 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBeyond Uniform Tokens: Adaptive Compression for Time Series Language Models
Jun 11, 2026Large language models (LLMs) have enabled time series (TS) analysis by jointly modeling numerical observations and textual context through a shared token interface. However, TS tokens and prompt tokens exhibit fundamentally different information structures, making uniform token processing inefficient. In this paper, we study token efficiency in TS language modeling from an asymmetric-token perspective. We show that TS tokens have highly uneven spectral contributions, where many tokens share redundant frequency patterns while a small subset preserves critical temporal evidence. We also observe that prompt-token influence attenuates with model depth, suggesting that full prompt retention across all layers is unnecessary. Based on these findings, we develop an adaptive token budgeting framework that compresses TS tokens via frequency-domain structure and progressively reduces prompt tokens across layers. Experiments across forecasting, classification, imputation, and anomaly detection demonstrate up to \textit{\textbf{7.68$\times$}} inference acceleration and performance gains in \textit{\textbf{78\%}} of evaluated settings, showing the effectiveness of asymmetric token compression for scalable TS foundation models.
FG$^2$-GDN: Enhancing Long-Context Gated Delta Networks with Doubly Fine-Grained Control
Apr 21, 2026Linear attention mechanisms have emerged as promising alternatives to softmax attention, offering linear-time complexity during inference. Recent advances such as Gated DeltaNet (GDN) and Kimi Delta Attention (KDA) have demonstrated that the delta rule, an online gradient descent update, enables superior associative recall compared to simple additive updates. While KDA refined the coarse head-wise decay gate into channel-wise decay, the learning rate $β_t$ in the delta update remains a scalar, limiting the model's capacity for dimension-specific adaptation. We introduce FG$^2$-GDN, which replaces the scalar $β_t$ with a channel-wise vector analogous to the transition from SGD to per-coordinate adaptive optimizers such as AdaGrad and Adam. We further propose FG$^2$-GDN+, which decouples the scaling for keys and values, enabling independent control of erasure strength and write strength. Experiments on synthetic and real-world benchmarks show that FG$^2$-GDN and its variant improve associative recall and long-context understanding over GDN and KDA, with comparable computational efficiency.
Multi-Modal Image Fusion via Intervention-Stable Feature Learning
Mar 24, 2026Multi-modal image fusion integrates complementary information from different modalities into a unified representation. Current methods predominantly optimize statistical correlations between modalities, often capturing dataset-induced spurious associations that degrade under distribution shifts. In this paper, we propose an intervention-based framework inspired by causal principles to identify robust cross-modal dependencies. Drawing insights from Pearl's causal hierarchy, we design three principled intervention strategies to probe different aspects of modal relationships: i) complementary masking with spatially disjoint perturbations tests whether modalities can genuinely compensate for each other's missing information, ii) random masking of identical regions identifies feature subsets that remain informative under partial observability, and iii) modality dropout evaluates the irreplaceable contribution of each modality. Based on these interventions, we introduce a Causal Feature Integrator (CFI) that learns to identify and prioritize intervention-stable features maintaining importance across different perturbation patterns through adaptive invariance gating, thereby capturing robust modal dependencies rather than spurious correlations. Extensive experiments demonstrate that our method achieves SOTA performance on both public benchmarks and downstream high-level vision tasks.
Sparse but Critical: A Token-Level Analysis of Distributional Shifts in RLVR Fine-Tuning of LLMs
Mar 23, 2026Reinforcement learning with verifiable rewards (RLVR) has significantly improved reasoning in large language models (LLMs), yet the token-level mechanisms underlying these improvements remain unclear. We present a systematic empirical study of RLVR's distributional effects organized around three main analyses: (1) token-level characterization of distributional shifts between base and RL models, (2) the impact of token-level distributional shifts on sequence-level reasoning performance through cross-sampling interventions, and (3) fine-grained mechanics of these shifts at the token level. We find that RL fine-tuning induces highly sparse and targeted changes, with only a small fraction of token distributions exhibiting meaningful divergence between the base and RL policies. We further characterize the structure and evolution of these shifts through analyses of token entropy, positional concentration, and reallocation of probability mass. To assess the functional importance of these sparse changes, we conduct cross-sampling experiments that selectively swap token choices between the base and RL models with varying intervention budgets. We show that inserting only a small fraction of RL-sampled tokens into base generations progressively recovers RL performance gains, while injecting a similarly small number of base token choices into otherwise RL-generated sequences collapses performance to base levels, isolating a small set of token-level decisions directly responsible for RLVR's performance gains. Finally, we explore divergence-weighted variants of the advantage signal as a diagnostic intervention, finding that they can yield improvements over baselines. Together, our results shed light on the distributional changes induced by RLVR and provide a fine-grained, token-level lens for understanding RLVR fine-tuning as a targeted refinement process.
On the Direction of RLVR Updates for LLM Reasoning: Identification and Exploitation
Mar 23, 2026Reinforcement learning with verifiable rewards (RLVR) has substantially improved the reasoning capabilities of large language models. While existing analyses identify that RLVR-induced changes are sparse, they primarily focus on the \textbf{magnitude} of these updates, largely overlooking their \textbf{direction}. In this work, we argue that the direction of updates is a more critical lens for understanding RLVR's effects, which can be captured by the signed, token-level log probability difference $Δ\log p$ between the base and final RLVR models. Through statistical analysis and token-replacement interventions, we demonstrate that $Δ\log p$ more effectively identifies sparse, yet reasoning-critical updates than magnitude-based metrics (\eg divergence or entropy). Building on this insight, we propose two practical applications: (1) a \textit{test-time extrapolation} method that amplifies the policy along the learned $Δ\log p$ direction to improve reasoning accuracy without further training; (2) a \textit{training-time reweighting} method that focuses learning on low-probability (corresponding to higher $Δ\log p$) tokens, which improves reasoning performance across models and benchmarks. Our work establishes the direction of change as a key principle for analyzing and improving RLVR.
CRAG: Can 3D Generative Models Help 3D Assembly?
Feb 26, 2026Most existing 3D assembly methods treat the problem as pure pose estimation, rearranging observed parts via rigid transformations. In contrast, human assembly naturally couples structural reasoning with holistic shape inference. Inspired by this intuition, we reformulate 3D assembly as a joint problem of assembly and generation. We show that these two processes are mutually reinforcing: assembly provides part-level structural priors for generation, while generation injects holistic shape context that resolves ambiguities in assembly. Unlike prior methods that cannot synthesize missing geometry, we propose CRAG, which simultaneously generates plausible complete shapes and predicts poses for input parts. Extensive experiments demonstrate state-of-the-art performance across in-the-wild objects with diverse geometries, varying part counts, and missing pieces. Our code and models will be released.
Accelerating LLM Pre-Training through Flat-Direction Dynamics Enhancement
Feb 26, 2026Pre-training Large Language Models requires immense computational resources, making optimizer efficiency essential. The optimization landscape is highly anisotropic, with loss reduction driven predominantly by progress along flat directions. While matrix-based optimizers such as Muon and SOAP leverage fine-grained curvature information to outperform AdamW, their updates tend toward isotropy -- relatively conservative along flat directions yet potentially aggressive along sharp ones. To address this limitation, we first establish a unified Riemannian Ordinary Differential Equation (ODE) framework that elucidates how common adaptive algorithms operate synergistically: the preconditioner induces a Riemannian geometry that mitigates ill-conditioning, while momentum serves as a Riemannian damping term that promotes convergence. Guided by these insights, we propose LITE, a generalized acceleration strategy that enhances training dynamics by applying larger Hessian damping coefficients and learning rates along flat trajectories. Extensive experiments demonstrate that LITE significantly accelerates both Muon and SOAP across diverse architectures (Dense, MoE), parameter scales (130M--1.3B), datasets (C4, Pile), and learning-rate schedules (cosine, warmup-stable-decay). Theoretical analysis confirms that LITE facilitates faster convergence along flat directions in anisotropic landscapes, providing a principled approach to efficient LLM pre-training. The code is available at https://github.com/SHUCHENZHU/LITE.
Advancing Block Diffusion Language Models for Test-Time Scaling
Feb 11, 2026Recent advances in block diffusion language models have demonstrated competitive performance and strong scalability on reasoning tasks. However, existing BDLMs have limited exploration under the test-time scaling setting and face more severe decoding challenges in long Chain-of-Thought reasoning, particularly in balancing the decoding speed and effectiveness. In this work, we propose a unified framework for test-time scaling in BDLMs that introduces adaptivity in both decoding and block-wise generation. At the decoding level, we propose Bounded Adaptive Confidence Decoding (BACD), a difficulty-aware sampling strategy that dynamically adjusts denoising based on model confidence, accelerating inference while controlling error accumulation. Beyond step-wise adaptivity, we introduce Think Coarse, Critic Fine (TCCF), a test-time scaling paradigm that allocates large block sizes to exploratory reasoning and smaller block sizes to refinement, achieving an effective efficiency-effectiveness balance. To enable efficient and effective decoding with a large block size, we adopt Progressive Block Size Extension, which mitigates performance degradation when scaling block sizes. Extensive experiments show that applying BACD and TCCF to TDAR-8B yields significant improvements over strong baselines such as TraDo-8B (2.26x speedup, +11.2 points on AIME24). These results mark an important step toward unlocking the potential of BDLMs for test-time scaling in complex reasoning tasks.
SpecAware: A Spectral-Content Aware Foundation Model for Unifying Multi-Sensor Learning in Hyperspectral Remote Sensing Mapping
Oct 31, 2025



Hyperspectral imaging (HSI) is a vital tool for fine-grained land-use and land-cover (LULC) mapping. However, the inherent heterogeneity of HSI data has long posed a major barrier to developing generalized models via joint training. Although HSI foundation models have shown promise for different downstream tasks, the existing approaches typically overlook the critical guiding role of sensor meta-attributes, and struggle with multi-sensor training, limiting their transferability. To address these challenges, we propose SpecAware, which is a novel hyperspectral spectral-content aware foundation model for unifying multi-sensor learning for HSI mapping. We also constructed the Hyper-400K dataset to facilitate this research, which is a new large-scale, high-quality benchmark dataset with over 400k image patches from diverse airborne AVIRIS sensors. The core of SpecAware is a two-step hypernetwork-driven encoding process for HSI data. Firstly, we designed a meta-content aware module to generate a unique conditional input for each HSI patch, tailored to each spectral band of every sample by fusing the sensor meta-attributes and its own image content. Secondly, we designed the HyperEmbedding module, where a sample-conditioned hypernetwork dynamically generates a pair of matrix factors for channel-wise encoding, consisting of adaptive spatial pattern extraction and latent semantic feature re-projection. Thus, SpecAware gains the ability to perceive and interpret spatial-spectral features across diverse scenes and sensors. This, in turn, allows SpecAware to adaptively process a variable number of spectral channels, establishing a unified framework for joint pre-training. Extensive experiments on six datasets demonstrate that SpecAware can learn superior feature representations, excelling in land-cover semantic segmentation classification, change detection, and scene classification.
Dual-Arm Hierarchical Planning for Laboratory Automation: Vibratory Sieve Shaker Operations
Sep 18, 2025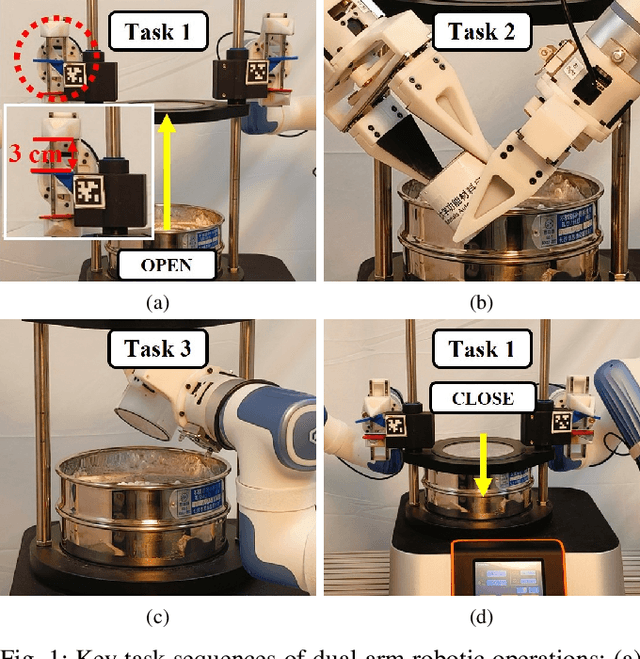
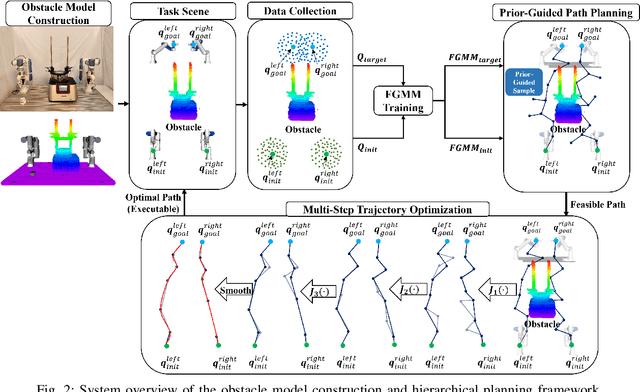
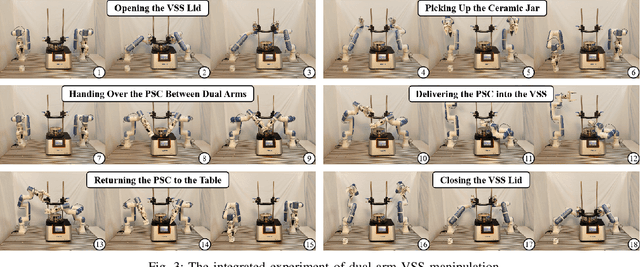
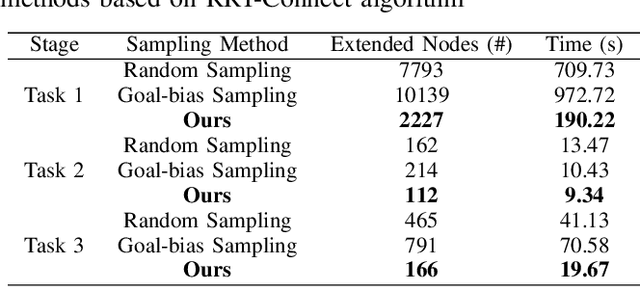
This paper addresses the challenges of automating vibratory sieve shaker operations in a materials laboratory, focusing on three critical tasks: 1) dual-arm lid manipulation in 3 cm clearance spaces, 2) bimanual handover in overlapping workspaces, and 3) obstructed powder sample container delivery with orientation constraints. These tasks present significant challenges, including inefficient sampling in narrow passages, the need for smooth trajectories to prevent spillage, and suboptimal paths generated by conventional methods. To overcome these challenges, we propose a hierarchical planning framework combining Prior-Guided Path Planning and Multi-Step Trajectory Optimization. The former uses a finite Gaussian mixture model to improve sampling efficiency in narrow passages, while the latter refines paths by shortening, simplifying, imposing joint constraints, and B-spline smoothing. Experimental results demonstrate the framework's effectiveness: planning time is reduced by up to 80.4%, and waypoints are decreased by 89.4%. Furthermore, the system completes the full vibratory sieve shaker operation workflow in a physical experiment, validating its practical applicability for complex laboratory automation.