 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDual Generator Offline Reinforcement Learning
Nov 02, 2022In offline RL, constraining the learned policy to remain close to the data is essential to prevent the policy from outputting out-of-distribution (OOD) actions with erroneously overestimated values. In principle, generative adversarial networks (GAN) can provide an elegant solution to do so, with the discriminator directly providing a probability that quantifies distributional shift. However, in practice, GAN-based offline RL methods have not performed as well as alternative approaches, perhaps because the generator is trained to both fool the discriminator and maximize return -- two objectives that can be at odds with each other. In this paper, we show that the issue of conflicting objectives can be resolved by training two generators: one that maximizes return, with the other capturing the ``remainder'' of the data distribution in the offline dataset, such that the mixture of the two is close to the behavior policy. We show that not only does having two generators enable an effective GAN-based offline RL method, but also approximates a support constraint, where the policy does not need to match the entire data distribution, but only the slice of the data that leads to high long term performance. We name our method DASCO, for Dual-Generator Adversarial Support Constrained Offline RL. On benchmark tasks that require learning from sub-optimal data, DASCO significantly outperforms prior methods that enforce distribution constraint.
Inner Monologue: Embodied Reasoning through Planning with Language Models
Jul 12, 2022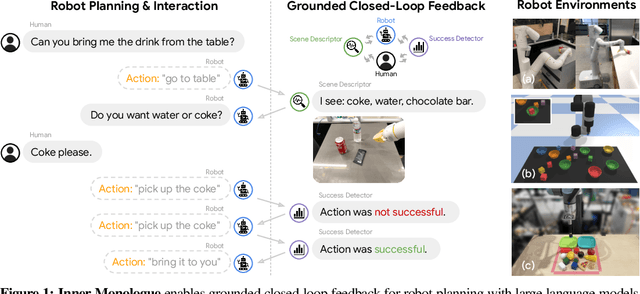
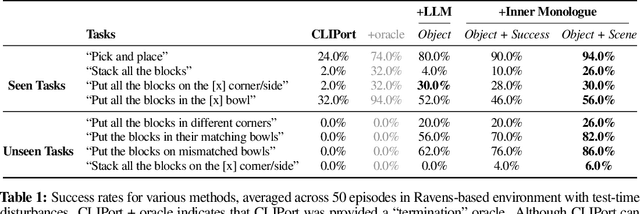


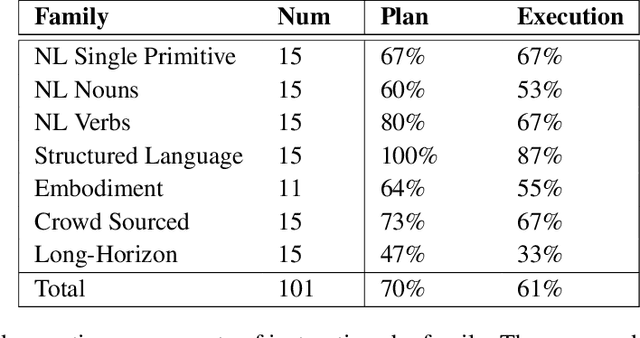
Recent works have shown how the reasoning capabilities of Large Language Models (LLMs) can be applied to domains beyond natural language processing, such as planning and interaction for robots. These embodied problems require an agent to understand many semantic aspects of the world: the repertoire of skills available, how these skills influence the world, and how changes to the world map back to the language. LLMs planning in embodied environments need to consider not just what skills to do, but also how and when to do them - answers that change over time in response to the agent's own choices. In this work, we investigate to what extent LLMs used in such embodied contexts can reason over sources of feedback provided through natural language, without any additional training. We propose that by leveraging environment feedback, LLMs are able to form an inner monologue that allows them to more richly process and plan in robotic control scenarios. We investigate a variety of sources of feedback, such as success detection, scene description, and human interaction. We find that closed-loop language feedback significantly improves high-level instruction completion on three domains, including simulated and real table top rearrangement tasks and long-horizon mobile manipulation tasks in a kitchen environment in the real world.
Do As I Can, Not As I Say: Grounding Language in Robotic Affordances
Apr 04, 2022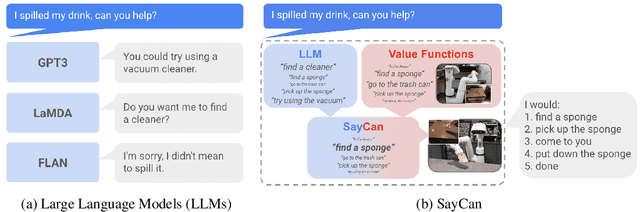
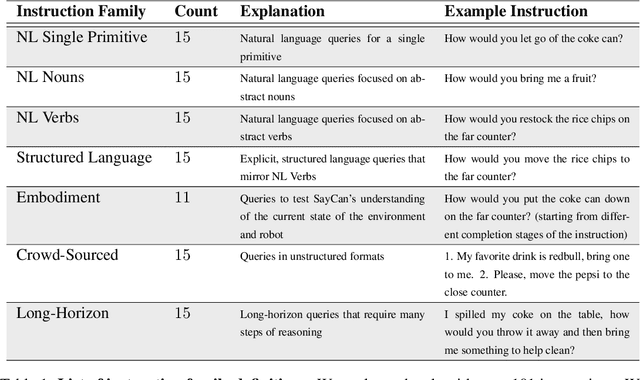
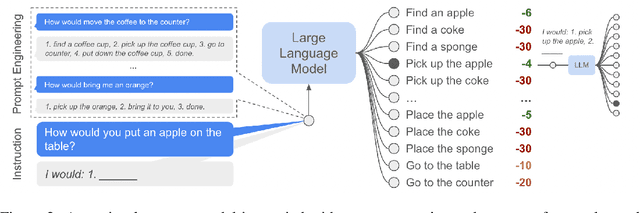
Large language models can encode a wealth of semantic knowledge about the world. Such knowledge could be extremely useful to robots aiming to act upon high-level, temporally extended instructions expressed in natural language. However, a significant weakness of language models is that they lack real-world experience, which makes it difficult to leverage them for decision making within a given embodiment. For example, asking a language model to describe how to clean a spill might result in a reasonable narrative, but it may not be applicable to a particular agent, such as a robot, that needs to perform this task in a particular environment. We propose to provide real-world grounding by means of pretrained skills, which are used to constrain the model to propose natural language actions that are both feasible and contextually appropriate. The robot can act as the language model's "hands and eyes," while the language model supplies high-level semantic knowledge about the task. We show how low-level skills can be combined with large language models so that the language model provides high-level knowledge about the procedures for performing complex and temporally-extended instructions, while value functions associated with these skills provide the grounding necessary to connect this knowledge to a particular physical environment. We evaluate our method on a number of real-world robotic tasks, where we show the need for real-world grounding and that this approach is capable of completing long-horizon, abstract, natural language instructions on a mobile manipulator. The project's website and the video can be found at https://say-can.github.io/
How to Leverage Unlabeled Data in Offline Reinforcement Learning
Feb 03, 2022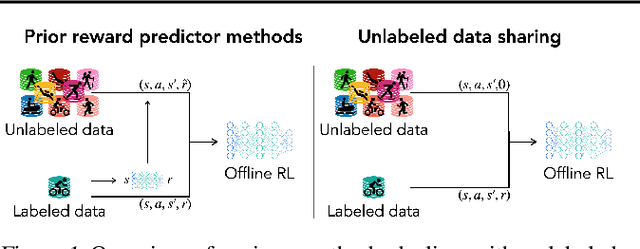
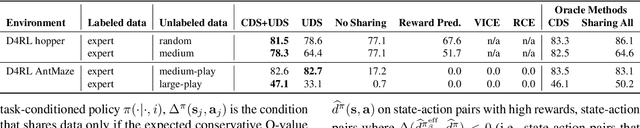


Offline reinforcement learning (RL) can learn control policies from static datasets but, like standard RL methods, it requires reward annotations for every transition. In many cases, labeling large datasets with rewards may be costly, especially if those rewards must be provided by human labelers, while collecting diverse unlabeled data might be comparatively inexpensive. How can we best leverage such unlabeled data in offline RL? One natural solution is to learn a reward function from the labeled data and use it to label the unlabeled data. In this paper, we find that, perhaps surprisingly, a much simpler method that simply applies zero rewards to unlabeled data leads to effective data sharing both in theory and in practice, without learning any reward model at all. While this approach might seem strange (and incorrect) at first, we provide extensive theoretical and empirical analysis that illustrates how it trades off reward bias, sample complexity and distributional shift, often leading to good results. We characterize conditions under which this simple strategy is effective, and further show that extending it with a simple reweighting approach can further alleviate the bias introduced by using incorrect reward labels. Our empirical evaluation confirms these findings in simulated robotic locomotion, navigation, and manipulation settings.
AW-Opt: Learning Robotic Skills with Imitation and Reinforcement at Scale
Nov 11, 2021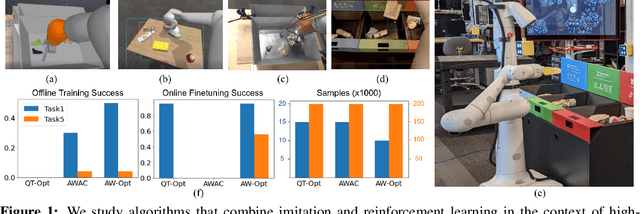
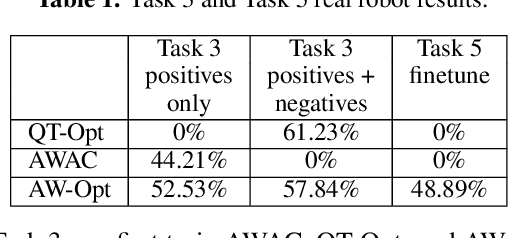
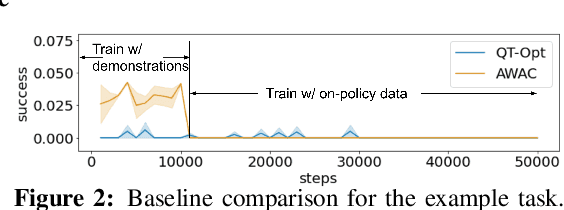
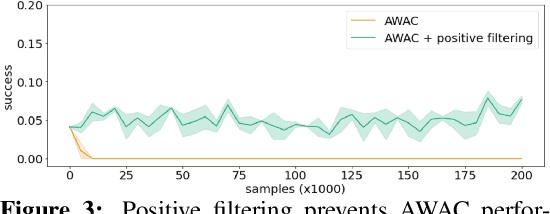
Robotic skills can be learned via imitation learning (IL) using user-provided demonstrations, or via reinforcement learning (RL) using large amountsof autonomously collected experience.Both methods have complementarystrengths and weaknesses: RL can reach a high level of performance, but requiresexploration, which can be very time consuming and unsafe; IL does not requireexploration, but only learns skills that are as good as the provided demonstrations.Can a single method combine the strengths of both approaches? A number ofprior methods have aimed to address this question, proposing a variety of tech-niques that integrate elements of IL and RL. However, scaling up such methodsto complex robotic skills that integrate diverse offline data and generalize mean-ingfully to real-world scenarios still presents a major challenge. In this paper, ouraim is to test the scalability of prior IL + RL algorithms and devise a system basedon detailed empirical experimentation that combines existing components in themost effective and scalable way. To that end, we present a series of experimentsaimed at understanding the implications of each design decision, so as to develop acombined approach that can utilize demonstrations and heterogeneous prior datato attain the best performance on a range of real-world and realistic simulatedrobotic problems. Our complete method, which we call AW-Opt, combines ele-ments of advantage-weighted regression [1, 2] and QT-Opt [3], providing a unifiedapproach for integrating demonstrations and offline data for robotic manipulation.Please see https://awopt.github.io for more details.
Conservative Data Sharing for Multi-Task Offline Reinforcement Learning
Sep 16, 2021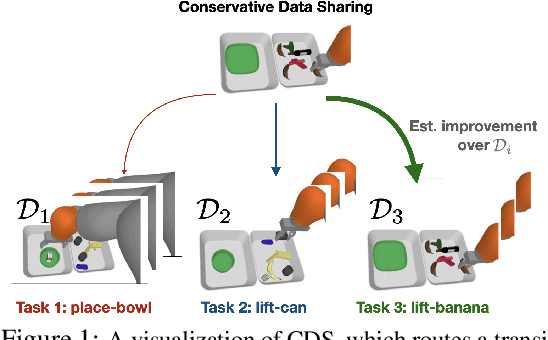
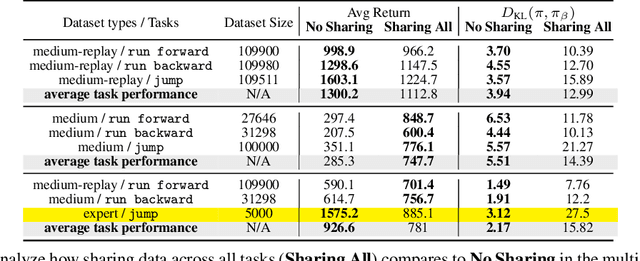
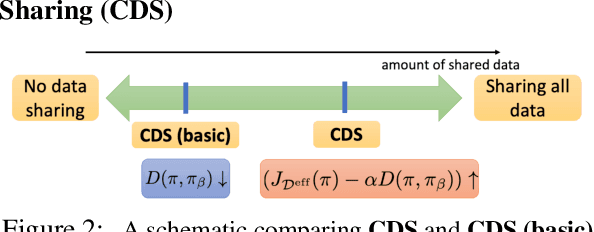

Offline reinforcement learning (RL) algorithms have shown promising results in domains where abundant pre-collected data is available. However, prior methods focus on solving individual problems from scratch with an offline dataset without considering how an offline RL agent can acquire multiple skills. We argue that a natural use case of offline RL is in settings where we can pool large amounts of data collected in various scenarios for solving different tasks, and utilize all of this data to learn behaviors for all the tasks more effectively rather than training each one in isolation. However, sharing data across all tasks in multi-task offline RL performs surprisingly poorly in practice. Thorough empirical analysis, we find that sharing data can actually exacerbate the distributional shift between the learned policy and the dataset, which in turn can lead to divergence of the learned policy and poor performance. To address this challenge, we develop a simple technique for data-sharing in multi-task offline RL that routes data based on the improvement over the task-specific data. We call this approach conservative data sharing (CDS), and it can be applied with multiple single-task offline RL methods. On a range of challenging multi-task locomotion, navigation, and vision-based robotic manipulation problems, CDS achieves the best or comparable performance compared to prior offline multi-task RL methods and previous data sharing approaches.
Actionable Models: Unsupervised Offline Reinforcement Learning of Robotic Skills
Apr 28, 2021

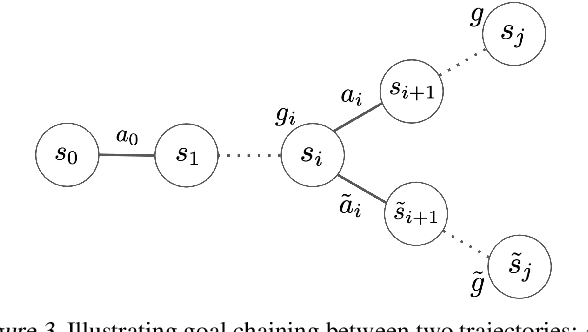
We consider the problem of learning useful robotic skills from previously collected offline data without access to manually specified rewards or additional online exploration, a setting that is becoming increasingly important for scaling robot learning by reusing past robotic data. In particular, we propose the objective of learning a functional understanding of the environment by learning to reach any goal state in a given dataset. We employ goal-conditioned Q-learning with hindsight relabeling and develop several techniques that enable training in a particularly challenging offline setting. We find that our method can operate on high-dimensional camera images and learn a variety of skills on real robots that generalize to previously unseen scenes and objects. We also show that our method can learn to reach long-horizon goals across multiple episodes, and learn rich representations that can help with downstream tasks through pre-training or auxiliary objectives. The videos of our experiments can be found at https://actionable-models.github.io
MT-Opt: Continuous Multi-Task Robotic Reinforcement Learning at Scale
Apr 27, 2021
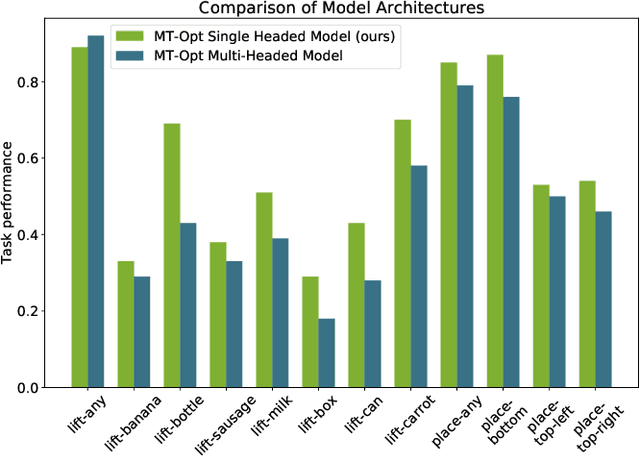
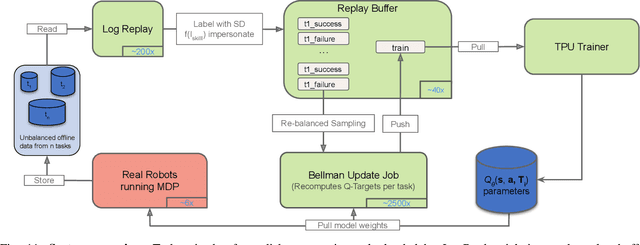
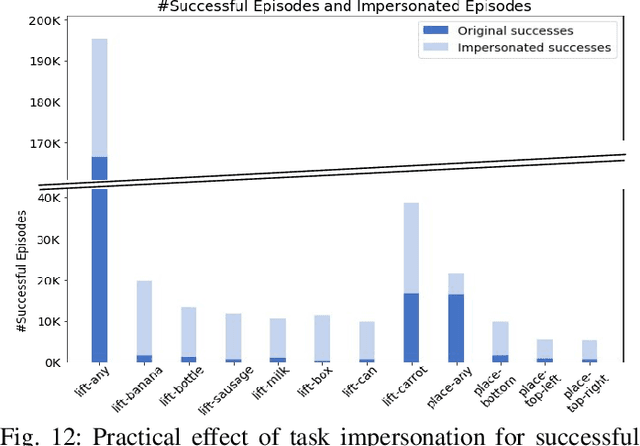
General-purpose robotic systems must master a large repertoire of diverse skills to be useful in a range of daily tasks. While reinforcement learning provides a powerful framework for acquiring individual behaviors, the time needed to acquire each skill makes the prospect of a generalist robot trained with RL daunting. In this paper, we study how a large-scale collective robotic learning system can acquire a repertoire of behaviors simultaneously, sharing exploration, experience, and representations across tasks. In this framework new tasks can be continuously instantiated from previously learned tasks improving overall performance and capabilities of the system. To instantiate this system, we develop a scalable and intuitive framework for specifying new tasks through user-provided examples of desired outcomes, devise a multi-robot collective learning system for data collection that simultaneously collects experience for multiple tasks, and develop a scalable and generalizable multi-task deep reinforcement learning method, which we call MT-Opt. We demonstrate how MT-Opt can learn a wide range of skills, including semantic picking (i.e., picking an object from a particular category), placing into various fixtures (e.g., placing a food item onto a plate), covering, aligning, and rearranging. We train and evaluate our system on a set of 12 real-world tasks with data collected from 7 robots, and demonstrate the performance of our system both in terms of its ability to generalize to structurally similar new tasks, and acquire distinct new tasks more quickly by leveraging past experience. We recommend viewing the videos at https://karolhausman.github.io/mt-opt/
Visionary: Vision architecture discovery for robot learning
Mar 26, 2021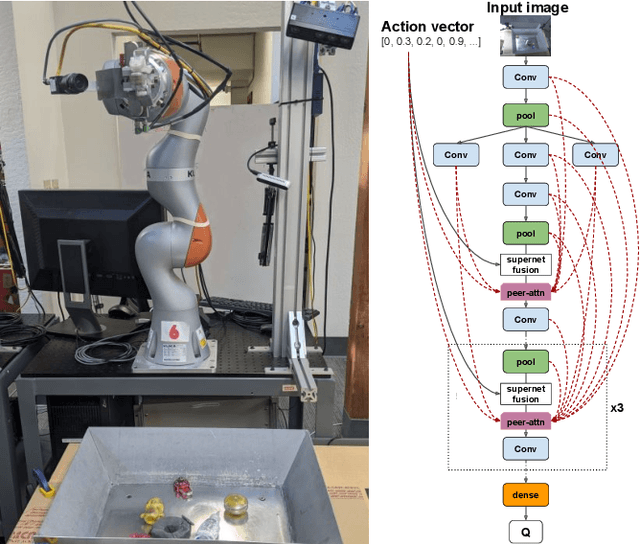
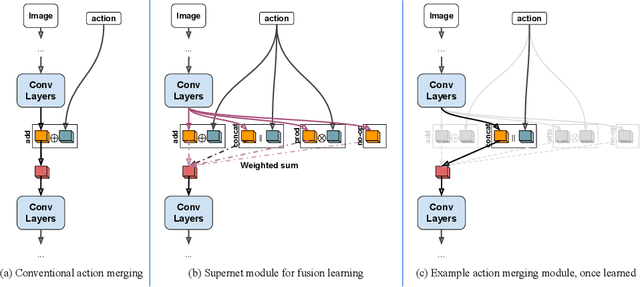
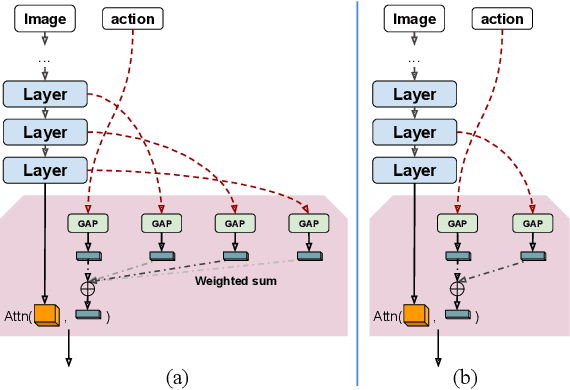
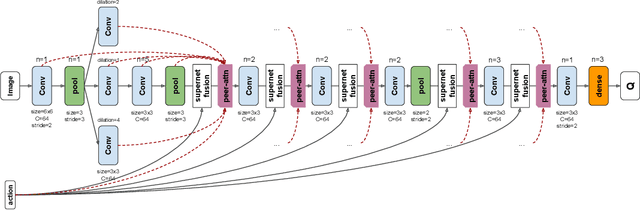
We propose a vision-based architecture search algorithm for robot manipulation learning, which discovers interactions between low dimension action inputs and high dimensional visual inputs. Our approach automatically designs architectures while training on the task - discovering novel ways of combining and attending image feature representations with actions as well as features from previous layers. The obtained new architectures demonstrate better task success rates, in some cases with a large margin, compared to a recent high performing baseline. Our real robot experiments also confirm that it improves grasping performance by 6%. This is the first approach to demonstrate a successful neural architecture search and attention connectivity search for a real-robot task.
Supervised Learning and Reinforcement Learning of Feedback Models for Reactive Behaviors: Tactile Feedback Testbed
Jun 29, 2020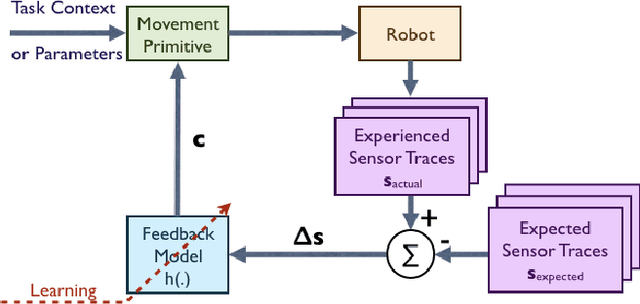
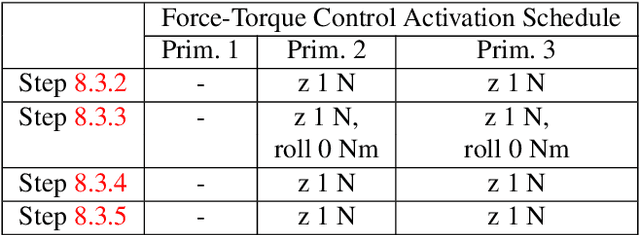

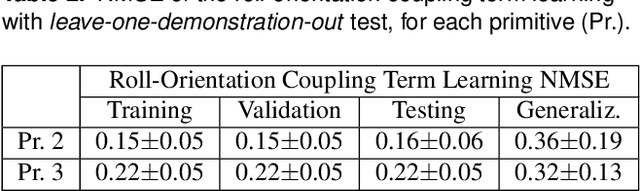
Robots need to be able to adapt to unexpected changes in the environment such that they can autonomously succeed in their tasks. However, hand-designing feedback models for adaptation is tedious, if at all possible, making data-driven methods a promising alternative. In this paper we introduce a full framework for learning feedback models for reactive motion planning. Our pipeline starts by segmenting demonstrations of a complete task into motion primitives via a semi-automated segmentation algorithm. Then, given additional demonstrations of successful adaptation behaviors, we learn initial feedback models through learning from demonstrations. In the final phase, a sample-efficient reinforcement learning algorithm fine-tunes these feedback models for novel task settings through few real system interactions. We evaluate our approach on a real anthropomorphic robot in learning a tactile feedback task.