 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAn ADRC-Incorporated Stochastic Gradient Descent Algorithm for Latent Factor Analysis
Jan 13, 2024High-dimensional and incomplete (HDI) matrix contains many complex interactions between numerous nodes. A stochastic gradient descent (SGD)-based latent factor analysis (LFA) model is remarkably effective in extracting valuable information from an HDI matrix. However, such a model commonly encounters the problem of slow convergence because a standard SGD algorithm only considers the current learning error to compute the stochastic gradient without considering the historical and future state of the learning error. To address this critical issue, this paper innovatively proposes an ADRC-incorporated SGD (ADS) algorithm by refining the instance learning error by considering the historical and future state by following the principle of an ADRC controller. With it, an ADS-based LFA model is further achieved for fast and accurate latent factor analysis on an HDI matrix. Empirical studies on two HDI datasets demonstrate that the proposed model outperforms the state-of-the-art LFA models in terms of computational efficiency and accuracy for predicting the missing data of an HDI matrix.
Tensor Graph Convolutional Network for Dynamic Graph Representation Learning
Jan 13, 2024



Dynamic graphs (DG) describe dynamic interactions between entities in many practical scenarios. Most existing DG representation learning models combine graph convolutional network and sequence neural network, which model spatial-temporal dependencies through two different types of neural networks. However, this hybrid design cannot well capture the spatial-temporal continuity of a DG. In this paper, we propose a tensor graph convolutional network to learn DG representations in one convolution framework based on the tensor product with the following two-fold ideas: a) representing the information of DG by tensor form; b) adopting tensor product to design a tensor graph convolutional network modeling spatial-temporal feature simultaneously. Experiments on real-world DG datasets demonstrate that our model obtains state-of-the-art performance.
AGG: Amortized Generative 3D Gaussians for Single Image to 3D
Jan 08, 2024



Given the growing need for automatic 3D content creation pipelines, various 3D representations have been studied to generate 3D objects from a single image. Due to its superior rendering efficiency, 3D Gaussian splatting-based models have recently excelled in both 3D reconstruction and generation. 3D Gaussian splatting approaches for image to 3D generation are often optimization-based, requiring many computationally expensive score-distillation steps. To overcome these challenges, we introduce an Amortized Generative 3D Gaussian framework (AGG) that instantly produces 3D Gaussians from a single image, eliminating the need for per-instance optimization. Utilizing an intermediate hybrid representation, AGG decomposes the generation of 3D Gaussian locations and other appearance attributes for joint optimization. Moreover, we propose a cascaded pipeline that first generates a coarse representation of the 3D data and later upsamples it with a 3D Gaussian super-resolution module. Our method is evaluated against existing optimization-based 3D Gaussian frameworks and sampling-based pipelines utilizing other 3D representations, where AGG showcases competitive generation abilities both qualitatively and quantitatively while being several orders of magnitude faster. Project page: https://ir1d.github.io/AGG/
GAvatar: Animatable 3D Gaussian Avatars with Implicit Mesh Learning
Dec 18, 2023



Gaussian splatting has emerged as a powerful 3D representation that harnesses the advantages of both explicit (mesh) and implicit (NeRF) 3D representations. In this paper, we seek to leverage Gaussian splatting to generate realistic animatable avatars from textual descriptions, addressing the limitations (e.g., flexibility and efficiency) imposed by mesh or NeRF-based representations. However, a naive application of Gaussian splatting cannot generate high-quality animatable avatars and suffers from learning instability; it also cannot capture fine avatar geometries and often leads to degenerate body parts. To tackle these problems, we first propose a primitive-based 3D Gaussian representation where Gaussians are defined inside pose-driven primitives to facilitate animation. Second, to stabilize and amortize the learning of millions of Gaussians, we propose to use neural implicit fields to predict the Gaussian attributes (e.g., colors). Finally, to capture fine avatar geometries and extract detailed meshes, we propose a novel SDF-based implicit mesh learning approach for 3D Gaussians that regularizes the underlying geometries and extracts highly detailed textured meshes. Our proposed method, GAvatar, enables the large-scale generation of diverse animatable avatars using only text prompts. GAvatar significantly surpasses existing methods in terms of both appearance and geometry quality, and achieves extremely fast rendering (100 fps) at 1K resolution.
TRIGO: Benchmarking Formal Mathematical Proof Reduction for Generative Language Models
Oct 24, 2023Automated theorem proving (ATP) has become an appealing domain for exploring the reasoning ability of the recent successful generative language models. However, current ATP benchmarks mainly focus on symbolic inference, but rarely involve the understanding of complex number combination reasoning. In this work, we propose TRIGO, an ATP benchmark that not only requires a model to reduce a trigonometric expression with step-by-step proofs but also evaluates a generative LM's reasoning ability on formulas and its capability to manipulate, group, and factor number terms. We gather trigonometric expressions and their reduced forms from the web, annotate the simplification process manually, and translate it into the Lean formal language system. We then automatically generate additional examples from the annotated samples to expand the dataset. Furthermore, we develop an automatic generator based on Lean-Gym to create dataset splits of varying difficulties and distributions in order to thoroughly analyze the model's generalization ability. Our extensive experiments show our proposed TRIGO poses a new challenge for advanced generative LM's including GPT-4 which is pre-trained on a considerable amount of open-source formal theorem-proving language data, and provide a new tool to study the generative LM's ability on both formal and mathematical reasoning.
Learning to Generate Parameters of ConvNets for Unseen Image Data
Oct 24, 2023



Typical Convolutional Neural Networks (ConvNets) depend heavily on large amounts of image data and resort to an iterative optimization algorithm (e.g., SGD or Adam) to learn network parameters, which makes training very time- and resource-intensive. In this paper, we propose a new training paradigm and formulate the parameter learning of ConvNets into a prediction task: given a ConvNet architecture, we observe there exists correlations between image datasets and their corresponding optimal network parameters, and explore if we can learn a hyper-mapping between them to capture the relations, such that we can directly predict the parameters of the network for an image dataset never seen during the training phase. To do this, we put forward a new hypernetwork based model, called PudNet, which intends to learn a mapping between datasets and their corresponding network parameters, and then predicts parameters for unseen data with only a single forward propagation. Moreover, our model benefits from a series of adaptive hyper recurrent units sharing weights to capture the dependencies of parameters among different network layers. Extensive experiments demonstrate that our proposed method achieves good efficacy for unseen image datasets on two kinds of settings: Intra-dataset prediction and Inter-dataset prediction. Our PudNet can also well scale up to large-scale datasets, e.g., ImageNet-1K. It takes 8967 GPU seconds to train ResNet-18 on the ImageNet-1K using GC from scratch and obtain a top-5 accuracy of 44.65 %. However, our PudNet costs only 3.89 GPU seconds to predict the network parameters of ResNet-18 achieving comparable performance (44.92 %), more than 2,300 times faster than the traditional training paradigm.
Good Better Best: Self-Motivated Imitation Learning for noisy Demonstrations
Oct 24, 2023



Imitation Learning (IL) aims to discover a policy by minimizing the discrepancy between the agent's behavior and expert demonstrations. However, IL is susceptible to limitations imposed by noisy demonstrations from non-expert behaviors, presenting a significant challenge due to the lack of supplementary information to assess their expertise. In this paper, we introduce Self-Motivated Imitation LEarning (SMILE), a method capable of progressively filtering out demonstrations collected by policies deemed inferior to the current policy, eliminating the need for additional information. We utilize the forward and reverse processes of Diffusion Models to emulate the shift in demonstration expertise from low to high and vice versa, thereby extracting the noise information that diffuses expertise. Then, the noise information is leveraged to predict the diffusion steps between the current policy and demonstrators, which we theoretically demonstrate its equivalence to their expertise gap. We further explain in detail how the predicted diffusion steps are applied to filter out noisy demonstrations in a self-motivated manner and provide its theoretical grounds. Through empirical evaluations on MuJoCo tasks, we demonstrate that our method is proficient in learning the expert policy amidst noisy demonstrations, and effectively filters out demonstrations with expertise inferior to the current policy.
PACE: Human and Camera Motion Estimation from in-the-wild Videos
Oct 20, 2023
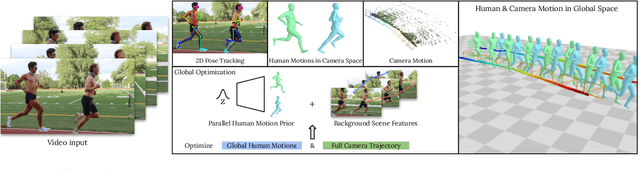
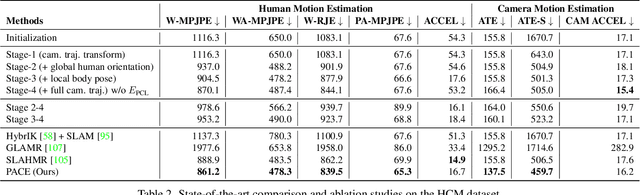

We present a method to estimate human motion in a global scene from moving cameras. This is a highly challenging task due to the coupling of human and camera motions in the video. To address this problem, we propose a joint optimization framework that disentangles human and camera motions using both foreground human motion priors and background scene features. Unlike existing methods that use SLAM as initialization, we propose to tightly integrate SLAM and human motion priors in an optimization that is inspired by bundle adjustment. Specifically, we optimize human and camera motions to match both the observed human pose and scene features. This design combines the strengths of SLAM and motion priors, which leads to significant improvements in human and camera motion estimation. We additionally introduce a motion prior that is suitable for batch optimization, making our approach significantly more efficient than existing approaches. Finally, we propose a novel synthetic dataset that enables evaluating camera motion in addition to human motion from dynamic videos. Experiments on the synthetic and real-world RICH datasets demonstrate that our approach substantially outperforms prior art in recovering both human and camera motions.
Reusing Pretrained Models by Multi-linear Operators for Efficient Training
Oct 16, 2023Training large models from scratch usually costs a substantial amount of resources. Towards this problem, recent studies such as bert2BERT and LiGO have reused small pretrained models to initialize a large model (termed the ``target model''), leading to a considerable acceleration in training. Despite the successes of these previous studies, they grew pretrained models by mapping partial weights only, ignoring potential correlations across the entire model. As we show in this paper, there are inter- and intra-interactions among the weights of both the pretrained and the target models. As a result, the partial mapping may not capture the complete information and lead to inadequate growth. In this paper, we propose a method that linearly correlates each weight of the target model to all the weights of the pretrained model to further enhance acceleration ability. We utilize multi-linear operators to reduce computational and spacial complexity, enabling acceptable resource requirements. Experiments demonstrate that our method can save 76\% computational costs on DeiT-base transferred from DeiT-small, which outperforms bert2BERT by +12.0\% and LiGO by +20.7\%, respectively.
FIMO: A Challenge Formal Dataset for Automated Theorem Proving
Sep 08, 2023



We present FIMO, an innovative dataset comprising formal mathematical problem statements sourced from the International Mathematical Olympiad (IMO) Shortlisted Problems. Designed to facilitate advanced automated theorem proving at the IMO level, FIMO is currently tailored for the Lean formal language. It comprises 149 formal problem statements, accompanied by both informal problem descriptions and their corresponding LaTeX-based informal proofs. Through initial experiments involving GPT-4, our findings underscore the existing limitations in current methodologies, indicating a substantial journey ahead before achieving satisfactory IMO-level automated theorem proving outcomes.