 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImprove Vision Language Model Chain-of-thought Reasoning
Oct 21, 2024



Chain-of-thought (CoT) reasoning in vision language models (VLMs) is crucial for improving interpretability and trustworthiness. However, current training recipes lack robust CoT reasoning data, relying on datasets dominated by short annotations with minimal rationales. In this work, we show that training VLM on short answers does not generalize well to reasoning tasks that require more detailed responses. To address this, we propose a two-fold approach. First, we distill rationales from GPT-4o model to enrich the training data and fine-tune VLMs, boosting their CoT performance. Second, we apply reinforcement learning to further calibrate reasoning quality. Specifically, we construct positive (correct) and negative (incorrect) pairs of model-generated reasoning chains, by comparing their predictions with annotated short answers. Using this pairwise data, we apply the Direct Preference Optimization algorithm to refine the model's reasoning abilities. Our experiments demonstrate significant improvements in CoT reasoning on benchmark datasets and better generalization to direct answer prediction as well. This work emphasizes the importance of incorporating detailed rationales in training and leveraging reinforcement learning to strengthen the reasoning capabilities of VLMs.
Direct Preference Optimization of Video Large Multimodal Models from Language Model Reward
Apr 02, 2024



Preference modeling techniques, such as direct preference optimization (DPO), has shown effective in enhancing the generalization abilities of large language model (LLM). However, in tasks involving video instruction-following, providing informative feedback, especially for detecting hallucinations in generated responses, remains a significant challenge. Previous studies have explored using large large multimodal models (LMMs) as reward models to guide preference modeling, but their ability to accurately assess the factuality of generated responses compared to corresponding videos has not been conclusively established. This paper introduces a novel framework that utilizes detailed video captions as a proxy of video content, enabling language models to incorporate this information as supporting evidence for scoring video Question Answering (QA) predictions. Our approach demonstrates robust alignment with OpenAI GPT-4V model's reward mechanism, which directly takes video frames as input. Furthermore, we show that applying this tailored reward through DPO significantly improves the performance of video LMMs on video QA tasks.
A Self-enhancement Approach for Domain-specific Chatbot Training via Knowledge Mining and Digest
Nov 17, 2023



Large Language Models (LLMs), despite their great power in language generation, often encounter challenges when dealing with intricate and knowledge-demanding queries in specific domains. This paper introduces a novel approach to enhance LLMs by effectively extracting the relevant knowledge from domain-specific textual sources, and the adaptive training of a chatbot with domain-specific inquiries. Our two-step approach starts from training a knowledge miner, namely LLMiner, which autonomously extracts Question-Answer pairs from relevant documents through a chain-of-thought reasoning process. Subsequently, we blend the mined QA pairs with a conversational dataset to fine-tune the LLM as a chatbot, thereby enriching its domain-specific expertise and conversational capabilities. We also developed a new evaluation benchmark which comprises four domain-specific text corpora and associated human-crafted QA pairs for testing. Our model shows remarkable performance improvement over generally aligned LLM and surpasses domain-adapted models directly fine-tuned on domain corpus. In particular, LLMiner achieves this with minimal human intervention, requiring only 600 seed instances, thereby providing a pathway towards self-improvement of LLMs through model-synthesized training data.
SOTOPIA: Interactive Evaluation for Social Intelligence in Language Agents
Oct 18, 2023



Humans are social beings; we pursue social goals in our daily interactions, which is a crucial aspect of social intelligence. Yet, AI systems' abilities in this realm remain elusive. We present SOTOPIA, an open-ended environment to simulate complex social interactions between artificial agents and evaluate their social intelligence. In our environment, agents role-play and interact under a wide variety of scenarios; they coordinate, collaborate, exchange, and compete with each other to achieve complex social goals. We simulate the role-play interaction between LLM-based agents and humans within this task space and evaluate their performance with a holistic evaluation framework called SOTOPIA-Eval. With SOTOPIA, we find significant differences between these models in terms of their social intelligence, and we identify a subset of SOTOPIA scenarios, SOTOPIA-hard, that is generally challenging for all models. We find that on this subset, GPT-4 achieves a significantly lower goal completion rate than humans and struggles to exhibit social commonsense reasoning and strategic communication skills. These findings demonstrate SOTOPIA's promise as a general platform for research on evaluating and improving social intelligence in artificial agents.
PESCO: Prompt-enhanced Self Contrastive Learning for Zero-shot Text Classification
May 24, 2023We present PESCO, a novel contrastive learning framework that substantially improves the performance of zero-shot text classification. We formulate text classification as a neural text matching problem where each document is treated as a query, and the system learns the mapping from each query to the relevant class labels by (1) adding prompts to enhance label matching, and (2) using retrieved labels to enrich the training set in a self-training loop of contrastive learning. PESCO achieves state-of-the-art performance on four benchmark text classification datasets. On DBpedia, we achieve 98.5\% accuracy without any labeled data, which is close to the fully-supervised result. Extensive experiments and analyses show all the components of PESCO are necessary for improving the performance of zero-shot text classification.
* accepted by ACL 2023
Generation-driven Contrastive Self-training for Zero-shot Text Classification with Instruction-tuned GPT
Apr 24, 2023Moreover, GPT-based zero-shot classification models tend to make independent predictions over test instances, which can be sub-optimal as the instance correlations and the decision boundaries in the target space are ignored. To address these difficulties and limitations, we propose a new approach to zero-shot text classification, namely \ourmodelshort, which leverages the strong generative power of GPT to assist in training a smaller, more adaptable, and efficient sentence encoder classifier with contrastive self-training. Specifically, GenCo applies GPT in two ways: firstly, it generates multiple augmented texts for each input instance to enhance the semantic embedding of the instance and improve the mapping to relevant labels; secondly, it generates augmented texts conditioned on the predicted label during self-training, which makes the generative process tailored to the decision boundaries in the target space. In our experiments, GenCo outperforms previous state-of-the-art methods on multiple benchmark datasets, even when only limited in-domain text data is available.
Long-tailed Extreme Multi-label Text Classification with Generated Pseudo Label Descriptions
Apr 02, 2022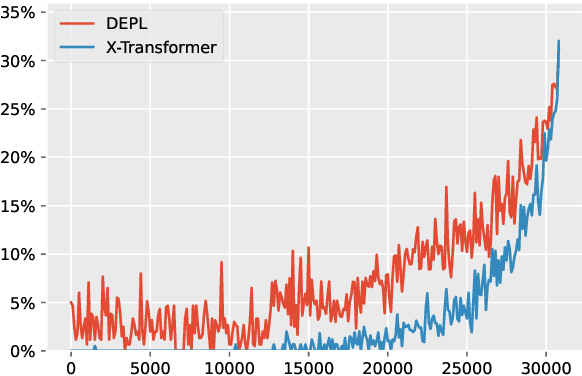
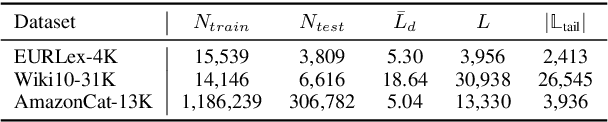
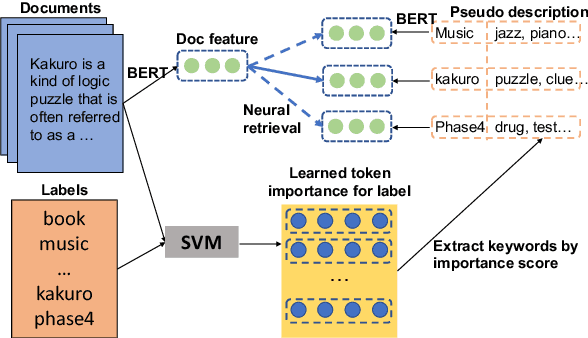
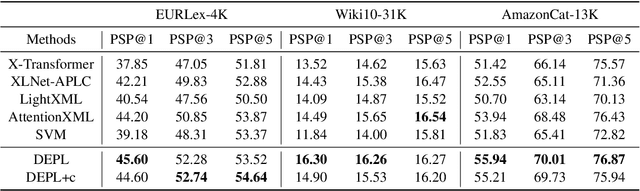
Extreme Multi-label Text Classification (XMTC) has been a tough challenge in machine learning research and applications due to the sheer sizes of the label spaces and the severe data scarce problem associated with the long tail of rare labels in highly skewed distributions. This paper addresses the challenge of tail label prediction by proposing a novel approach, which combines the effectiveness of a trained bag-of-words (BoW) classifier in generating informative label descriptions under severe data scarce conditions, and the power of neural embedding based retrieval models in mapping input documents (as queries) to relevant label descriptions. The proposed approach achieves state-of-the-art performance on XMTC benchmark datasets and significantly outperforms the best methods so far in the tail label prediction. We also provide a theoretical analysis for relating the BoW and neural models w.r.t. performance lower bound.
Exploiting Local and Global Features in Transformer-based Extreme Multi-label Text Classification
Apr 02, 2022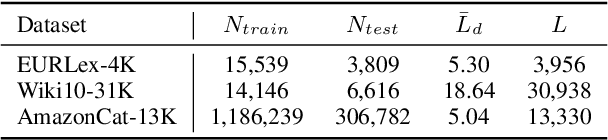
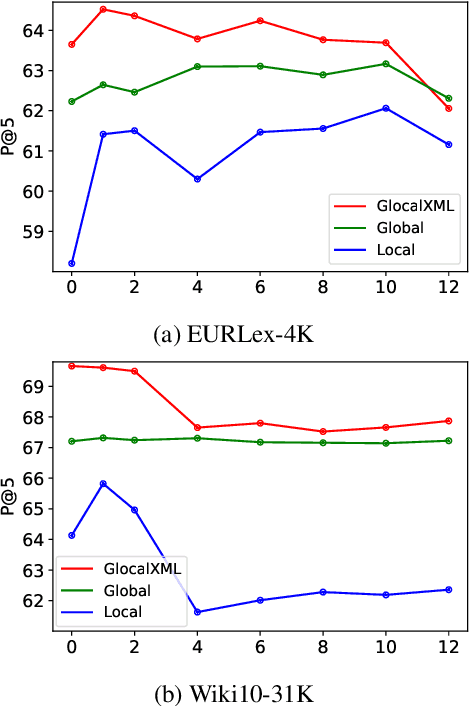
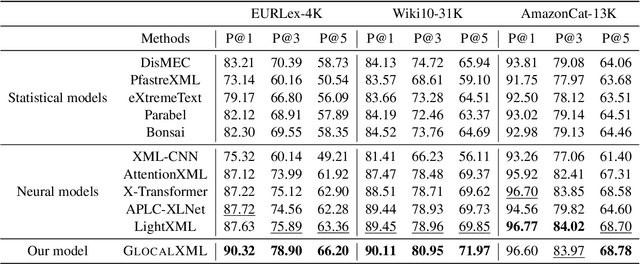
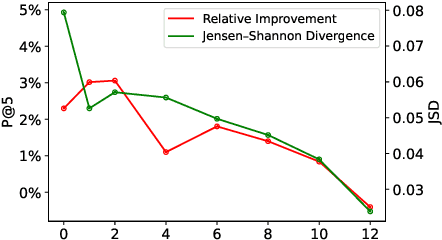
Extreme multi-label text classification (XMTC) is the task of tagging each document with the relevant labels from a very large space of predefined categories. Recently, large pre-trained Transformer models have made significant performance improvements in XMTC, which typically use the embedding of the special CLS token to represent the entire document semantics as a global feature vector, and match it against candidate labels. However, we argue that such a global feature vector may not be sufficient to represent different granularity levels of semantics in the document, and that complementing it with the local word-level features could bring additional gains. Based on this insight, we propose an approach that combines both the local and global features produced by Transformer models to improve the prediction power of the classifier. Our experiments show that the proposed model either outperforms or is comparable to the state-of-the-art methods on benchmark datasets.
Generalized Multi-Relational Graph Convolution Network
Jun 12, 2020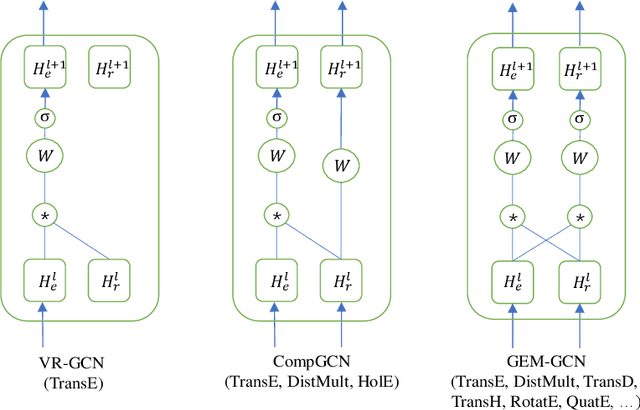
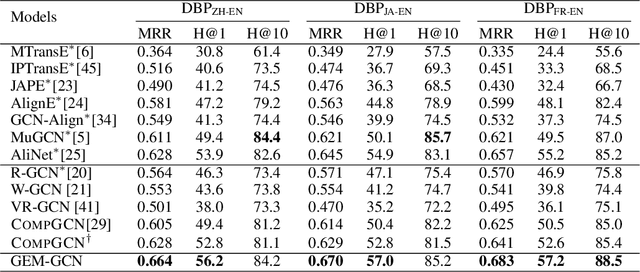
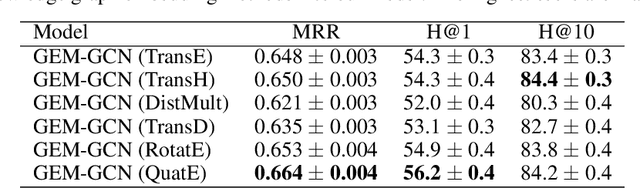

Graph Convolutional Networks (GCNs) have received increasing attention in recent machine learning. How to effectively leverage the rich structural information in complex graphs, such as knowledge graphs with heterogeneous types of entities and relations, is a primary open challenge in the field. Most GCN methods are either restricted to graphs with a homogeneous type of edges (e.g., citation links only), or focusing on representation learning for nodes only instead of jointly optimizing the embeddings of both nodes and edges for target-driven objectives. This paper addresses these limitations by proposing a novel framework, namely the GEneralized Multi-relational Graph Convolutional Networks (GEM-GCN), which combines the power of GCNs in graph-based belief propagation and the strengths of advanced knowledge-base embedding methods, and goes beyond. Our theoretical analysis shows that GEM-GCN offers an elegant unification of several well-known GCN methods as specific cases, with a new perspective of graph convolution. Experimental results on benchmark datasets show the advantageous performance of GEM-GCN over strong baseline methods in the tasks of knowledge graph alignment and entity classification.
Explainable Unsupervised Change-point Detection via Graph Neural Networks
Apr 24, 2020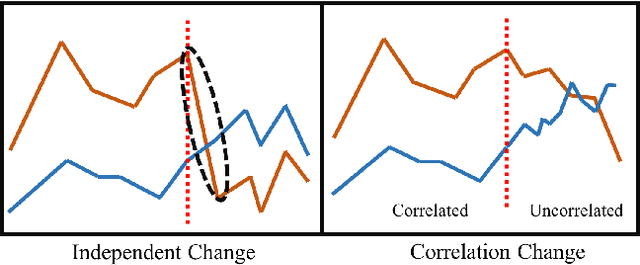
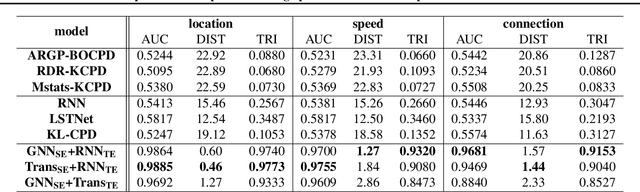
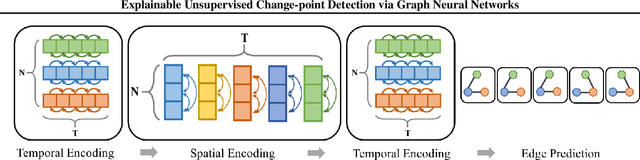
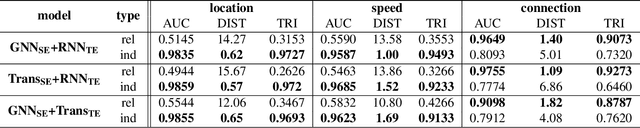
Change-point detection (CPD) aims at detecting the abrupt property changes lying behind time series data. The property changes in a multivariate time series often result from highly entangled reasons, ranging from independent changes of variables to correlation changes between variables. Learning to uncover the reasons behind the changes in an unsupervised setting is a new and challenging task. Previous CPD methods usually detect change-points by a divergence estimation of statistical features, without delving into the reasons behind the detected changes. In this paper, we propose a correlation-aware dynamics model which separately predicts the correlation change and independent change by incorporating graph neural networks into the encoder-decoder framework. Through experiments on synthetic and real-world datasets, we demonstrate the enhanced performance of our model on the CPD tasks as well as its ability to interpret the nature and degree of the predicted changes.