 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGLM-OCR Technical Report
Mar 11, 2026GLM-OCR is an efficient 0.9B-parameter compact multimodal model designed for real-world document understanding. It combines a 0.4B-parameter CogViT visual encoder with a 0.5B-parameter GLM language decoder, achieving a strong balance between computational efficiency and recognition performance. To address the inefficiency of standard autoregressive decoding in deterministic OCR tasks, GLM-OCR introduces a Multi-Token Prediction (MTP) mechanism that predicts multiple tokens per step, significantly improving decoding throughput while keeping memory overhead low through shared parameters. At the system level, a two-stage pipeline is adopted: PP-DocLayout-V3 first performs layout analysis, followed by parallel region-level recognition. Extensive evaluations on public benchmarks and industrial scenarios show that GLM-OCR achieves competitive or state-of-the-art performance in document parsing, text and formula transcription, table structure recovery, and key information extraction. Its compact architecture and structured generation make it suitable for both resource-constrained edge deployment and large-scale production systems.
DendroNN: Dendrocentric Neural Networks for Energy-Efficient Classification of Event-Based Data
Mar 10, 2026Spatiotemporal information is at the core of diverse sensory processing and computational tasks. Feed-forward spiking neural networks can be used to solve these tasks while offering potential benefits in terms of energy efficiency by computing event-based. However, they have trouble decoding temporal information with high accuracy. Thus, they commonly resort to recurrence or delays to enhance their temporal computing ability which, however, bring downsides in terms of hardware-efficiency. In the brain, dendrites are computational powerhouses that just recently started to be acknowledged in such machine learning systems. In this work, we focus on a sequence detection mechanism present in branches of dendrites and translate it into a novel type of neural network by introducing a dendrocentric neural network, DendroNN. DendroNNs identify unique incoming spike sequences as spatiotemporal features. This work further introduces a rewiring phase to train the non-differentiable spike sequences without the use of gradients. During the rewiring, the network memorizes frequently occurring sequences and additionally discards those that do not contribute any discriminative information. The networks display competitive accuracies across various event-based time series datasets. We also propose an asynchronous digital hardware architecture using a time-wheel mechanism that builds on the event-driven design of DendroNNs, eliminating per-step global updates typical of delay- or recurrence-based models. By leveraging a DendroNN's dynamic and static sparsity along with intrinsic quantization, it achieves up to 4x higher efficiency than state-of-the-art neuromorphic hardware at comparable accuracy on the same audio classification task, demonstrating its suitability for spatiotemporal event-based computing. This work offers a novel approach to low-power spatiotemporal processing on event-driven hardware.
ElfCore: A 28nm Neural Processor Enabling Dynamic Structured Sparse Training and Online Self-Supervised Learning with Activity-Dependent Weight Update
Dec 24, 2025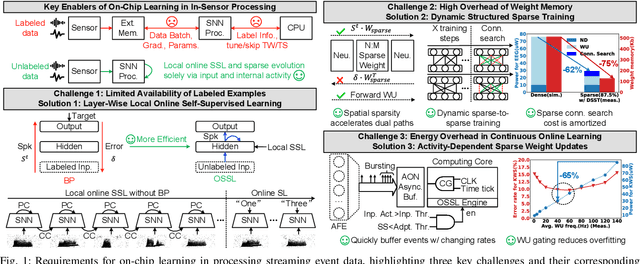
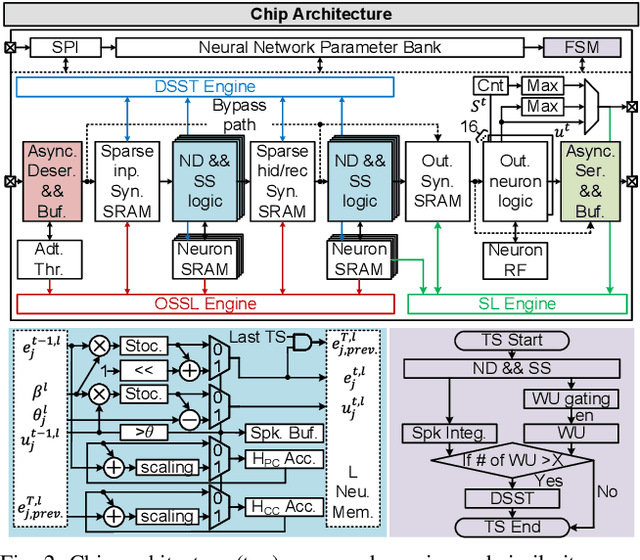
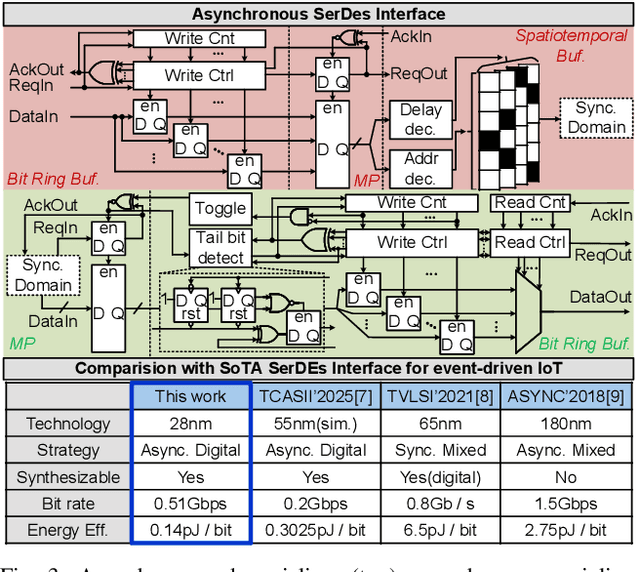
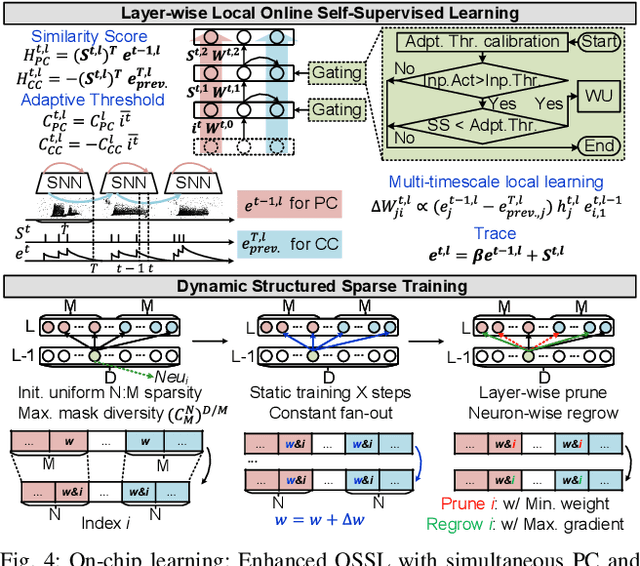
In this paper, we present ElfCore, a 28nm digital spiking neural network processor tailored for event-driven sensory signal processing. ElfCore is the first to efficiently integrate: (1) a local online self-supervised learning engine that enables multi-layer temporal learning without labeled inputs; (2) a dynamic structured sparse training engine that supports high-accuracy sparse-to-sparse learning; and (3) an activity-dependent sparse weight update mechanism that selectively updates weights based solely on input activity and network dynamics. Demonstrated on tasks including gesture recognition, speech, and biomedical signal processing, ElfCore outperforms state-of-the-art solutions with up to 16X lower power consumption, 3.8X reduced on-chip memory requirements, and 5.9X greater network capacity efficiency.
* This paper has been published in the proceedings of the 2025 IEEE European Solid-State Electronics Research Conference (ESSERC)
Algorithm-hardware co-design of neuromorphic networks with dual memory pathways
Dec 11, 2025Spiking neural networks excel at event-driven sensing. Yet, maintaining task-relevant context over long timescales both algorithmically and in hardware, while respecting both tight energy and memory budgets, remains a core challenge in the field. We address this challenge through novel algorithm-hardware co-design effort. At the algorithm level, inspired by the cortical fast-slow organization in the brain, we introduce a neural network with an explicit slow memory pathway that, combined with fast spiking activity, enables a dual memory pathway (DMP) architecture in which each layer maintains a compact low-dimensional state that summarizes recent activity and modulates spiking dynamics. This explicit memory stabilizes learning while preserving event-driven sparsity, achieving competitive accuracy on long-sequence benchmarks with 40-60% fewer parameters than equivalent state-of-the-art spiking neural networks. At the hardware level, we introduce a near-memory-compute architecture that fully leverages the advantages of the DMP architecture by retaining its compact shared state while optimizing dataflow, across heterogeneous sparse-spike and dense-memory pathways. We show experimental results that demonstrate more than a 4x increase in throughput and over a 5x improvement in energy efficiency compared with state-of-the-art implementations. Together, these contributions demonstrate that biological principles can guide functional abstractions that are both algorithmically effective and hardware-efficient, establishing a scalable co-design paradigm for real-time neuromorphic computation and learning.
Exploiting heterogeneous delays for efficient computation in low-bit neural networks
Oct 31, 2025Neural networks rely on learning synaptic weights. However, this overlooks other neural parameters that can also be learned and may be utilized by the brain. One such parameter is the delay: the brain exhibits complex temporal dynamics with heterogeneous delays, where signals are transmitted asynchronously between neurons. It has been theorized that this delay heterogeneity, rather than a cost to be minimized, can be exploited in embodied contexts where task-relevant information naturally sits contextually in the time domain. We test this hypothesis by training spiking neural networks to modify not only their weights but also their delays at different levels of precision. We find that delay heterogeneity enables state-of-the-art performance on temporally complex neuromorphic problems and can be achieved even when weights are extremely imprecise (1.58-bit ternary precision: just positive, negative, or absent). By enabling high performance with extremely low-precision weights, delay heterogeneity allows memory-efficient solutions that maintain state-of-the-art accuracy even when weights are compressed over an order of magnitude more aggressively than typically studied weight-only networks. We show how delays and time-constants adaptively trade-off, and reveal through ablation that task performance depends on task-appropriate delay distributions, with temporally-complex tasks requiring longer delays. Our results suggest temporal heterogeneity is an important principle for efficient computation, particularly when task-relevant information is temporal - as in the physical world - with implications for embodied intelligent systems and neuromorphic hardware.
GLM-4.1V-Thinking: Towards Versatile Multimodal Reasoning with Scalable Reinforcement Learning
Jul 02, 2025



We present GLM-4.1V-Thinking, a vision-language model (VLM) designed to advance general-purpose multimodal understanding and reasoning. In this report, we share our key findings in the development of the reasoning-centric training framework. We first develop a capable vision foundation model with significant potential through large-scale pre-training, which arguably sets the upper bound for the final performance. We then propose Reinforcement Learning with Curriculum Sampling (RLCS) to unlock the full potential of the model, leading to comprehensive capability enhancement across a diverse range of tasks, including STEM problem solving, video understanding, content recognition, coding, grounding, GUI-based agents, and long document understanding. We open-source GLM-4.1V-9B-Thinking, which achieves state-of-the-art performance among models of comparable size. In a comprehensive evaluation across 28 public benchmarks, our model outperforms Qwen2.5-VL-7B on nearly all tasks and achieves comparable or even superior performance on 18 benchmarks relative to the significantly larger Qwen2.5-VL-72B. Notably, GLM-4.1V-9B-Thinking also demonstrates competitive or superior performance compared to closed-source models such as GPT-4o on challenging tasks including long document understanding and STEM reasoning, further underscoring its strong capabilities. Code, models and more information are released at https://github.com/THUDM/GLM-4.1V-Thinking.
SOTOPIA-S4: a user-friendly system for flexible, customizable, and large-scale social simulation
Apr 19, 2025Social simulation through large language model (LLM) agents is a promising approach to explore and validate hypotheses related to social science questions and LLM agents behavior. We present SOTOPIA-S4, a fast, flexible, and scalable social simulation system that addresses the technical barriers of current frameworks while enabling practitioners to generate multi-turn and multi-party LLM-based interactions with customizable evaluation metrics for hypothesis testing. SOTOPIA-S4 comes as a pip package that contains a simulation engine, an API server with flexible RESTful APIs for simulation management, and a web interface that enables both technical and non-technical users to design, run, and analyze simulations without programming. We demonstrate the usefulness of SOTOPIA-S4 with two use cases involving dyadic hiring negotiation and multi-party planning scenarios.
Baichuan-Omni-1.5 Technical Report
Jan 26, 2025



We introduce Baichuan-Omni-1.5, an omni-modal model that not only has omni-modal understanding capabilities but also provides end-to-end audio generation capabilities. To achieve fluent and high-quality interaction across modalities without compromising the capabilities of any modality, we prioritized optimizing three key aspects. First, we establish a comprehensive data cleaning and synthesis pipeline for multimodal data, obtaining about 500B high-quality data (text, audio, and vision). Second, an audio-tokenizer (Baichuan-Audio-Tokenizer) has been designed to capture both semantic and acoustic information from audio, enabling seamless integration and enhanced compatibility with MLLM. Lastly, we designed a multi-stage training strategy that progressively integrates multimodal alignment and multitask fine-tuning, ensuring effective synergy across all modalities. Baichuan-Omni-1.5 leads contemporary models (including GPT4o-mini and MiniCPM-o 2.6) in terms of comprehensive omni-modal capabilities. Notably, it achieves results comparable to leading models such as Qwen2-VL-72B across various multimodal medical benchmarks.
TheAgentCompany: Benchmarking LLM Agents on Consequential Real World Tasks
Dec 18, 2024We interact with computers on an everyday basis, be it in everyday life or work, and many aspects of work can be done entirely with access to a computer and the Internet. At the same time, thanks to improvements in large language models (LLMs), there has also been a rapid development in AI agents that interact with and affect change in their surrounding environments. But how performant are AI agents at helping to accelerate or even autonomously perform work-related tasks? The answer to this question has important implications for both industry looking to adopt AI into their workflows, and for economic policy to understand the effects that adoption of AI may have on the labor market. To measure the progress of these LLM agents' performance on performing real-world professional tasks, in this paper, we introduce TheAgentCompany, an extensible benchmark for evaluating AI agents that interact with the world in similar ways to those of a digital worker: by browsing the Web, writing code, running programs, and communicating with other coworkers. We build a self-contained environment with internal web sites and data that mimics a small software company environment, and create a variety of tasks that may be performed by workers in such a company. We test baseline agents powered by both closed API-based and open-weights language models (LMs), and find that with the most competitive agent, 24% of the tasks can be completed autonomously. This paints a nuanced picture on task automation with LM agents -- in a setting simulating a real workplace, a good portion of simpler tasks could be solved autonomously, but more difficult long-horizon tasks are still beyond the reach of current systems.
An Efficient Multicast Addressing Encoding Scheme for Multi-Core Neuromorphic Processors
Nov 18, 2024Multi-core neuromorphic processors are becoming increasingly significant due to their energy-efficient local computing and scalable modular architecture, particularly for event-based processing applications. However, minimizing the cost of inter-core communication, which accounts for the majority of energy usage, remains a challenging issue. Beyond optimizing circuit design at lower abstraction levels, an efficient multicast addressing scheme is crucial. We propose a hierarchical bit string encoding scheme that largely expands the addressing capability of state-of-the-art symbol-based schemes for the same number of routing bits. When put at work with a real neuromorphic task, this hierarchical bit string encoding achieves a reduction in area cost by approximately 29% and decreases energy consumption by about 50%.