual contrast. All codes will be available.
WPPG Net: A Non-contact Video Based Heart Rate Extraction Network Framework with Compatible Training Capability
Jul 04, 2022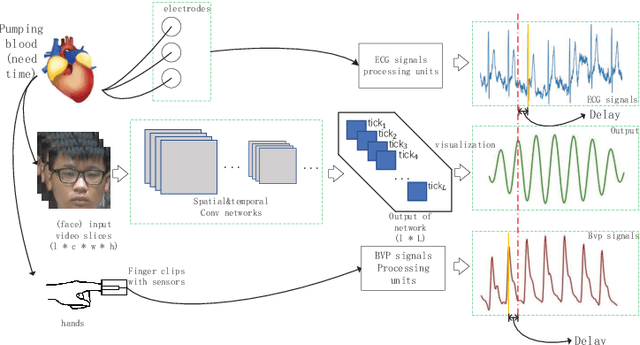
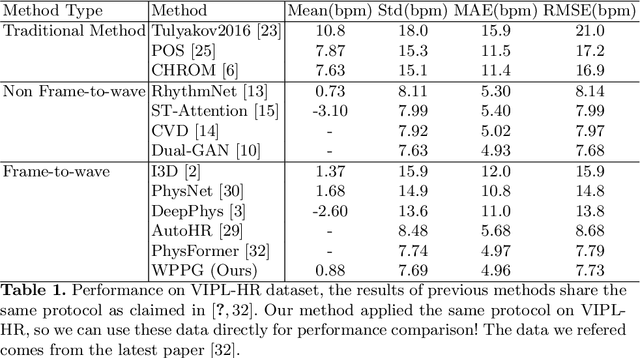
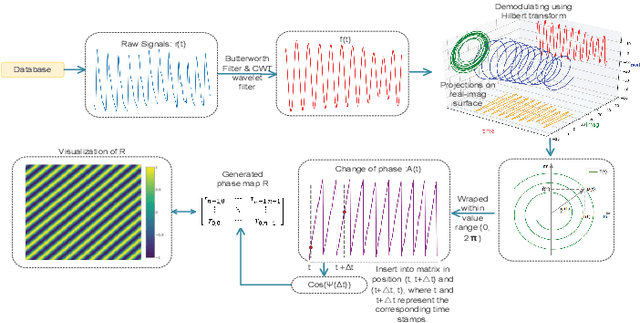
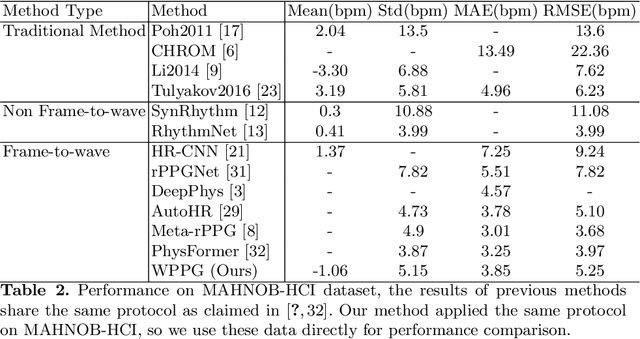
Our facial skin presents subtle color change known as remote Photoplethysmography (rPPG) signal, from which we could extract the heart rate of the subject. Recently many deep learning methods and related datasets on rPPG signal extraction are proposed. However, because of the time consumption blood flowing through our body and other factors, label waves such as BVP signals have uncertain delays with real rPPG signals in some datasets, which results in the difficulty on training of networks which output predicted rPPG waves directly. In this paper, by analyzing the common characteristics on rhythm and periodicity of rPPG signals and label waves, we propose a whole set of training methodology which wraps these networks so that they could remain efficient when be trained at the presence of frequent uncertain delay in datasets and gain more precise and robust heart rate prediction results than other delay-free rPPG extraction methods.
Perceptual Quality Assessment for Fine-Grained Compressed Images
Jun 08, 2022
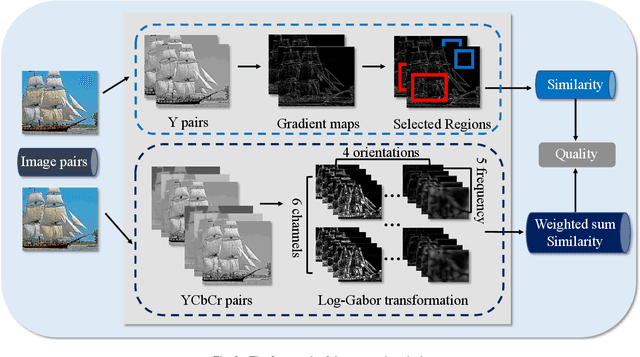

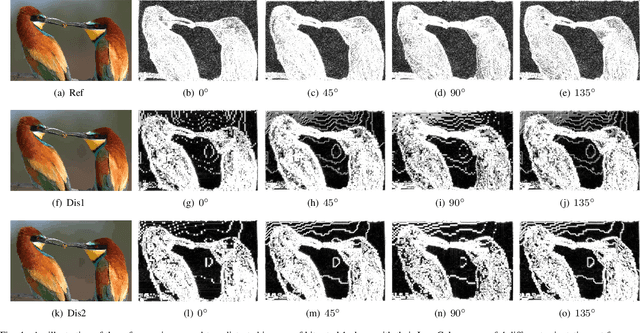
Recent years have witnessed the rapid development of image storage and transmission systems, in which image compression plays an important role. Generally speaking, image compression algorithms are developed to ensure good visual quality at limited bit rates. However, due to the different compression optimization methods, the compressed images may have different levels of quality, which needs to be evaluated quantificationally. Nowadays, the mainstream full-reference (FR) metrics are effective to predict the quality of compressed images at coarse-grained levels (the bit rates differences of compressed images are obvious), however, they may perform poorly for fine-grained compressed images whose bit rates differences are quite subtle. Therefore, to better improve the Quality of Experience (QoE) and provide useful guidance for compression algorithms, we propose a full-reference image quality assessment (FR-IQA) method for compressed images of fine-grained levels. Specifically, the reference images and compressed images are first converted to $YCbCr$ color space. The gradient features are extracted from regions that are sensitive to compression artifacts. Then we employ the Log-Gabor transformation to further analyze the texture difference. Finally, the obtained features are fused into a quality score. The proposed method is validated on the fine-grained compression image quality assessment (FGIQA) database, which is especially constructed for assessing the quality of compressed images with close bit rates. The experimental results show that our metric outperforms mainstream FR-IQA metrics on the FGIQA database. We also test our method on other commonly used compression IQA databases and the results show that our method obtains competitive performance on the coarse-grained compression IQA databases as well.
A Fine-grained Interpretability Evaluation Benchmark for Neural NLP
May 23, 2022
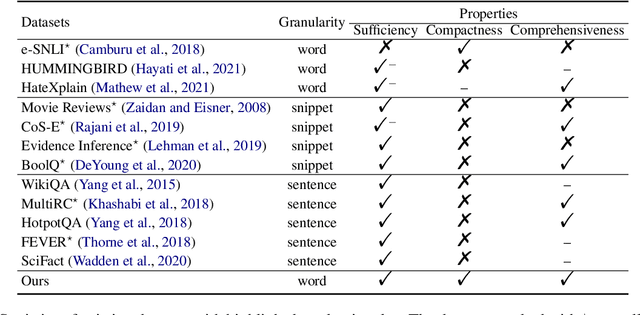
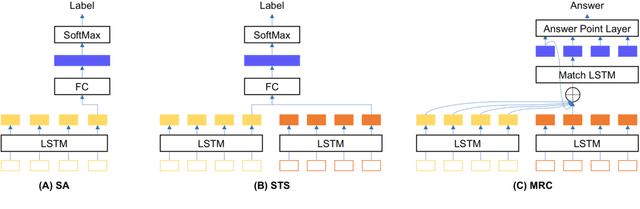
While there is increasing concern about the interpretability of neural models, the evaluation of interpretability remains an open problem, due to the lack of proper evaluation datasets and metrics. In this paper, we present a novel benchmark to evaluate the interpretability of both neural models and saliency methods. This benchmark covers three representative NLP tasks: sentiment analysis, textual similarity and reading comprehension, each provided with both English and Chinese annotated data. In order to precisely evaluate the interpretability, we provide token-level rationales that are carefully annotated to be sufficient, compact and comprehensive. We also design a new metric, i.e., the consistency between the rationales before and after perturbations, to uniformly evaluate the interpretability of models and saliency methods on different tasks. Based on this benchmark, we conduct experiments on three typical models with three saliency methods, and unveil their strengths and weakness in terms of interpretability. We will release this benchmark at \url{https://xyz} and hope it can facilitate the research in building trustworthy systems.
Spot-adaptive Knowledge Distillation
May 05, 2022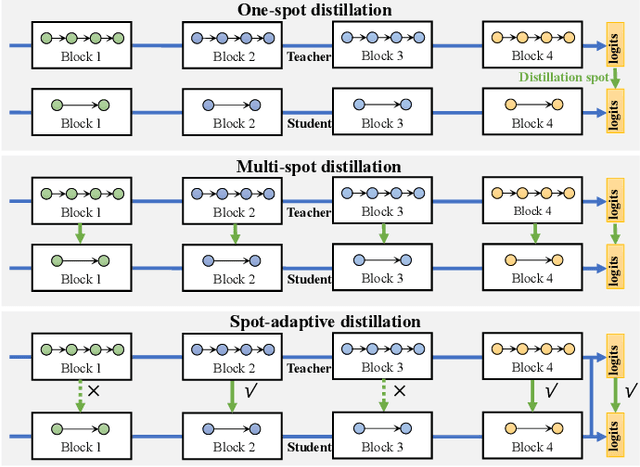
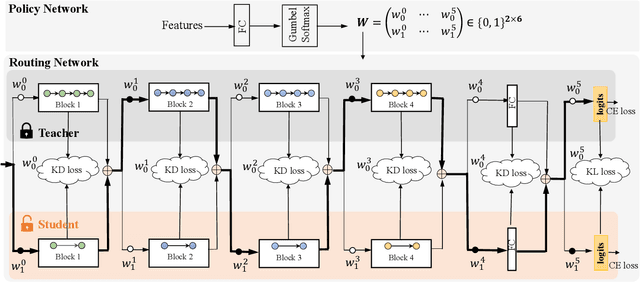
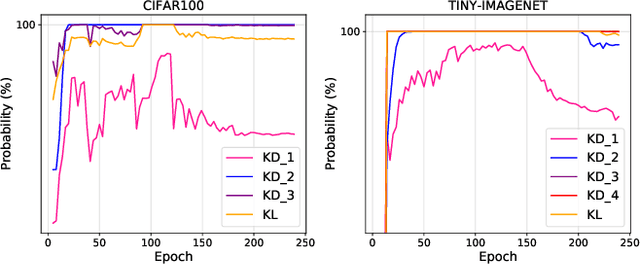
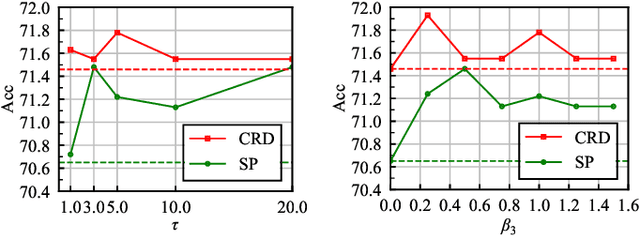
Knowledge distillation (KD) has become a well established paradigm for compressing deep neural networks. The typical way of conducting knowledge distillation is to train the student network under the supervision of the teacher network to harness the knowledge at one or multiple spots (i.e., layers) in the teacher network. The distillation spots, once specified, will not change for all the training samples, throughout the whole distillation process. In this work, we argue that distillation spots should be adaptive to training samples and distillation epochs. We thus propose a new distillation strategy, termed spot-adaptive KD (SAKD), to adaptively determine the distillation spots in the teacher network per sample, at every training iteration during the whole distillation period. As SAKD actually focuses on "where to distill" instead of "what to distill" that is widely investigated by most existing works, it can be seamlessly integrated into existing distillation methods to further improve their performance. Extensive experiments with 10 state-of-the-art distillers are conducted to demonstrate the effectiveness of SAKD for improving their distillation performance, under both homogeneous and heterogeneous distillation settings. Code is available at https://github.com/zju-vipa/spot-adaptive-pytorch
* 12 pages, 8 figures