 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEccentricity Confound in EEG-based Visual Attention Decoding from Gaze-Fixated Neural Tracking of Motion in Natural Videos
Apr 16, 2026Objective. Decoding visual attention from brain signals during naturalistic video viewing has emerged as a new direction in brain-computer interface research. Current methods assume that stronger coupling between object motion and neural activity indicates higher attention, but this can be confounded by eye movement artifacts and stimulus properties. This study investigates how visual eccentricity (the distance between a visual object and the fixation point) affects neural responses when eye movement artifacts are controlled. Approach. EEG signals were recorded across three tasks that manipulated object eccentricity and attention conditions while participants maintained gaze fixation. Correlation analysis and match-mismatch decoding were performed to quantify the neural tracking of object motion. Main results. The analysis supports three conclusions: (1) neural tracking of object motion in natural videos works under gaze fixation; (2) the strength of neural tracking under gaze fixation is predictive of attention; and (3) there exists a significant eccentricity confound in the EEG responses, with poorer neural tracking of motion at larger eccentricities. Significance. These results provide critical evidence that findings from previous free-viewing studies reflect genuine neural processing rather than mere oculomotor artifacts. However, the identified eccentricity effect highlights a major limitation for current decoding approaches that assume coupling strength reflects attention levels alone.
Sample-level EEG-based Selective Auditory Attention Decoding with Markov Switching Models
Feb 13, 2026Selective auditory attention decoding aims to identify the speaker of interest from listeners' neural signals, such as electroencephalography (EEG), in the presence of multiple concurrent speakers. Most existing methods operate at the window level, facing a trade-off between temporal resolution and decoding accuracy. Recent work has shown that hidden Markov model (HMM)-based post-processing can smooth window-level decoder outputs to improve this trade-off. Instead of using a separate smoothing step, we propose to integrate the decoding and smoothing components into a single probabilistic framework using a Markov switching model (MSM). It directly models the relationship between the EEG and speech envelopes under each attention state while incorporating the temporal dynamics of attention. This formulation enables sample-level attention decoding, with model parameters and attention states jointly estimated via the expectation-maximization algorithm. Experimental results demonstrate that this integrated MSM formulation achieves comparable decoding accuracy to HMM post-processing while providing faster attention switch detection. The code for the proposed method is available at https://github.com/YYao-42/MSM.
Moon: A Modality Conversion-based Efficient Multivariate Time Series Anomaly Detection
Oct 02, 2025Multivariate time series (MTS) anomaly detection identifies abnormal patterns where each timestamp contains multiple variables. Existing MTS anomaly detection methods fall into three categories: reconstruction-based, prediction-based, and classifier-based methods. However, these methods face two key challenges: (1) Unsupervised learning methods, such as reconstruction-based and prediction-based methods, rely on error thresholds, which can lead to inaccuracies; (2) Semi-supervised methods mainly model normal data and often underuse anomaly labels, limiting detection of subtle anomalies;(3) Supervised learning methods, such as classifier-based approaches, often fail to capture local relationships, incur high computational costs, and are constrained by the scarcity of labeled data. To address these limitations, we propose Moon, a supervised modality conversion-based multivariate time series anomaly detection framework. Moon enhances the efficiency and accuracy of anomaly detection while providing detailed anomaly analysis reports. First, Moon introduces a novel multivariate Markov Transition Field (MV-MTF) technique to convert numeric time series data into image representations, capturing relationships across variables and timestamps. Since numeric data retains unique patterns that cannot be fully captured by image conversion alone, Moon employs a Multimodal-CNN to integrate numeric and image data through a feature fusion model with parameter sharing, enhancing training efficiency. Finally, a SHAP-based anomaly explainer identifies key variables contributing to anomalies, improving interpretability. Extensive experiments on six real-world MTS datasets demonstrate that Moon outperforms six state-of-the-art methods by up to 93% in efficiency, 4% in accuracy and, 10.8% in interpretation performance.
Efficient Solutions for Mitigating Initialization Bias in Unsupervised Self-Adaptive Auditory Attention Decoding
Sep 18, 2025Decoding the attended speaker in a multi-speaker environment from electroencephalography (EEG) has attracted growing interest in recent years, with neuro-steered hearing devices as a driver application. Current approaches typically rely on ground-truth labels of the attended speaker during training, necessitating calibration sessions for each user and each EEG set-up to achieve optimal performance. While unsupervised self-adaptive auditory attention decoding (AAD) for stimulus reconstruction has been developed to eliminate the need for labeled data, it suffers from an initialization bias that can compromise performance. Although an unbiased variant has been proposed to address this limitation, it introduces substantial computational complexity that scales with data size. This paper presents three computationally efficient alternatives that achieve comparable performance, but with a significantly lower and constant computational cost. The code for the proposed algorithms is available at https://github.com/YYao-42/Unsupervised_AAD.
PeerGPT: Probing the Roles of LLM-based Peer Agents as Team Moderators and Participants in Children's Collaborative Learning
Mar 21, 2024In children's collaborative learning, effective peer conversations can significantly enhance the quality of children's collaborative interactions. The integration of Large Language Model (LLM) agents into this setting explores their novel role as peers, assessing impacts as team moderators and participants. We invited two groups of participants to engage in a collaborative learning workshop, where they discussed and proposed conceptual solutions to a design problem. The peer conversation transcripts were analyzed using thematic analysis. We discovered that peer agents, while managing discussions effectively as team moderators, sometimes have their instructions disregarded. As participants, they foster children's creative thinking but may not consistently provide timely feedback. These findings highlight potential design improvements and considerations for peer agents in both roles.
Stimulus-Informed Generalized Canonical Correlation Analysis for Group Analysis of Neural Responses
Jan 31, 2024



Various new brain-computer interface technologies or neuroscience applications require decoding stimulus-following neural responses to natural stimuli such as speech and video from, e.g., electroencephalography (EEG) signals. In this context, generalized canonical correlation analysis (GCCA) is often used as a group analysis technique, which allows the extraction of correlated signal components from the neural activity of multiple subjects attending to the same stimulus. GCCA can be used to improve the signal-to-noise ratio of the stimulus-following neural responses relative to all other irrelevant (non-)neural activity, or to quantify the correlated neural activity across multiple subjects in a group-wise coherence metric. However, the traditional GCCA technique is stimulus-unaware: no information about the stimulus is used to estimate the correlated components from the neural data of several subjects. Therefore, the GCCA technique might fail to extract relevant correlated signal components in practical situations where the amount of information is limited, for example, because of a limited amount of training data or group size. This motivates a new stimulus-informed GCCA (SI-GCCA) framework that allows taking the stimulus into account to extract the correlated components. We show that SI-GCCA outperforms GCCA in various practical settings, for both auditory and visual stimuli. Moreover, we showcase how SI-GCCA can be used to steer the estimation of the components towards the stimulus. As such, SI-GCCA substantially improves upon GCCA for various purposes, ranging from preprocessing to quantifying attention.
Performance Analysis of Reconfigurable Intelligent Surface Assisted Two-Way NOMA Networks
Sep 18, 2022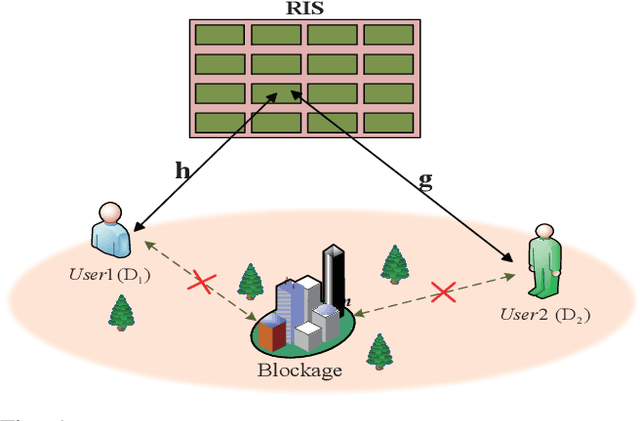
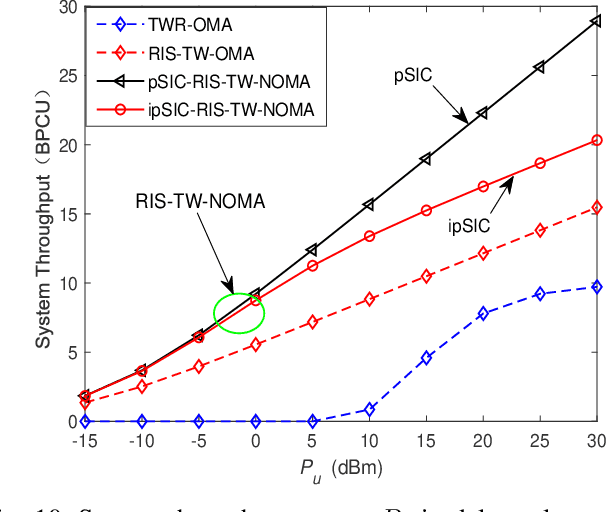
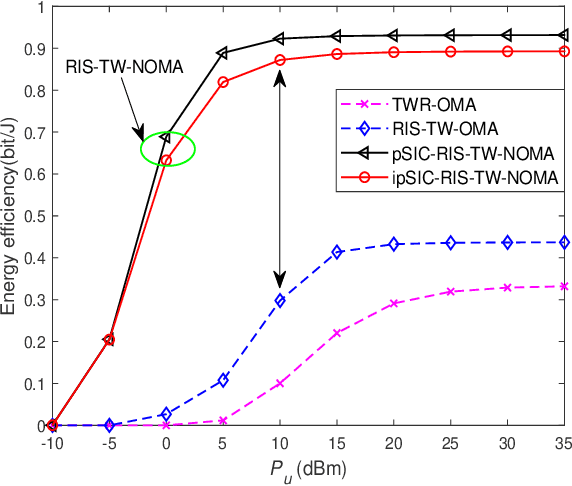
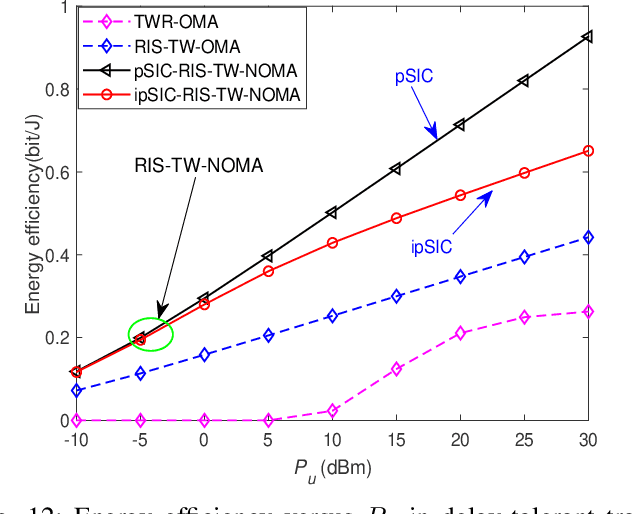
This paper investigates the performance of reconfigurable intelligent surface assisted two-way non-orthogonal multiple access (RIS-TW-NOMA) networks, where a pair of users exchange their information through a RIS. The influence of imperfect successive interference cancellation on RIS-TW-NOMA is taken into account. To evaluate the potential performance of RIS-TW-NOMA, we derive the exact and asymptotic expressions of outage probability and ergodic rate for a pair of users. Based on the analytical results, the diversity orders and high signal-to-noise ratio (SNR) slopes are obtained in the high SNR regime, which are closely related to the number of RIS elements. Additionally, we analyze the system throughput and energy efficiency of RIS-TW-NOMA networks in both delay-limited and delay-tolerant transmission modes. Numerical results indicate that: 1) The outage behaviors and ergodic rate of RIS-TW-NOMA are superior to that of RIS-TW-OMA and two-way relay OMA (TWR-OMA); 2) As the number of RIS elements increases, the RIS-TW-NOMA networks are capable of achieving the enhanced outage performance; and 3) By comparing with RIS-TW-OMA and TWR-OMA networks, the energy efficiency and system throughput of RIS-TW-NOMA has obvious advantages.
Multi-center Assessment of CNN-Transformer with Belief Matching Loss for Patient-independent Seizure Detection in Scalp and Intracranial EEG
Aug 09, 2022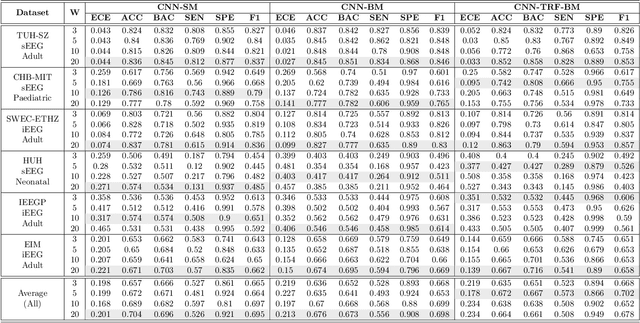
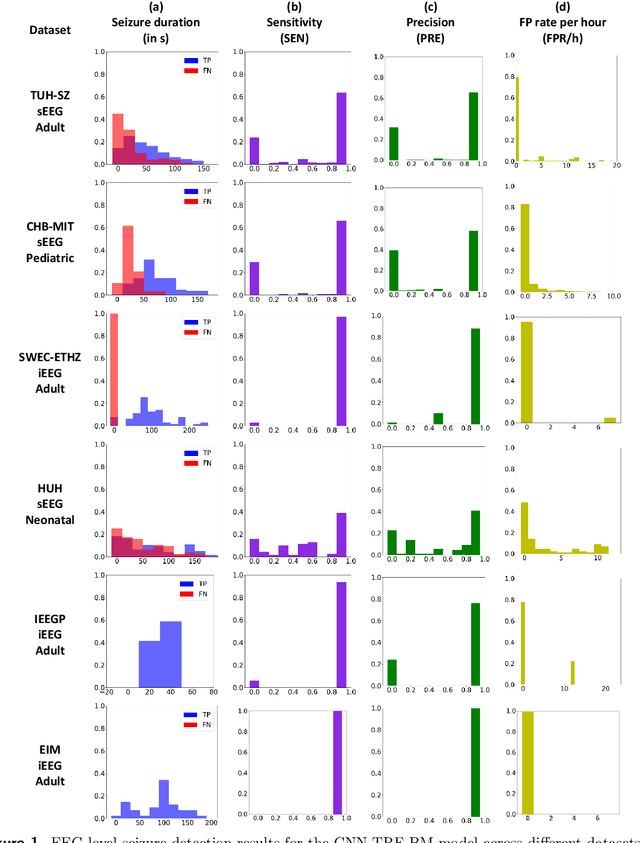
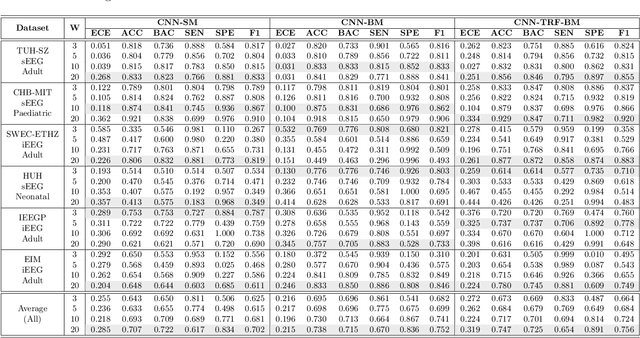
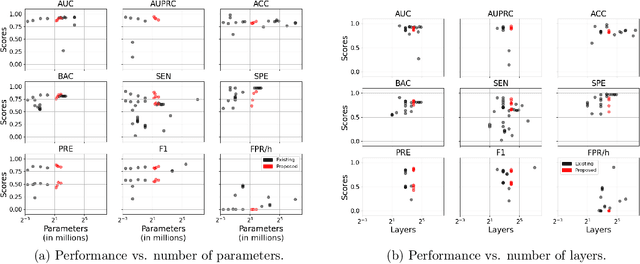
Neurologists typically identify epileptic seizures from electroencephalograms (EEGs) by visual inspection. This process is often time-consuming. To expedite the process, a reliable, automated, and patient-independent seizure detector is essential. However, developing such detector is challenging as seizures exhibit diverse morphologies across patients. In this study, we propose a patient-independent seizure detector to automatically detect seizures in both scalp EEG (sEEG) and intracranial EEG (iEEG). First, we deploy a convolutional neural network (CNN) with transformers and belief matching loss to detect seizures in single-channel EEG segments. Next, we utilized the channel-level outputs to detect seizures in multi-channel EEG segments. At last, we apply postprocessing filters to the segment-level outputs to determine the start and end points of seizures in multi-channel EEGs. We introduce the minimum overlap evaluation scoring (MOES) as an evaluation metric, improving upon existing metrics. We trained the seizure detector on the Temple University Hospital Seizure (TUH-SZ) sEEG dataset and evaluated it on five other independent sEEG and iEEG datasets. On the TUH-SZ dataset, the proposed patient-independent seizure detector achieves a sensitivity (SEN), precision (PRE), average and median false positive rate per hour (aFPR/h and mFPR/h), and median offset of 0.772, 0.429, 4.425, 0, and -2.125s, respectively. Across four adult datasets, we obtained SEN of 0.617-1.00, PRE of 0.534-1.00, aFPR/h of 0.425-2.002, and mFPR/h of 0-1.003. Meanwhile, on neonatal and paediatric datasets, we obtained SEN of 0.227-0.678, PRE of 0.377-0.818, aFPR/h of 0.253-0.421, and mFPR/h of 0.118-0.223. The proposed seizure detector takes less than 15s for a 30 minutes EEG, hence, it could potentially aid the clinicians in identifying seizures expeditiously, allocating more time for devising proper treatment.
Transformer Convolutional Neural Networks for Automated Artifact Detection in Scalp EEG
Aug 04, 2022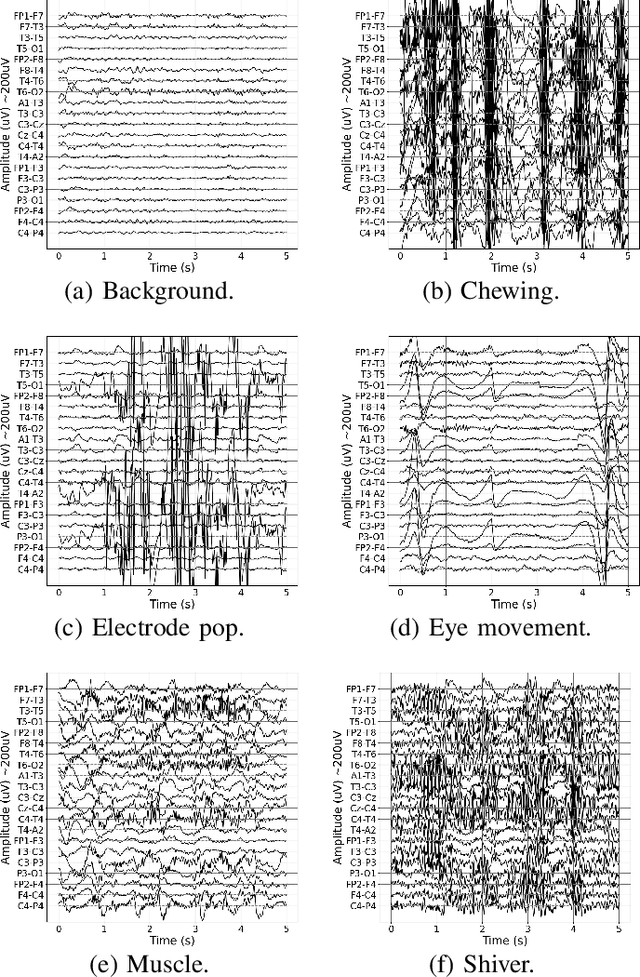
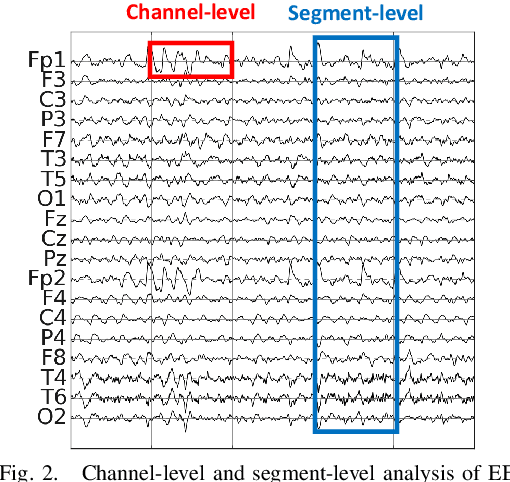
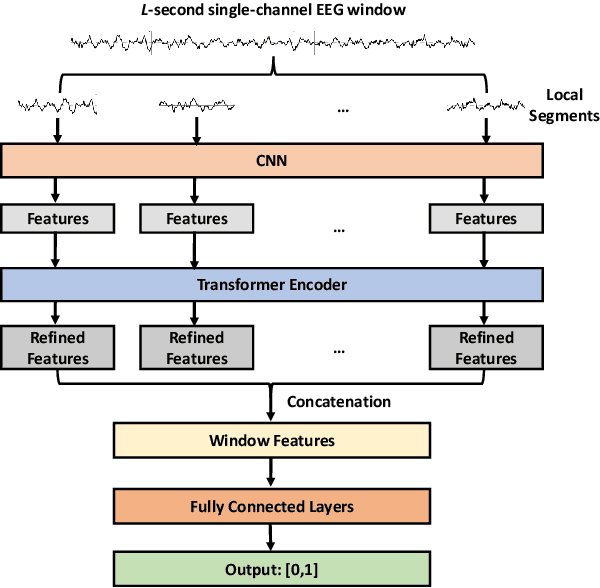
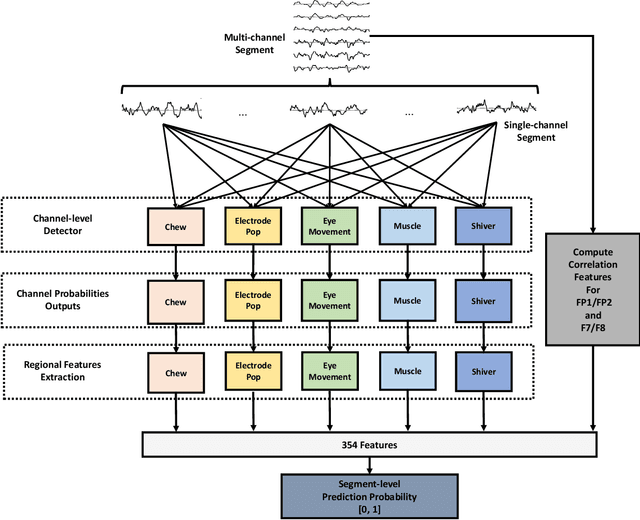
It is well known that electroencephalograms (EEGs) often contain artifacts due to muscle activity, eye blinks, and various other causes. Detecting such artifacts is an essential first step toward a correct interpretation of EEGs. Although much effort has been devoted to semi-automated and automated artifact detection in EEG, the problem of artifact detection remains challenging. In this paper, we propose a convolutional neural network (CNN) enhanced by transformers using belief matching (BM) loss for automated detection of five types of artifacts: chewing, electrode pop, eye movement, muscle, and shiver. Specifically, we apply these five detectors at individual EEG channels to distinguish artifacts from background EEG. Next, for each of these five types of artifacts, we combine the output of these channel-wise detectors to detect artifacts in multi-channel EEG segments. These segment-level classifiers can detect specific artifacts with a balanced accuracy (BAC) of 0.947, 0.735, 0.826, 0.857, and 0.655 for chewing, electrode pop, eye movement, muscle, and shiver artifacts, respectively. Finally, we combine the outputs of the five segment-level detectors to perform a combined binary classification (any artifact vs. background). The resulting detector achieves a sensitivity (SEN) of 60.4%, 51.8%, and 35.5%, at a specificity (SPE) of 95%, 97%, and 99%, respectively. This artifact detection module can reject artifact segments while only removing a small fraction of the background EEG, leading to a cleaner EEG for further analysis.
Exemplar Loss for Siamese Network in Visual Tracking
Jun 20, 2020
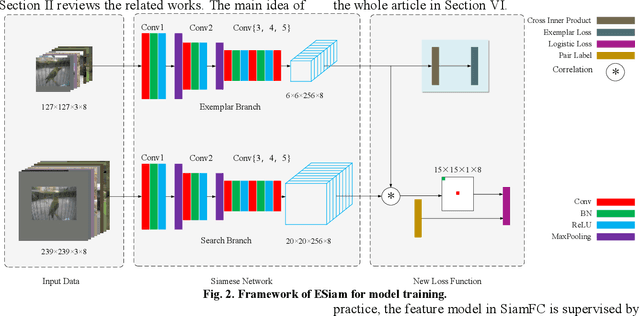
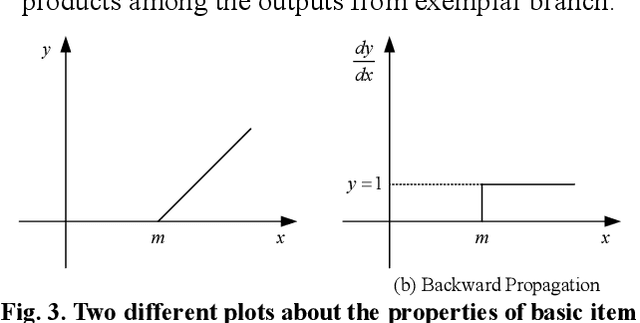
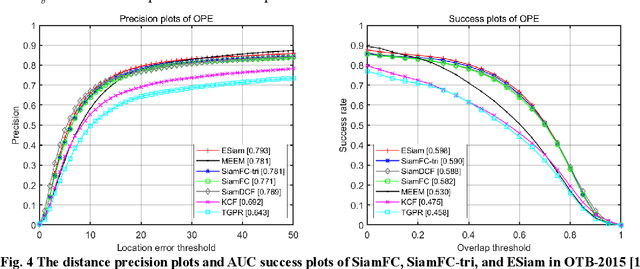
Visual tracking plays an important role in perception system, which is a crucial part of intelligent transportation. Recently, Siamese network is a hot topic for visual tracking to estimate moving targets' trajectory, due to its superior accuracy and simple framework. In general, Siamese tracking algorithms, supervised by logistic loss and triplet loss, increase the value of inner product between exemplar template and positive sample while reduce the value of inner product with background sample. However, the distractors from different exemplars are not considered by mentioned loss functions, which limit the feature models' discrimination. In this paper, a new exemplar loss integrated with logistic loss is proposed to enhance the feature model's discrimination by reducing inner products among exemplars. Without the bells and whistles, the proposed algorithm outperforms the methods supervised by logistic loss or triplet loss. Numerical results suggest that the newly developed algorithm achieves comparable performance in public benchmarks.