 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRCR-Router: Efficient Role-Aware Context Routing for Multi-Agent LLM Systems with Structured Memory
Aug 06, 2025Multi-agent large language model (LLM) systems have shown strong potential in complex reasoning and collaborative decision-making tasks. However, most existing coordination schemes rely on static or full-context routing strategies, which lead to excessive token consumption, redundant memory exposure, and limited adaptability across interaction rounds. We introduce RCR-Router, a modular and role-aware context routing framework designed to enable efficient, adaptive collaboration in multi-agent LLMs. To our knowledge, this is the first routing approach that dynamically selects semantically relevant memory subsets for each agent based on its role and task stage, while adhering to a strict token budget. A lightweight scoring policy guides memory selection, and agent outputs are iteratively integrated into a shared memory store to facilitate progressive context refinement. To better evaluate model behavior, we further propose an Answer Quality Score metric that captures LLM-generated explanations beyond standard QA accuracy. Experiments on three multi-hop QA benchmarks -- HotPotQA, MuSiQue, and 2WikiMultihop -- demonstrate that RCR-Router reduces token usage (up to 30%) while improving or maintaining answer quality. These results highlight the importance of structured memory routing and output-aware evaluation in advancing scalable multi-agent LLM systems.
Taming Diffusion Transformer for Real-Time Mobile Video Generation
Jul 17, 2025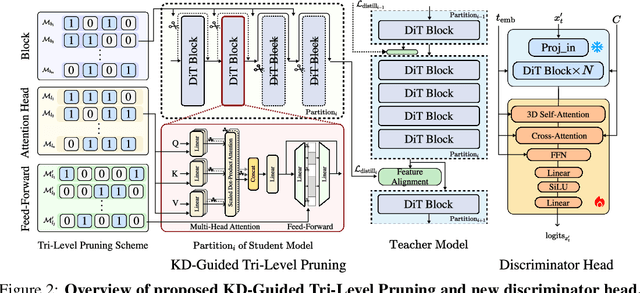
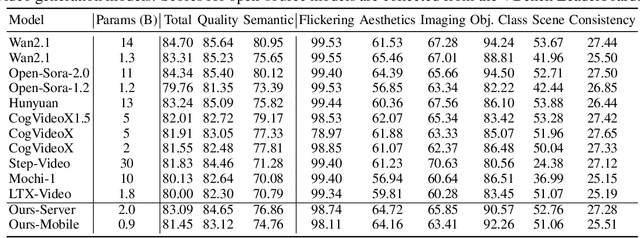

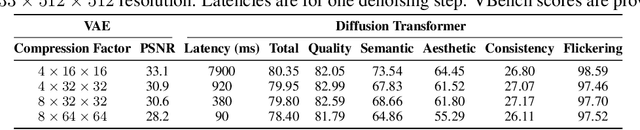
Diffusion Transformers (DiT) have shown strong performance in video generation tasks, but their high computational cost makes them impractical for resource-constrained devices like smartphones, and real-time generation is even more challenging. In this work, we propose a series of novel optimizations to significantly accelerate video generation and enable real-time performance on mobile platforms. First, we employ a highly compressed variational autoencoder (VAE) to reduce the dimensionality of the input data without sacrificing visual quality. Second, we introduce a KD-guided, sensitivity-aware tri-level pruning strategy to shrink the model size to suit mobile platform while preserving critical performance characteristics. Third, we develop an adversarial step distillation technique tailored for DiT, which allows us to reduce the number of inference steps to four. Combined, these optimizations enable our model to achieve over 10 frames per second (FPS) generation on an iPhone 16 Pro Max, demonstrating the feasibility of real-time, high-quality video generation on mobile devices.
Enabling Flexible Multi-LLM Integration for Scalable Knowledge Aggregation
May 28, 2025



Large language models (LLMs) have shown remarkable promise but remain challenging to continually improve through traditional finetuning, particularly when integrating capabilities from other specialized LLMs. Popular methods like ensemble and weight merging require substantial memory and struggle to adapt to changing data environments. Recent efforts have transferred knowledge from multiple LLMs into a single target model; however, they suffer from interference and degraded performance among tasks, largely due to limited flexibility in candidate selection and training pipelines. To address these issues, we propose a framework that adaptively selects and aggregates knowledge from diverse LLMs to build a single, stronger model, avoiding the high memory overhead of ensemble and inflexible weight merging. Specifically, we design an adaptive selection network that identifies the most relevant source LLMs based on their scores, thereby reducing knowledge interference. We further propose a dynamic weighted fusion strategy that accounts for the inherent strengths of candidate LLMs, along with a feedback-driven loss function that prevents the selector from converging on a single subset of sources. Experimental results demonstrate that our method can enable a more stable and scalable knowledge aggregation process while reducing knowledge interference by up to 50% compared to existing approaches. Code is avaliable at https://github.com/ZLKong/LLM_Integration
ALTER: All-in-One Layer Pruning and Temporal Expert Routing for Efficient Diffusion Generation
May 27, 2025Diffusion models have demonstrated exceptional capabilities in generating high-fidelity images. However, their iterative denoising process results in significant computational overhead during inference, limiting their practical deployment in resource-constrained environments. Existing acceleration methods often adopt uniform strategies that fail to capture the temporal variations during diffusion generation, while the commonly adopted sequential pruning-then-fine-tuning strategy suffers from sub-optimality due to the misalignment between pruning decisions made on pretrained weights and the model's final parameters. To address these limitations, we introduce ALTER: All-in-One Layer Pruning and Temporal Expert Routing, a unified framework that transforms diffusion models into a mixture of efficient temporal experts. ALTER achieves a single-stage optimization that unifies layer pruning, expert routing, and model fine-tuning by employing a trainable hypernetwork, which dynamically generates layer pruning decisions and manages timestep routing to specialized, pruned expert sub-networks throughout the ongoing fine-tuning of the UNet. This unified co-optimization strategy enables significant efficiency gains while preserving high generative quality. Specifically, ALTER achieves same-level visual fidelity to the original 50-step Stable Diffusion v2.1 model while utilizing only 25.9% of its total MACs with just 20 inference steps and delivering a 3.64x speedup through 35% sparsity.
Taming Diffusion for Dataset Distillation with High Representativeness
May 23, 2025Recent deep learning models demand larger datasets, driving the need for dataset distillation to create compact, cost-efficient datasets while maintaining performance. Due to the powerful image generation capability of diffusion, it has been introduced to this field for generating distilled images. In this paper, we systematically investigate issues present in current diffusion-based dataset distillation methods, including inaccurate distribution matching, distribution deviation with random noise, and separate sampling. Building on this, we propose D^3HR, a novel diffusion-based framework to generate distilled datasets with high representativeness. Specifically, we adopt DDIM inversion to map the latents of the full dataset from a low-normality latent domain to a high-normality Gaussian domain, preserving information and ensuring structural consistency to generate representative latents for the distilled dataset. Furthermore, we propose an efficient sampling scheme to better align the representative latents with the high-normality Gaussian distribution. Our comprehensive experiments demonstrate that D^3HR can achieve higher accuracy across different model architectures compared with state-of-the-art baselines in dataset distillation. Source code: https://github.com/lin-zhao-resoLve/D3HR.
Structured Agent Distillation for Large Language Model
May 20, 2025
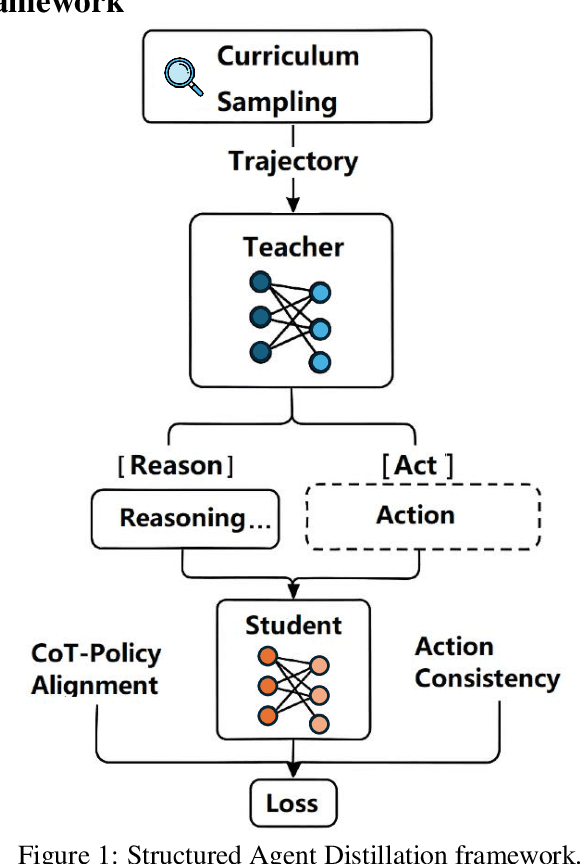

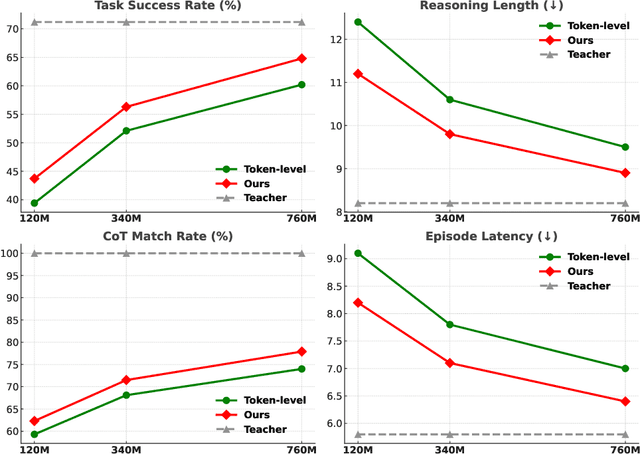
Large language models (LLMs) exhibit strong capabilities as decision-making agents by interleaving reasoning and actions, as seen in ReAct-style frameworks. Yet, their practical deployment is constrained by high inference costs and large model sizes. We propose Structured Agent Distillation, a framework that compresses large LLM-based agents into smaller student models while preserving both reasoning fidelity and action consistency. Unlike standard token-level distillation, our method segments trajectories into {[REASON]} and {[ACT]} spans, applying segment-specific losses to align each component with the teacher's behavior. This structure-aware supervision enables compact agents to better replicate the teacher's decision process. Experiments on ALFWorld, HotPotQA-ReAct, and WebShop show that our approach consistently outperforms token-level and imitation learning baselines, achieving significant compression with minimal performance drop. Scaling and ablation results further highlight the importance of span-level alignment for efficient and deployable agents.
Perturbation-efficient Zeroth-order Optimization for Hardware-friendly On-device Training
Apr 28, 2025
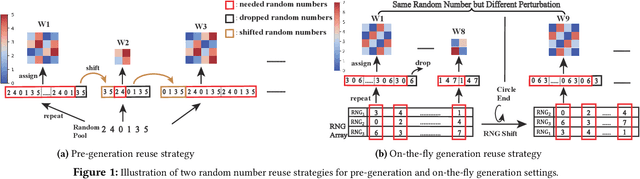


Zeroth-order (ZO) optimization is an emerging deep neural network (DNN) training paradigm that offers computational simplicity and memory savings. However, this seemingly promising approach faces a significant and long-ignored challenge. ZO requires generating a substantial number of Gaussian random numbers, which poses significant difficulties and even makes it infeasible for hardware platforms, such as FPGAs and ASICs. In this paper, we identify this critical issue, which arises from the mismatch between algorithm and hardware designers. To address this issue, we proposed PeZO, a perturbation-efficient ZO framework. Specifically, we design random number reuse strategies to significantly reduce the demand for random number generation and introduce a hardware-friendly adaptive scaling method to replace the costly Gaussian distribution with a uniform distribution. Our experiments show that PeZO reduces the required LUTs and FFs for random number generation by 48.6\% and 12.7\%, and saves at maximum 86\% power consumption, all without compromising training performance, making ZO optimization feasible for on-device training. To the best of our knowledge, we are the first to explore the potential of on-device ZO optimization, providing valuable insights for future research.
H3AE: High Compression, High Speed, and High Quality AutoEncoder for Video Diffusion Models
Apr 14, 2025Autoencoder (AE) is the key to the success of latent diffusion models for image and video generation, reducing the denoising resolution and improving efficiency. However, the power of AE has long been underexplored in terms of network design, compression ratio, and training strategy. In this work, we systematically examine the architecture design choices and optimize the computation distribution to obtain a series of efficient and high-compression video AEs that can decode in real time on mobile devices. We also unify the design of plain Autoencoder and image-conditioned I2V VAE, achieving multifunctionality in a single network. In addition, we find that the widely adopted discriminative losses, i.e., GAN, LPIPS, and DWT losses, provide no significant improvements when training AEs at scale. We propose a novel latent consistency loss that does not require complicated discriminator design or hyperparameter tuning, but provides stable improvements in reconstruction quality. Our AE achieves an ultra-high compression ratio and real-time decoding speed on mobile while outperforming prior art in terms of reconstruction metrics by a large margin. We finally validate our AE by training a DiT on its latent space and demonstrate fast, high-quality text-to-video generation capability.
QuartDepth: Post-Training Quantization for Real-Time Depth Estimation on the Edge
Mar 20, 2025



Monocular Depth Estimation (MDE) has emerged as a pivotal task in computer vision, supporting numerous real-world applications. However, deploying accurate depth estimation models on resource-limited edge devices, especially Application-Specific Integrated Circuits (ASICs), is challenging due to the high computational and memory demands. Recent advancements in foundational depth estimation deliver impressive results but further amplify the difficulty of deployment on ASICs. To address this, we propose QuartDepth which adopts post-training quantization to quantize MDE models with hardware accelerations for ASICs. Our approach involves quantizing both weights and activations to 4-bit precision, reducing the model size and computation cost. To mitigate the performance degradation, we introduce activation polishing and compensation algorithm applied before and after activation quantization, as well as a weight reconstruction method for minimizing errors in weight quantization. Furthermore, we design a flexible and programmable hardware accelerator by supporting kernel fusion and customized instruction programmability, enhancing throughput and efficiency. Experimental results demonstrate that our framework achieves competitive accuracy while enabling fast inference and higher energy efficiency on ASICs, bridging the gap between high-performance depth estimation and practical edge-device applicability. Code: https://github.com/shawnricecake/quart-depth
HDCompression: Hybrid-Diffusion Image Compression for Ultra-Low Bitrates
Feb 11, 2025



Image compression under ultra-low bitrates remains challenging for both conventional learned image compression (LIC) and generative vector-quantized (VQ) modeling. Conventional LIC suffers from severe artifacts due to heavy quantization, while generative VQ modeling gives poor fidelity due to the mismatch between learned generative priors and specific inputs. In this work, we propose Hybrid-Diffusion Image Compression (HDCompression), a dual-stream framework that utilizes both generative VQ-modeling and diffusion models, as well as conventional LIC, to achieve both high fidelity and high perceptual quality. Different from previous hybrid methods that directly use pre-trained LIC models to generate low-quality fidelity-preserving information from heavily quantized latent, we use diffusion models to extract high-quality complimentary fidelity information from the ground-truth input, which can enhance the system performance in several aspects: improving indices map prediction, enhancing the fidelity-preserving output of the LIC stream, and refining conditioned image reconstruction with VQ-latent correction. In addition, our diffusion model is based on a dense representative vector (DRV), which is lightweight with very simple sampling schedulers. Extensive experiments demonstrate that our HDCompression outperforms the previous conventional LIC, generative VQ-modeling, and hybrid frameworks in both quantitative metrics and qualitative visualization, providing balanced robust compression performance at ultra-low bitrates.