 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHarmony in Divergence: Towards Fast, Accurate, and Memory-efficient Zeroth-order LLM Fine-tuning
Feb 05, 2025



Large language models (LLMs) excel across various tasks, but standard first-order (FO) fine-tuning demands considerable memory, significantly limiting real-world deployment. Recently, zeroth-order (ZO) optimization stood out as a promising memory-efficient training paradigm, avoiding backward passes and relying solely on forward passes for gradient estimation, making it attractive for resource-constrained scenarios. However, ZO method lags far behind FO method in both convergence speed and accuracy. To bridge the gap, we introduce a novel layer-wise divergence analysis that uncovers the distinct update pattern of FO and ZO optimization. Aiming to resemble the learning capacity of FO method from the findings, we propose \textbf{Di}vergence-driven \textbf{Z}eroth-\textbf{O}rder (\textbf{DiZO}) optimization. DiZO conducts divergence-driven layer adaptation by incorporating projections to ZO updates, generating diverse-magnitude updates precisely scaled to layer-wise individual optimization needs. Our results demonstrate that DiZO significantly reduces the needed iterations for convergence without sacrificing throughput, cutting training GPU hours by up to 48\% on various datasets. Moreover, DiZO consistently outperforms the representative ZO baselines in fine-tuning RoBERTa-large, OPT-series, and Llama-series on downstream tasks and, in some cases, even surpasses memory-intensive FO fine-tuning.
Efficient Reasoning with Hidden Thinking
Jan 31, 2025



Chain-of-Thought (CoT) reasoning has become a powerful framework for improving complex problem-solving capabilities in Multimodal Large Language Models (MLLMs). However, the verbose nature of textual reasoning introduces significant inefficiencies. In this work, we propose $\textbf{Heima}$ (as hidden llama), an efficient reasoning framework that leverages reasoning CoTs at hidden latent space. We design the Heima Encoder to condense each intermediate CoT into a compact, higher-level hidden representation using a single thinking token, effectively minimizing verbosity and reducing the overall number of tokens required during the reasoning process. Meanwhile, we design corresponding Heima Decoder with traditional Large Language Models (LLMs) to adaptively interpret the hidden representations into variable-length textual sequence, reconstructing reasoning processes that closely resemble the original CoTs. Experimental results across diverse reasoning MLLM benchmarks demonstrate that Heima model achieves higher generation efficiency while maintaining or even better zero-shot task accuracy. Moreover, the effective reconstruction of multimodal reasoning processes with Heima Decoder validates both the robustness and interpretability of our approach.
RoRA: Efficient Fine-Tuning of LLM with Reliability Optimization for Rank Adaptation
Jan 08, 2025



Fine-tuning helps large language models (LLM) recover degraded information and enhance task performance.Although Low-Rank Adaptation (LoRA) is widely used and effective for fine-tuning, we have observed that its scaling factor can limit or even reduce performance as the rank size increases. To address this issue, we propose RoRA (Rank-adaptive Reliability Optimization), a simple yet effective method for optimizing LoRA's scaling factor. By replacing $\alpha/r$ with $\alpha/\sqrt{r}$, RoRA ensures improved performance as rank size increases. Moreover, RoRA enhances low-rank adaptation in fine-tuning uncompressed models and excels in the more challenging task of accuracy recovery when fine-tuning pruned models. Extensive experiments demonstrate the effectiveness of RoRA in fine-tuning both uncompressed and pruned models. RoRA surpasses the state-of-the-art (SOTA) in average accuracy and robustness on LLaMA-7B/13B, LLaMA2-7B, and LLaMA3-8B, specifically outperforming LoRA and DoRA by 6.5% and 2.9% on LLaMA-7B, respectively. In pruned model fine-tuning, RoRA shows significant advantages; for SHEARED-LLAMA-1.3, a LLaMA-7B with 81.4% pruning, RoRA achieves 5.7% higher average accuracy than LoRA and 3.9% higher than DoRA.
All-in-One Tuning and Structural Pruning for Domain-Specific LLMs
Dec 19, 2024



Existing pruning techniques for large language models (LLMs) targeting domain-specific applications typically follow a two-stage process: pruning the pretrained general-purpose LLMs and then fine-tuning the pruned LLMs on specific domains. However, the pruning decisions, derived from the pretrained weights, remain unchanged during fine-tuning, even if the weights have been updated. Therefore, such a combination of the pruning decisions and the finetuned weights may be suboptimal, leading to non-negligible performance degradation. To address these limitations, we propose ATP: All-in-One Tuning and Structural Pruning, a unified one-stage structural pruning and fine-tuning approach that dynamically identifies the current optimal substructure throughout the fine-tuning phase via a trainable pruning decision generator. Moreover, given the limited available data for domain-specific applications, Low-Rank Adaptation (LoRA) becomes a common technique to fine-tune the LLMs. In ATP, we introduce LoRA-aware forward and sparsity regularization to ensure that the substructures corresponding to the learned pruning decisions can be directly removed after the ATP process. ATP outperforms the state-of-the-art two-stage pruning methods on tasks in the legal and healthcare domains. More specifically, ATP recovers up to 88% and 91% performance of the dense model when pruning 40% parameters of LLaMA2-7B and LLaMA3-8B models, respectively.
LazyDiT: Lazy Learning for the Acceleration of Diffusion Transformers
Dec 17, 2024Diffusion Transformers have emerged as the preeminent models for a wide array of generative tasks, demonstrating superior performance and efficacy across various applications. The promising results come at the cost of slow inference, as each denoising step requires running the whole transformer model with a large amount of parameters. In this paper, we show that performing the full computation of the model at each diffusion step is unnecessary, as some computations can be skipped by lazily reusing the results of previous steps. Furthermore, we show that the lower bound of similarity between outputs at consecutive steps is notably high, and this similarity can be linearly approximated using the inputs. To verify our demonstrations, we propose the \textbf{LazyDiT}, a lazy learning framework that efficiently leverages cached results from earlier steps to skip redundant computations. Specifically, we incorporate lazy learning layers into the model, effectively trained to maximize laziness, enabling dynamic skipping of redundant computations. Experimental results show that LazyDiT outperforms the DDIM sampler across multiple diffusion transformer models at various resolutions. Furthermore, we implement our method on mobile devices, achieving better performance than DDIM with similar latency.
Numerical Pruning for Efficient Autoregressive Models
Dec 17, 2024



Transformers have emerged as the leading architecture in deep learning, proving to be versatile and highly effective across diverse domains beyond language and image processing. However, their impressive performance often incurs high computational costs due to their substantial model size. This paper focuses on compressing decoder-only transformer-based autoregressive models through structural weight pruning to improve the model efficiency while preserving performance for both language and image generation tasks. Specifically, we propose a training-free pruning method that calculates a numerical score with Newton's method for the Attention and MLP modules, respectively. Besides, we further propose another compensation algorithm to recover the pruned model for better performance. To verify the effectiveness of our method, we provide both theoretical support and extensive experiments. Our experiments show that our method achieves state-of-the-art performance with reduced memory usage and faster generation speeds on GPUs.
SnapGen-V: Generating a Five-Second Video within Five Seconds on a Mobile Device
Dec 13, 2024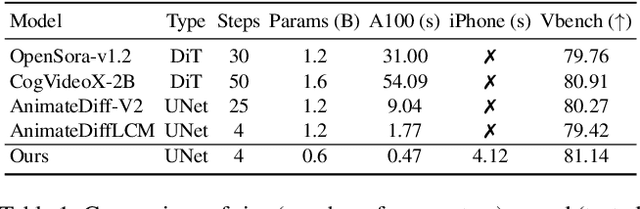
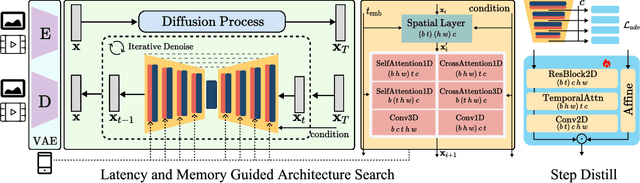
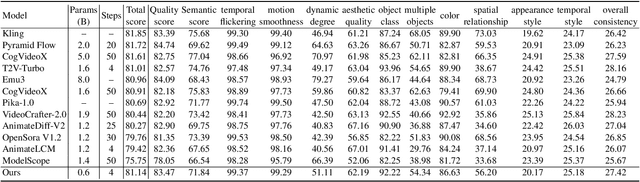
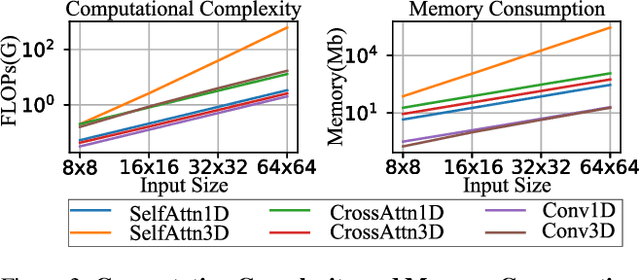
We have witnessed the unprecedented success of diffusion-based video generation over the past year. Recently proposed models from the community have wielded the power to generate cinematic and high-resolution videos with smooth motions from arbitrary input prompts. However, as a supertask of image generation, video generation models require more computation and are thus hosted mostly on cloud servers, limiting broader adoption among content creators. In this work, we propose a comprehensive acceleration framework to bring the power of the large-scale video diffusion model to the hands of edge users. From the network architecture scope, we initialize from a compact image backbone and search out the design and arrangement of temporal layers to maximize hardware efficiency. In addition, we propose a dedicated adversarial fine-tuning algorithm for our efficient model and reduce the denoising steps to 4. Our model, with only 0.6B parameters, can generate a 5-second video on an iPhone 16 PM within 5 seconds. Compared to server-side models that take minutes on powerful GPUs to generate a single video, we accelerate the generation by magnitudes while delivering on-par quality.
Fully Open Source Moxin-7B Technical Report
Dec 08, 2024



Recently, Large Language Models (LLMs) have undergone a significant transformation, marked by a rapid rise in both their popularity and capabilities. Leading this evolution are proprietary LLMs like GPT-4 and GPT-o1, which have captured widespread attention in the AI community due to their remarkable performance and versatility. Simultaneously, open-source LLMs, such as LLaMA and Mistral, have made great contributions to the ever-increasing popularity of LLMs due to the ease to customize and deploy the models across diverse applications. Although open-source LLMs present unprecedented opportunities for innovation and research, the commercialization of LLMs has raised concerns about transparency, reproducibility, and safety. Many open-source LLMs fail to meet fundamental transparency requirements by withholding essential components like training code and data, and some use restrictive licenses whilst claiming to be "open-source," which may hinder further innovations on LLMs. To mitigate this issue, we introduce Moxin 7B, a fully open-source LLM developed in accordance with the Model Openness Framework (MOF), a ranked classification system that evaluates AI models based on model completeness and openness, adhering to principles of open science, open source, open data, and open access. Our model achieves the highest MOF classification level of "open science" through the comprehensive release of pre-training code and configurations, training and fine-tuning datasets, and intermediate and final checkpoints. Experiments show that our model achieves superior performance in zero-shot evaluation compared with popular 7B models and performs competitively in few-shot evaluation.
Open-Source Acceleration of Stable-Diffusion.cpp
Dec 08, 2024



Stable diffusion plays a crucial role in generating high-quality images. However, image generation is time-consuming and memory-intensive. To address this, stable-diffusion.cpp (Sdcpp) emerges as an efficient inference framework to accelerate the diffusion models. Although it is lightweight, the current implementation of ggml_conv_2d operator in Sdcpp is suboptimal, exhibiting both high inference latency and massive memory usage. To address this, in this work, we present an optimized version of Sdcpp leveraging the Winograd algorithm to accelerate 2D convolution operations, which is the primary bottleneck in the pipeline. By analyzing both dependent and independent computation graphs, we exploit the device's locality and parallelism to achieve substantial performance improvements. Our framework delivers correct end-to-end results across various stable diffusion models, including SDv1.4, v1.5, v2.1, SDXL, and SDXL-Turbo. Our evaluation results demonstrate a speedup up to 2.76x for individual convolutional layers and an inference speedup up to 4.79x for the overall image generation process, compared with the original Sdcpp. Homepage: https://github.com/SealAILab/stable-diffusion-cpp
Domain Adaptation-based Edge Computing for Cross-Conditions Fault Diagnosis
Nov 15, 2024



Fault diagnosis technology supports the healthy operation of mechanical equipment. However, the variations conditions during the operation of mechanical equipment lead to significant disparities in data distribution, posing challenges to fault diagnosis. Furthermore, when deploying applications, traditional methods often encounter issues such as latency and data security. Therefore, conducting fault diagnosis and deploying application methods under cross-operating conditions holds significant value. This paper proposes a domain adaptation-based lightweight fault diagnosis framework for edge computing scenarios. Incorporating the local maximum mean discrepancy into knowledge transfer aligns the feature distributions of different domains in a high-dimensional feature space, to discover a common feature space across domains. The acquired fault diagnosis expertise from the cloud-model is transferred to the lightweight edge-model using adaptation knowledge transfer methods. While ensuring real-time diagnostic capabilities, accurate fault diagnosis is achieved across working conditions. We conducted validation experiments on the NVIDIA Jetson Xavier NX kit. In terms of diagnostic performance, the proposed method significantly improved diagnostic accuracy, with average increases of 34.44% and 17.33% compared to the comparison method, respectively. Regarding lightweight effectiveness, proposed method achieved an average inference speed increase of 80.47%. Additionally, compared to the cloud-model, the parameter count of the edge-model decreased by 96.37%, while the Flops decreased by 83.08%.