 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning 6-DoF Fine-grained Grasp Detection Based on Part Affordance Grounding
Jan 27, 2023Robotic grasping is a fundamental ability for a robot to interact with the environment. Current methods focus on how to obtain a stable and reliable grasping pose in object wise, while little work has been studied on part (shape)-wise grasping which is related to fine-grained grasping and robotic affordance. Parts can be seen as atomic elements to compose an object, which contains rich semantic knowledge and a strong correlation with affordance. However, lacking a large part-wise 3D robotic dataset limits the development of part representation learning and downstream application. In this paper, we propose a new large Language-guided SHape grAsPing datasEt (named Lang-SHAPE) to learn 3D part-wise affordance and grasping ability. We design a novel two-stage fine-grained robotic grasping network (named PIONEER), including a novel 3D part language grounding model, and a part-aware grasp pose detection model. To evaluate the effectiveness, we perform multi-level difficulty part language grounding grasping experiments and deploy our proposed model on a real robot. Results show our method achieves satisfactory performance and efficiency in reference identification, affordance inference, and 3D part-aware grasping. Our dataset and code are available on our project website https://sites.google.com/view/lang-shape
XNLI: Explaining and Diagnosing NLI-based Visual Data Analysis
Jan 25, 2023



Natural language interfaces (NLIs) enable users to flexibly specify analytical intentions in data visualization. However, diagnosing the visualization results without understanding the underlying generation process is challenging. Our research explores how to provide explanations for NLIs to help users locate the problems and further revise the queries. We present XNLI, an explainable NLI system for visual data analysis. The system introduces a Provenance Generator to reveal the detailed process of visual transformations, a suite of interactive widgets to support error adjustments, and a Hint Generator to provide query revision hints based on the analysis of user queries and interactions. Two usage scenarios of XNLI and a user study verify the effectiveness and usability of the system. Results suggest that XNLI can significantly enhance task accuracy without interrupting the NLI-based analysis process.
Dance2MIDI: Dance-driven multi-instruments music generation
Jan 22, 2023Dance-driven music generation aims to generate musical pieces conditioned on dance videos. Previous works focus on monophonic or raw audio generation, while the multiinstruments scenario is under-explored. The challenges of the dance-driven multi-instruments music (MIDI) generation are two-fold: 1) no publicly available multi-instruments MIDI and video paired dataset and 2) the weak correlation between music and video. To tackle these challenges, we build the first multi-instruments MIDI and dance paired dataset (D2MIDI). Based on our proposed dataset, we introduce a multi-instruments MIDI generation framework (Dance2MIDI) conditioned on dance video. Specifically, 1) to model the correlation between music and dance, we encode the dance motion using the GCN, and 2) to generate harmonious and coherent music, we employ Transformer to decode the MIDI sequence. We evaluate the generated music of our framework trained on D2MIDI dataset and demonstrate that our method outperforms existing methods. The data and code are available on https://github.com/Dance2MIDI/Dance2MIDI
Toward Global Sensing Quality Maximization: A Configuration Optimization Scheme for Camera Networks
Nov 28, 2022The performance of a camera network monitoring a set of targets depends crucially on the configuration of the cameras. In this paper, we investigate the reconfiguration strategy for the parameterized camera network model, with which the sensing qualities of the multiple targets can be optimized globally and simultaneously. We first propose to use the number of pixels occupied by a unit-length object in image as a metric of the sensing quality of the object, which is determined by the parameters of the camera, such as intrinsic, extrinsic, and distortional coefficients. Then, we form a single quantity that measures the sensing quality of the targets by the camera network. This quantity further serves as the objective function of our optimization problem to obtain the optimal camera configuration. We verify the effectiveness of our approach through extensive simulations and experiments, and the results reveal its improved performance on the AprilTag detection tasks. Codes and related utilities for this work are open-sourced and available at https://github.com/sszxc/MultiCam-Simulation.
Diffusion Denoising Process for Perceptron Bias in Out-of-distribution Detection
Nov 21, 2022



Out-of-distribution (OOD) detection is an important task to ensure the reliability and safety of deep learning and the discriminator models outperform others for now. However, the feature extraction of the discriminator models must compress the data and lose certain information, leaving room for bad cases and malicious attacks. In this paper, we provide a new assumption that the discriminator models are more sensitive to some subareas of the input space and such perceptron bias causes bad cases and overconfidence areas. Under this assumption, we design new detection methods and indicator scores. For detection methods, we introduce diffusion models (DMs) into OOD detection. We find that the diffusion denoising process (DDP) of DMs also functions as a novel form of asymmetric interpolation, which is suitable to enhance the input and reduce the overconfidence areas. For indicator scores, we find that the features of the discriminator models of OOD inputs occur sharp changes under DDP and use the norm of this dynamic change as our indicator scores. Therefore, we develop a new framework to combine the discriminator and generation models to do OOD detection under our new assumption. The discriminator models provide proper detection spaces and the generation models reduce the overconfidence problem. According to our experiments on CIFAR10 and CIFAR100, our methods get competitive results with state-of-the-art methods. Our implementation is available at https://github.com/luping-liu/DiffOOD.
VarietySound: Timbre-Controllable Video to Sound Generation via Unsupervised Information Disentanglement
Nov 19, 2022Video to sound generation aims to generate realistic and natural sound given a video input. However, previous video-to-sound generation methods can only generate a random or average timbre without any controls or specializations of the generated sound timbre, leading to the problem that people cannot obtain the desired timbre under these methods sometimes. In this paper, we pose the task of generating sound with a specific timbre given a video input and a reference audio sample. To solve this task, we disentangle each target sound audio into three components: temporal information, acoustic information, and background information. We first use three encoders to encode these components respectively: 1) a temporal encoder to encode temporal information, which is fed with video frames since the input video shares the same temporal information as the original audio; 2) an acoustic encoder to encode timbre information, which takes the original audio as input and discards its temporal information by a temporal-corrupting operation; and 3) a background encoder to encode the residual or background sound, which uses the background part of the original audio as input. To make the generated result achieve better quality and temporal alignment, we also adopt a mel discriminator and a temporal discriminator for the adversarial training. Our experimental results on the VAS dataset demonstrate that our method can generate high-quality audio samples with good synchronization with events in video and high timbre similarity with the reference audio.
Safety-Critical Optimal Control for Robotic Manipulators in A Cluttered Environment
Nov 11, 2022Designing safety-critical control for robotic manipulators is challenging, especially in a cluttered environment. First, the actual trajectory of a manipulator might deviate from the planned one due to the complex collision environments and non-trivial dynamics, leading to collision; Second, the feasible space for the manipulator is hard to obtain since the explicit distance functions between collision meshes are unknown. By analyzing the relationship between the safe set and the controlled invariant set, this paper proposes a data-driven control barrier function (CBF) construction method, which extracts CBF from distance samples. Specifically, the CBF guarantees the controlled invariant property for considering the system dynamics. The data-driven method samples the distance function and determines the safe set. Then, the CBF is synthesized based on the safe set by a scenario-based sum of square (SOS) program. Unlike most existing linearization based approaches, our method reserves the volume of the feasible space for planning without approximation, which helps find a solution in a cluttered environment. The control law is obtained by solving a CBF-based quadratic program in real time, which works as a safe filter for the desired planning-based controller. Moreover, our method guarantees safety with the proven probabilistic result. Our method is validated on a 7-DOF manipulator in both real and virtual cluttered environments. The experiments show that the manipulator is able to execute tasks where the clearance between obstacles is in millimeters.
SDMuse: Stochastic Differential Music Editing and Generation via Hybrid Representation
Nov 02, 2022While deep generative models have empowered music generation, it remains a challenging and under-explored problem to edit an existing musical piece at fine granularity. In this paper, we propose SDMuse, a unified Stochastic Differential Music editing and generation framework, which can not only compose a whole musical piece from scratch, but also modify existing musical pieces in many ways, such as combination, continuation, inpainting, and style transferring. The proposed SDMuse follows a two-stage pipeline to achieve music generation and editing on top of a hybrid representation including pianoroll and MIDI-event. In particular, SDMuse first generates/edits pianoroll by iteratively denoising through a stochastic differential equation (SDE) based on a diffusion model generative prior, and then refines the generated pianoroll and predicts MIDI-event tokens auto-regressively. We evaluate the generated music of our method on ailabs1k7 pop music dataset in terms of quality and controllability on various music editing and generation tasks. Experimental results demonstrate the effectiveness of our proposed stochastic differential music editing and generation process, as well as the hybrid representations.
DA$^2$ Dataset: Toward Dexterity-Aware Dual-Arm Grasping
Jul 31, 2022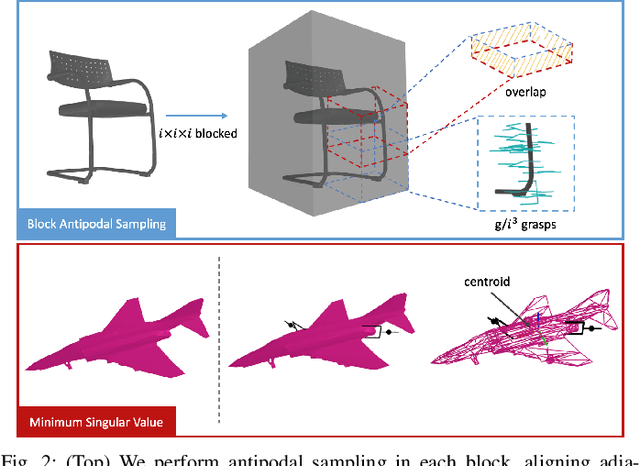
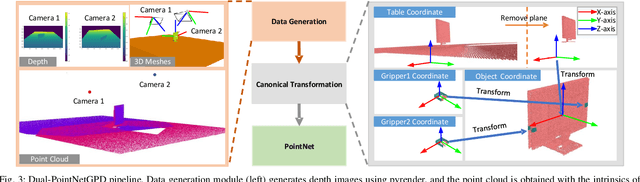
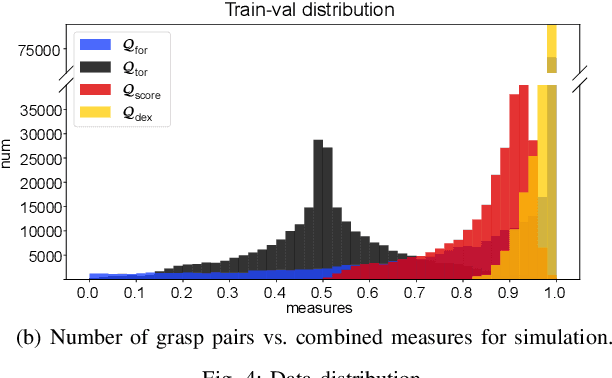
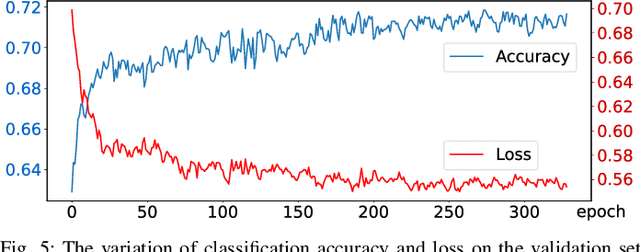
In this paper, we introduce DA$^2$, the first large-scale dual-arm dexterity-aware dataset for the generation of optimal bimanual grasping pairs for arbitrary large objects. The dataset contains about 9M pairs of parallel-jaw grasps, generated from more than 6000 objects and each labeled with various grasp dexterity measures. In addition, we propose an end-to-end dual-arm grasp evaluation model trained on the rendered scenes from this dataset. We utilize the evaluation model as our baseline to show the value of this novel and nontrivial dataset by both online analysis and real robot experiments. All data and related code will be open-sourced at https://sites.google.com/view/da2dataset.
ProDiff: Progressive Fast Diffusion Model For High-Quality Text-to-Speech
Jul 13, 2022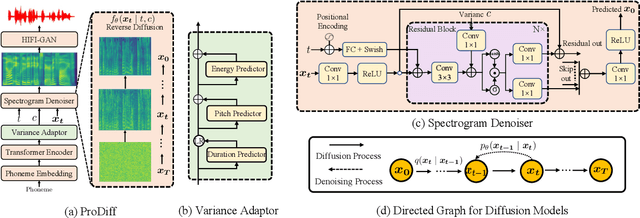
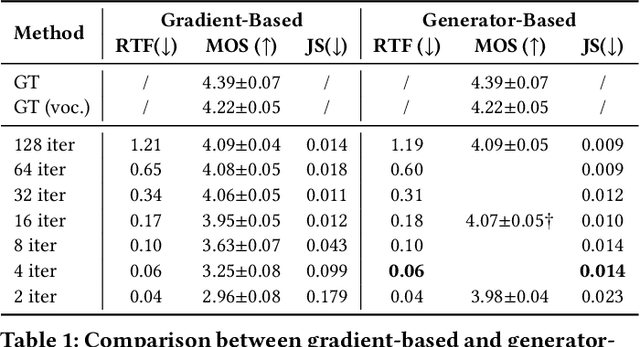
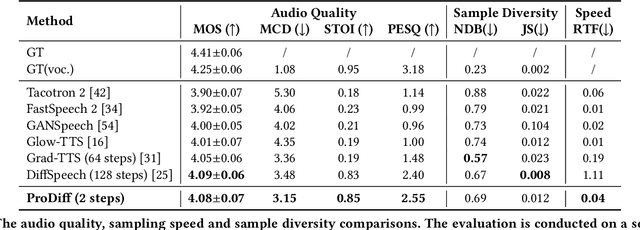
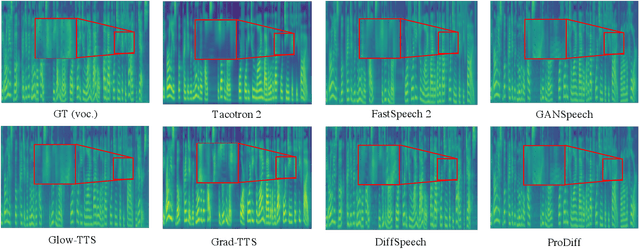
Denoising diffusion probabilistic models (DDPMs) have recently achieved leading performances in many generative tasks. However, the inherited iterative sampling process costs hinder their applications to text-to-speech deployment. Through the preliminary study on diffusion model parameterization, we find that previous gradient-based TTS models require hundreds or thousands of iterations to guarantee high sample quality, which poses a challenge for accelerating sampling. In this work, we propose ProDiff, on progressive fast diffusion model for high-quality text-to-speech. Unlike previous work estimating the gradient for data density, ProDiff parameterizes the denoising model by directly predicting clean data to avoid distinct quality degradation in accelerating sampling. To tackle the model convergence challenge with decreased diffusion iterations, ProDiff reduces the data variance in the target site via knowledge distillation. Specifically, the denoising model uses the generated mel-spectrogram from an N-step DDIM teacher as the training target and distills the behavior into a new model with N/2 steps. As such, it allows the TTS model to make sharp predictions and further reduces the sampling time by orders of magnitude. Our evaluation demonstrates that ProDiff needs only 2 iterations to synthesize high-fidelity mel-spectrograms, while it maintains sample quality and diversity competitive with state-of-the-art models using hundreds of steps. ProDiff enables a sampling speed of 24x faster than real-time on a single NVIDIA 2080Ti GPU, making diffusion models practically applicable to text-to-speech synthesis deployment for the first time. Our extensive ablation studies demonstrate that each design in ProDiff is effective, and we further show that ProDiff can be easily extended to the multi-speaker setting. Audio samples are available at \url{https://ProDiff.github.io/.}