 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSSR: Scaling Surefooted and Symmetric Humanoid Traversal to the Open World
May 29, 2026Extending humanoid traversal to the open world is key to practical deployment in human environments, but remains challenging. The robot must use vision to ensure safe and reliable foot placement on heterogeneous terrain under highly dynamic motion, while producing coordinated, natural whole-body behaviors. We propose SSR, an efficient end-to-end framework for egocentric vision-based humanoid traversal that jointly learns these capabilities. SSR introduces imagined foothold guidance, which learns to model forthcoming swing-foot contacts and evaluates their support to guide pre-touchdown swings toward stable regions, reducing edge slips. It further employs equivariant latent-space symmetry augmentation to efficiently induce bilateral coordination under high-dimensional visual observations, and uses terrain-specific multi-discriminator motion priors to encourage human-like behavior across scenes. Extensive experiments show that SSR achieves safe, stable, and high-quality locomotion on diverse real-world terrains, including stairs with varied structures and extreme challenges such as wide gaps and high platforms, while enabling reliable long-horizon traversal in open outdoor environments.
CAMotion: A High-Quality Benchmark for Camouflaged Moving Object Detection in the Wild
Apr 09, 2026Discovering camouflaged objects is a challenging task in computer vision due to the high similarity between camouflaged objects and their surroundings. While the problem of camouflaged object detection over sequential video frames has received increasing attention, the scale and diversity of existing video camouflaged object detection (VCOD) datasets are greatly limited, which hinders the deeper analysis and broader evaluation of recent deep learning-based algorithms with data-hungry training strategy. To break this bottleneck, in this paper, we construct CAMotion, a high-quality benchmark covers a wide range of species for camouflaged moving object detection in the wild. CAMotion comprises various sequences with multiple challenging attributes such as uncertain edge, occlusion, motion blur, and shape complexity, etc. The sequence annotation details and statistical distribution are presented from various perspectives, allowing CAMotion to provide in-depth analyses on the camouflaged object's motion characteristics in different challenging scenarios. Additionally, we conduct a comprehensive evaluation of existing SOTA models on CAMotion, and discuss the major challenges in VCOD task. The benchmark is available at https://www.camotion.focuslab.net.cn, we hope that our CAMotion can lead to further advancements in the research community.
CReF: Cross-modal and Recurrent Fusion for Depth-conditioned Humanoid Locomotion
Apr 01, 2026Stable traversal over geometrically complex terrain increasingly requires exteroceptive perception, yet prior perceptive humanoid locomotion methods often remain tied to explicit geometric abstractions, either by mediating control through robot-centric 2.5D terrain representations or by shaping depth learning with auxiliary geometry-related targets. Such designs inherit the representational bias of the intermediate or supervisory target and can be restrictive for vertical structures, perforated obstacles, and complex real-world clutter. We propose CReF (Cross-modal and Recurrent Fusion), a single-stage depth-conditioned humanoid locomotion framework that learns locomotion-relevant features directly from raw forward-facing depth without explicit geometric intermediates. CReF couples proprioception and depth tokens through proprioception-queried cross-modal attention, fuses the resulting representation with a gated residual fusion block, and performs temporal integration with a Gated Recurrent Unit (GRU) regulated by a highway-style output gate for state-dependent blending of recurrent and feedforward features. To further improve terrain interaction, we introduce a terrain-aware foothold placement reward that extracts supportable foothold candidates from foot-end point-cloud samples and rewards touchdown locations that lie close to the nearest supportable candidate. Experiments in simulation and on a physical humanoid demonstrate robust traversal over diverse terrains and effective zero-shot transfer to real-world scenes containing handrails, hollow pallet assemblies, severe reflective interference, and visually cluttered outdoor surroundings.
SketchAssist: A Practical Assistant for Semantic Edits and Precise Local Redrawing
Dec 16, 2025



Sketch editing is central to digital illustration, yet existing image editing systems struggle to preserve the sparse, style-sensitive structure of line art while supporting both high-level semantic changes and precise local redrawing. We present SketchAssist, an interactive sketch drawing assistant that accelerates creation by unifying instruction-guided global edits with line-guided region redrawing, while keeping unrelated regions and overall composition intact. To enable this assistant at scale, we introduce a controllable data generation pipeline that (i) constructs attribute-addition sequences from attribute-free base sketches, (ii) forms multi-step edit chains via cross-sequence sampling, and (iii) expands stylistic coverage with a style-preserving attribute-removal model applied to diverse sketches. Building on this data, SketchAssist employs a unified sketch editing framework with minimal changes to DiT-based editors. We repurpose the RGB channels to encode the inputs, enabling seamless switching between instruction-guided edits and line-guided redrawing within a single input interface. To further specialize behavior across modes, we integrate a task-guided mixture-of-experts into LoRA layers, routing by text and visual cues to improve semantic controllability, structural fidelity, and style preservation. Extensive experiments show state-of-the-art results on both tasks, with superior instruction adherence and style/structure preservation compared to recent baselines. Together, our dataset and SketchAssist provide a practical, controllable assistant for sketch creation and revision.
START: Traversing Sparse Footholds with Terrain Reconstruction
Dec 15, 2025


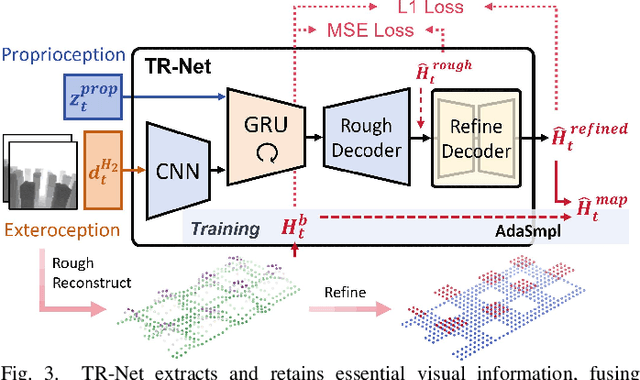
Traversing terrains with sparse footholds like legged animals presents a promising yet challenging task for quadruped robots, as it requires precise environmental perception and agile control to secure safe foot placement while maintaining dynamic stability. Model-based hierarchical controllers excel in laboratory settings, but suffer from limited generalization and overly conservative behaviors. End-to-end learning-based approaches unlock greater flexibility and adaptability, but existing state-of-the-art methods either rely on heightmaps that introduce noise and complex, costly pipelines, or implicitly infer terrain features from egocentric depth images, often missing accurate critical geometric cues and leading to inefficient learning and rigid gaits. To overcome these limitations, we propose START, a single-stage learning framework that enables agile, stable locomotion on highly sparse and randomized footholds. START leverages only low-cost onboard vision and proprioception to accurately reconstruct local terrain heightmap, providing an explicit intermediate representation to convey essential features relevant to sparse foothold regions. This supports comprehensive environmental understanding and precise terrain assessment, reducing exploration cost and accelerating skill acquisition. Experimental results demonstrate that START achieves zero-shot transfer across diverse real-world scenarios, showcasing superior adaptability, precise foothold placement, and robust locomotion.
Reframing Music-Driven 2D Dance Pose Generation as Multi-Channel Image Generation
Dec 12, 2025Recent pose-to-video models can translate 2D pose sequences into photorealistic, identity-preserving dance videos, so the key challenge is to generate temporally coherent, rhythm-aligned 2D poses from music, especially under complex, high-variance in-the-wild distributions. We address this by reframing music-to-dance generation as a music-token-conditioned multi-channel image synthesis problem: 2D pose sequences are encoded as one-hot images, compressed by a pretrained image VAE, and modeled with a DiT-style backbone, allowing us to inherit architectural and training advances from modern text-to-image models and better capture high-variance 2D pose distributions. On top of this formulation, we introduce (i) a time-shared temporal indexing scheme that explicitly synchronizes music tokens and pose latents over time and (ii) a reference-pose conditioning strategy that preserves subject-specific body proportions and on-screen scale while enabling long-horizon segment-and-stitch generation. Experiments on a large in-the-wild 2D dance corpus and the calibrated AIST++2D benchmark show consistent improvements over representative music-to-dance methods in pose- and video-space metrics and human preference, and ablations validate the contributions of the representation, temporal indexing, and reference conditioning. See supplementary videos at https://hot-dance.github.io
SerialGen: Personalized Image Generation by First Standardization Then Personalization
Dec 02, 2024



In this work, we are interested in achieving both high text controllability and overall appearance consistency in the generation of personalized human characters. We propose a novel framework, named SerialGen, which is a serial generation method consisting of two stages: first, a standardization stage that standardizes reference images, and then a personalized generation stage based on the standardized reference. Furthermore, we introduce two modules aimed at enhancing the standardization process. Our experimental results validate the proposed framework's ability to produce personalized images that faithfully recover the reference image's overall appearance while accurately responding to a wide range of text prompts. Through thorough analysis, we highlight the critical contribution of the proposed serial generation method and standardization model, evidencing enhancements in appearance consistency between reference and output images and across serial outputs generated from diverse text prompts. The term "Serial" in this work carries a double meaning: it refers to the two-stage method and also underlines our ability to generate serial images with consistent appearance throughout.
PIE: Parkour with Implicit-Explicit Learning Framework for Legged Robots
Aug 27, 2024



Parkour presents a highly challenging task for legged robots, requiring them to traverse various terrains with agile and smooth locomotion. This necessitates comprehensive understanding of both the robot's own state and the surrounding terrain, despite the inherent unreliability of robot perception and actuation. Current state-of-the-art methods either rely on complex pre-trained high-level terrain reconstruction modules or limit the maximum potential of robot parkour to avoid failure due to inaccurate perception. In this paper, we propose a one-stage end-to-end learning-based parkour framework: Parkour with Implicit-Explicit learning framework for legged robots (PIE) that leverages dual-level implicit-explicit estimation. With this mechanism, even a low-cost quadruped robot equipped with an unreliable egocentric depth camera can achieve exceptional performance on challenging parkour terrains using a relatively simple training process and reward function. While the training process is conducted entirely in simulation, our real-world validation demonstrates successful zero-shot deployment of our framework, showcasing superior parkour performance on harsh terrains.
Toward Understanding Key Estimation in Learning Robust Humanoid Locomotion
Mar 09, 2024Accurate state estimation plays a critical role in ensuring the robust control of humanoid robots, particularly in the context of learning-based control policies for legged robots. However, there is a notable gap in analytical research concerning estimations. Therefore, we endeavor to further understand how various types of estimations influence the decision-making processes of policies. In this paper, we provide quantitative insight into the effectiveness of learned state estimations, employing saliency analysis to identify key estimation variables and optimize their combination for humanoid locomotion tasks. Evaluations assessing tracking precision and robustness are conducted on comparative groups of policies with varying estimation combinations in both simulated and real-world environments. Results validated that the proposed policy is capable of crossing the sim-to-real gap and demonstrating superior performance relative to alternative policy configurations.
Hunting imaging biomarkers in pulmonary fibrosis: Benchmarks of the AIIB23 challenge
Dec 21, 2023



Airway-related quantitative imaging biomarkers are crucial for examination, diagnosis, and prognosis in pulmonary diseases. However, the manual delineation of airway trees remains prohibitively time-consuming. While significant efforts have been made towards enhancing airway modelling, current public-available datasets concentrate on lung diseases with moderate morphological variations. The intricate honeycombing patterns present in the lung tissues of fibrotic lung disease patients exacerbate the challenges, often leading to various prediction errors. To address this issue, the 'Airway-Informed Quantitative CT Imaging Biomarker for Fibrotic Lung Disease 2023' (AIIB23) competition was organized in conjunction with the official 2023 International Conference on Medical Image Computing and Computer Assisted Intervention (MICCAI). The airway structures were meticulously annotated by three experienced radiologists. Competitors were encouraged to develop automatic airway segmentation models with high robustness and generalization abilities, followed by exploring the most correlated QIB of mortality prediction. A training set of 120 high-resolution computerised tomography (HRCT) scans were publicly released with expert annotations and mortality status. The online validation set incorporated 52 HRCT scans from patients with fibrotic lung disease and the offline test set included 140 cases from fibrosis and COVID-19 patients. The results have shown that the capacity of extracting airway trees from patients with fibrotic lung disease could be enhanced by introducing voxel-wise weighted general union loss and continuity loss. In addition to the competitive image biomarkers for prognosis, a strong airway-derived biomarker (Hazard ratio>1.5, p<0.0001) was revealed for survival prognostication compared with existing clinical measurements, clinician assessment and AI-based biomarkers.