 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMemory in the Age of AI Agents
Dec 15, 2025Memory has emerged, and will continue to remain, a core capability of foundation model-based agents. As research on agent memory rapidly expands and attracts unprecedented attention, the field has also become increasingly fragmented. Existing works that fall under the umbrella of agent memory often differ substantially in their motivations, implementations, and evaluation protocols, while the proliferation of loosely defined memory terminologies has further obscured conceptual clarity. Traditional taxonomies such as long/short-term memory have proven insufficient to capture the diversity of contemporary agent memory systems. This work aims to provide an up-to-date landscape of current agent memory research. We begin by clearly delineating the scope of agent memory and distinguishing it from related concepts such as LLM memory, retrieval augmented generation (RAG), and context engineering. We then examine agent memory through the unified lenses of forms, functions, and dynamics. From the perspective of forms, we identify three dominant realizations of agent memory, namely token-level, parametric, and latent memory. From the perspective of functions, we propose a finer-grained taxonomy that distinguishes factual, experiential, and working memory. From the perspective of dynamics, we analyze how memory is formed, evolved, and retrieved over time. To support practical development, we compile a comprehensive summary of memory benchmarks and open-source frameworks. Beyond consolidation, we articulate a forward-looking perspective on emerging research frontiers, including memory automation, reinforcement learning integration, multimodal memory, multi-agent memory, and trustworthiness issues. We hope this survey serves not only as a reference for existing work, but also as a conceptual foundation for rethinking memory as a first-class primitive in the design of future agentic intelligence.
Synergizing Code Coverage and Gameplay Intent: Coverage-Aware Game Playtesting with LLM-Guided Reinforcement Learning
Dec 14, 2025The widespread adoption of the "Games as a Service" model necessitates frequent content updates, placing immense pressure on quality assurance. In response, automated game testing has been viewed as a promising solution to cope with this demanding release cadence. However, existing automated testing approaches typically create a dichotomy: code-centric methods focus on structural coverage without understanding gameplay context, while player-centric agents validate high-level intent but often fail to cover specific underlying code changes. To bridge this gap, we propose SMART (Structural Mapping for Augmented Reinforcement Testing), a novel framework that synergizes structural verification and functional validation for game update testing. SMART leverages large language models (LLMs) to interpret abstract syntax tree (AST) differences and extract functional intent, constructing a context-aware hybrid reward mechanism. This mechanism guides reinforcement learning agents to sequentially fulfill gameplay goals while adaptively exploring modified code branches. We evaluate SMART on two environments, Overcooked and Minecraft. The results demonstrate that SMART significantly outperforms state-of-the-art baselines; it achieves over 94% branch coverage of modified code, nearly double that of traditional reinforcement learning methods, while maintaining a 98% task completion rate, effectively balancing structural comprehensiveness with functional correctness.
Geometry-Aware Scene-Consistent Image Generation
Dec 14, 2025We study geometry-aware scene-consistent image generation: given a reference scene image and a text condition specifying an entity to be generated in the scene and its spatial relation to the scene, the goal is to synthesize an output image that preserves the same physical environment as the reference scene while correctly generating the entity according to the spatial relation described in the text. Existing methods struggle to balance scene preservation with prompt adherence: they either replicate the scene with high fidelity but poor responsiveness to the prompt, or prioritize prompt compliance at the expense of scene consistency. To resolve this trade-off, we introduce two key contributions: (i) a scene-consistent data construction pipeline that generates diverse, geometrically-grounded training pairs, and (ii) a novel geometry-guided attention loss that leverages cross-view cues to regularize the model's spatial reasoning. Experiments on our scene-consistent benchmark show that our approach achieves better scene alignment and text-image consistency than state-of-the-art baselines, according to both automatic metrics and human preference studies. Our method produces geometrically coherent images with diverse compositions that remain faithful to the textual instructions and the underlying scene structure.
Reframing Music-Driven 2D Dance Pose Generation as Multi-Channel Image Generation
Dec 12, 2025Recent pose-to-video models can translate 2D pose sequences into photorealistic, identity-preserving dance videos, so the key challenge is to generate temporally coherent, rhythm-aligned 2D poses from music, especially under complex, high-variance in-the-wild distributions. We address this by reframing music-to-dance generation as a music-token-conditioned multi-channel image synthesis problem: 2D pose sequences are encoded as one-hot images, compressed by a pretrained image VAE, and modeled with a DiT-style backbone, allowing us to inherit architectural and training advances from modern text-to-image models and better capture high-variance 2D pose distributions. On top of this formulation, we introduce (i) a time-shared temporal indexing scheme that explicitly synchronizes music tokens and pose latents over time and (ii) a reference-pose conditioning strategy that preserves subject-specific body proportions and on-screen scale while enabling long-horizon segment-and-stitch generation. Experiments on a large in-the-wild 2D dance corpus and the calibrated AIST++2D benchmark show consistent improvements over representative music-to-dance methods in pose- and video-space metrics and human preference, and ablations validate the contributions of the representation, temporal indexing, and reference conditioning. See supplementary videos at https://hot-dance.github.io
Blockage-aware Hierarchical Codebook Design for RIS-Assisted Movable Antenna Systems
Nov 14, 2025In this paper, we propose a novel blockage-aware hierarchical beamforming framework for movable antenna (MA) systems operating at millimeter-wave (mm-Wave) frequencies. While existing works on MA systems have demonstrated performance gains over conventional systems, they often neglect the design of specialized codebooks to leverage MA's unique capabilities and address the challenges of increased energy consumption and latency inherent to MA systems. To address these aspects, we first integrate blockage detection into the codebook design process based on the Gerchberg-Saxton (GS) algorithm, significantly reducing inefficiencies due to beam evaluations done in blocked directions. Then, we use a two-stage approach to reduce the complexity of the joint beamforming and Reconfigurable Intelligent Surfaces (RIS) optimization problem. The simulations demonstrate that the proposed adaptive codebook successfully improves the Energy Efficiency (EE) and reduces the beam training overhead, substantially boosting the practical deployment potential of RIS-assisted MA systems in future wireless networks.
ScaleADFG: Affordance-based Dexterous Functional Grasping via Scalable Dataset
Nov 12, 2025Dexterous functional tool-use grasping is essential for effective robotic manipulation of tools. However, existing approaches face significant challenges in efficiently constructing large-scale datasets and ensuring generalizability to everyday object scales. These issues primarily arise from size mismatches between robotic and human hands, and the diversity in real-world object scales. To address these limitations, we propose the ScaleADFG framework, which consists of a fully automated dataset construction pipeline and a lightweight grasp generation network. Our dataset introduce an affordance-based algorithm to synthesize diverse tool-use grasp configurations without expert demonstrations, allowing flexible object-hand size ratios and enabling large robotic hands (compared to human hands) to grasp everyday objects effectively. Additionally, we leverage pre-trained models to generate extensive 3D assets and facilitate efficient retrieval of object affordances. Our dataset comprising five object categories, each containing over 1,000 unique shapes with 15 scale variations. After filtering, the dataset includes over 60,000 grasps for each 2 dexterous robotic hands. On top of this dataset, we train a lightweight, single-stage grasp generation network with a notably simple loss design, eliminating the need for post-refinement. This demonstrates the critical importance of large-scale datasets and multi-scale object variant for effective training. Extensive experiments in simulation and on real robot confirm that the ScaleADFG framework exhibits strong adaptability to objects of varying scales, enhancing functional grasp stability, diversity, and generalizability. Moreover, our network exhibits effective zero-shot transfer to real-world objects. Project page is available at https://sizhe-wang.github.io/ScaleADFG_webpage
Knowing or Guessing? Robust Medical Visual Question Answering via Joint Consistency and Contrastive Learning
Aug 26, 2025In high-stakes medical applications, consistent answering across diverse question phrasings is essential for reliable diagnosis. However, we reveal that current Medical Vision-Language Models (Med-VLMs) exhibit concerning fragility in Medical Visual Question Answering, as their answers fluctuate significantly when faced with semantically equivalent rephrasings of medical questions. We attribute this to two limitations: (1) insufficient alignment of medical concepts, leading to divergent reasoning patterns, and (2) hidden biases in training data that prioritize syntactic shortcuts over semantic understanding. To address these challenges, we construct RoMed, a dataset built upon original VQA datasets containing 144k questions with variations spanning word-level, sentence-level, and semantic-level perturbations. When evaluating state-of-the-art (SOTA) models like LLaVA-Med on RoMed, we observe alarming performance drops (e.g., a 40\% decline in Recall) compared to original VQA benchmarks, exposing critical robustness gaps. To bridge this gap, we propose Consistency and Contrastive Learning (CCL), which integrates two key components: (1) knowledge-anchored consistency learning, aligning Med-VLMs with medical knowledge rather than shallow feature patterns, and (2) bias-aware contrastive learning, mitigating data-specific priors through discriminative representation refinement. CCL achieves SOTA performance on three popular VQA benchmarks and notably improves answer consistency by 50\% on the challenging RoMed test set, demonstrating significantly enhanced robustness. Code will be released.
SCOUT: Semi-supervised Camouflaged Object Detection by Utilizing Text and Adaptive Data Selection
Aug 25, 2025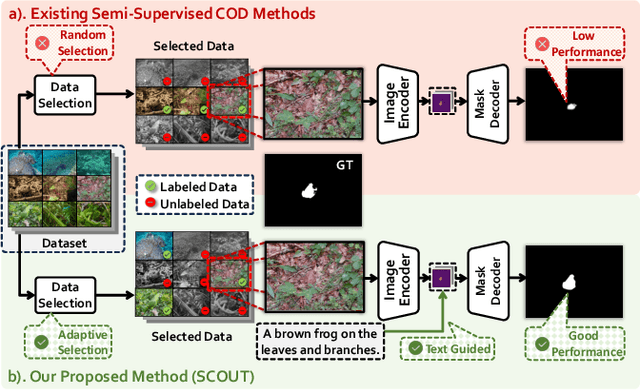

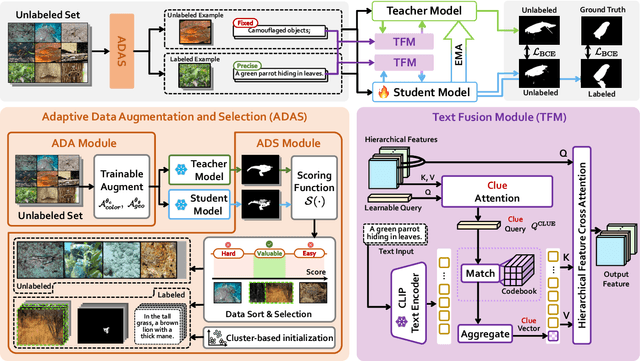

The difficulty of pixel-level annotation has significantly hindered the development of the Camouflaged Object Detection (COD) field. To save on annotation costs, previous works leverage the semi-supervised COD framework that relies on a small number of labeled data and a large volume of unlabeled data. We argue that there is still significant room for improvement in the effective utilization of unlabeled data. To this end, we introduce a Semi-supervised Camouflaged Object Detection by Utilizing Text and Adaptive Data Selection (SCOUT). It includes an Adaptive Data Augment and Selection (ADAS) module and a Text Fusion Module (TFM). The ADSA module selects valuable data for annotation through an adversarial augment and sampling strategy. The TFM module further leverages the selected valuable data by combining camouflage-related knowledge and text-visual interaction. To adapt to this work, we build a new dataset, namely RefTextCOD. Extensive experiments show that the proposed method surpasses previous semi-supervised methods in the COD field and achieves state-of-the-art performance. Our code will be released at https://github.com/Heartfirey/SCOUT.
Gather and Trace: Rethinking Video TextVQA from an Instance-oriented Perspective
Aug 06, 2025Video text-based visual question answering (Video TextVQA) aims to answer questions by explicitly reading and reasoning about the text involved in a video. Most works in this field follow a frame-level framework which suffers from redundant text entities and implicit relation modeling, resulting in limitations in both accuracy and efficiency. In this paper, we rethink the Video TextVQA task from an instance-oriented perspective and propose a novel model termed GAT (Gather and Trace). First, to obtain accurate reading result for each video text instance, a context-aggregated instance gathering module is designed to integrate the visual appearance, layout characteristics, and textual contents of the related entities into a unified textual representation. Then, to capture dynamic evolution of text in the video flow, an instance-focused trajectory tracing module is utilized to establish spatio-temporal relationships between instances and infer the final answer. Extensive experiments on several public Video TextVQA datasets validate the effectiveness and generalization of our framework. GAT outperforms existing Video TextVQA methods, video-language pretraining methods, and video large language models in both accuracy and inference speed. Notably, GAT surpasses the previous state-of-the-art Video TextVQA methods by 3.86\% in accuracy and achieves ten times of faster inference speed than video large language models. The source code is available at https://github.com/zhangyan-ucas/GAT.
MVAR: MultiVariate AutoRegressive Air Pollutants Forecasting Model
Jul 16, 2025Air pollutants pose a significant threat to the environment and human health, thus forecasting accurate pollutant concentrations is essential for pollution warnings and policy-making. Existing studies predominantly focus on single-pollutant forecasting, neglecting the interactions among different pollutants and their diverse spatial responses. To address the practical needs of forecasting multivariate air pollutants, we propose MultiVariate AutoRegressive air pollutants forecasting model (MVAR), which reduces the dependency on long-time-window inputs and boosts the data utilization efficiency. We also design the Multivariate Autoregressive Training Paradigm, enabling MVAR to achieve 120-hour long-term sequential forecasting. Additionally, MVAR develops Meteorological Coupled Spatial Transformer block, enabling the flexible coupling of AI-based meteorological forecasts while learning the interactions among pollutants and their diverse spatial responses. As for the lack of standardized datasets in air pollutants forecasting, we construct a comprehensive dataset covering 6 major pollutants across 75 cities in North China from 2018 to 2023, including ERA5 reanalysis data and FuXi-2.0 forecast data. Experimental results demonstrate that the proposed model outperforms state-of-the-art methods and validate the effectiveness of the proposed architecture.