 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeToward Robust LLM-Based Judges: Taxonomic Bias Evaluation and Debiasing Optimization
Mar 09, 2026Large language model (LLM)-based judges are widely adopted for automated evaluation and reward modeling, yet their judgments are often affected by judgment biases. Accurately evaluating these biases is essential for ensuring the reliability of LLM-based judges. However, existing studies typically investigate limited biases under a single judge formulation, either generative or discriminative, lacking a comprehensive evaluation. To bridge this gap, we propose JudgeBiasBench, a benchmark for systematically quantifying biases in LLM-based judges. JudgeBiasBench defines a taxonomy of judgment biases across 4 dimensions, and constructs bias-augmented evaluation instances through a controlled bias injection pipeline, covering 12 representative bias types. We conduct extensive experiments across both generative and discriminative judges, revealing that current judges exhibit significant and diverse bias patterns that often compromise the reliability of automated evaluation. To mitigate judgment bias, we propose bias-aware training that explicitly incorporates bias-related attributes into the training process, encouraging judges to disentangle task-relevant quality from bias-correlated cues. By adopting reinforcement learning for generative judges and contrastive learning for discriminative judges, our methods effectively reduce judgment biases while largely preserving general evaluation capability.
RM-Distiller: Exploiting Generative LLM for Reward Model Distillation
Jan 20, 2026Reward models (RMs) play a pivotal role in aligning large language models (LLMs) with human preferences. Due to the difficulty of obtaining high-quality human preference annotations, distilling preferences from generative LLMs has emerged as a standard practice. However, existing approaches predominantly treat teacher models as simple binary annotators, failing to fully exploit the rich knowledge and capabilities for RM distillation. To address this, we propose RM-Distiller, a framework designed to systematically exploit the multifaceted capabilities of teacher LLMs: (1) Refinement capability, which synthesizes highly correlated response pairs to create fine-grained and contrastive signals. (2) Scoring capability, which guides the RM in capturing precise preference strength via a margin-aware optimization objective. (3) Generation capability, which incorporates the teacher's generative distribution to regularize the RM to preserve its fundamental linguistic knowledge. Extensive experiments demonstrate that RM-Distiller significantly outperforms traditional distillation methods both on RM benchmarks and reinforcement learning-based alignment, proving that exploiting multifaceted teacher capabilities is critical for effective reward modeling. To the best of our knowledge, this is the first systematic research on RM distillation from generative LLMs.
Lost in Benchmarks? Rethinking Large Language Model Benchmarking with Item Response Theory
May 21, 2025
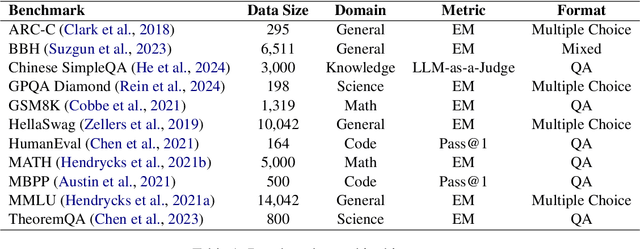
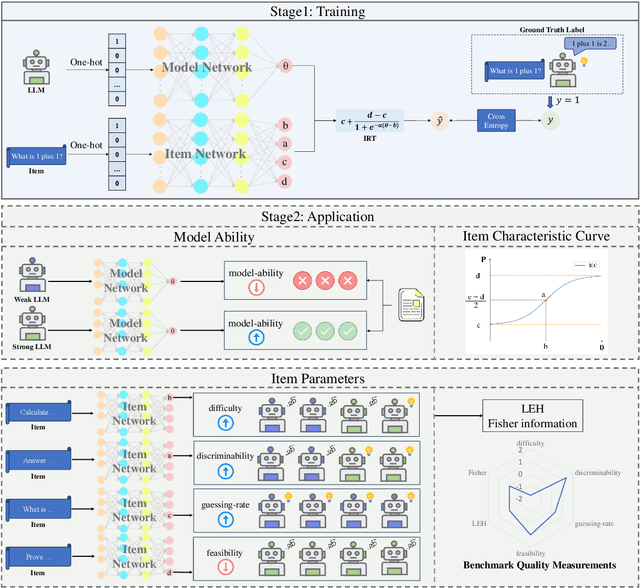

The evaluation of large language models (LLMs) via benchmarks is widespread, yet inconsistencies between different leaderboards and poor separability among top models raise concerns about their ability to accurately reflect authentic model capabilities. This paper provides a critical analysis of benchmark effectiveness, examining main-stream prominent LLM benchmarks using results from diverse models. We first propose a new framework for accurate and reliable estimations of item characteristics and model abilities. Specifically, we propose Pseudo-Siamese Network for Item Response Theory (PSN-IRT), an enhanced Item Response Theory framework that incorporates a rich set of item parameters within an IRT-grounded architecture. Based on PSN-IRT, we conduct extensive analysis which reveals significant and varied shortcomings in the measurement quality of current benchmarks. Furthermore, we demonstrate that leveraging PSN-IRT is able to construct smaller benchmarks while maintaining stronger alignment with human preference.
Think-J: Learning to Think for Generative LLM-as-a-Judge
May 20, 2025



LLM-as-a-Judge refers to the automatic modeling of preferences for responses generated by Large Language Models (LLMs), which is of significant importance for both LLM evaluation and reward modeling. Although generative LLMs have made substantial progress in various tasks, their performance as LLM-Judge still falls short of expectations. In this work, we propose Think-J, which improves generative LLM-as-a-Judge by learning how to think. We first utilized a small amount of curated data to develop the model with initial judgment thinking capabilities. Subsequently, we optimize the judgment thinking traces based on reinforcement learning (RL). We propose two methods for judgment thinking optimization, based on offline and online RL, respectively. The offline RL requires training a critic model to construct positive and negative examples for learning. The online method defines rule-based reward as feedback for optimization. Experimental results showed that our approach can significantly enhance the evaluation capability of generative LLM-Judge, surpassing both generative and classifier-based LLM-Judge without requiring extra human annotations.
Mitigating the Bias of Large Language Model Evaluation
Sep 25, 2024



Recently, there has been a trend of evaluating the Large Language Model (LLM) quality in the flavor of LLM-as-a-Judge, namely leveraging another LLM to evaluate the current output quality. However, existing judges are proven to be biased, namely they would favor answers which present better superficial quality (such as verbosity, fluency) while ignoring the instruction following ability. In this work, we propose systematic research about the bias of LLM-as-a-Judge. Specifically, for closed-source judge models, we apply calibration to mitigate the significance of superficial quality, both on probability level and prompt level. For open-source judge models, we propose to mitigate the bias by contrastive training, with curated negative samples that deviate from instruction but present better superficial quality. We apply our methods on the bias evaluation benchmark, and experiment results show our methods mitigate the bias by a large margin while maintaining a satisfactory evaluation accuracy.