 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeM$^2$E-UAV: A Benchmark and Analysis for Onboard Motion-on-Motion Event-Based Tiny UAV Detection
May 11, 2026Tiny UAV detection from an onboard event camera is difficult when the observer and target move at the same time. In this motion-on-motion regime, ego-motion activates background edges across buildings, vegetation, and horizon structures, while the UAV may appear as a sparse event cluster. To explore this practical problem, we present M$^2$E-UAV, a benchmark and analysis setup for onboard motion-on-motion event-based tiny UAV detection. The processed M$^2$E-UAV benchmark contains 87,223 training samples and 21,395 validation samples across four scene families: sunny building-forest, sunny farm-village, sunset building-forest, and sunset farm-village. We provide M$^2$E-Point, a point-based event baseline, and M$^2$E-Point + IMU, an IMU-conditioned variant, to analyze the role of inertial cues under onboard motion-on-motion detection. M$^2$E-Point encodes events as $[x,y,t,p]$ point sets, extracts local event structure with EdgeConv, and predicts event-level UAV foreground scores, from which bounding boxes are derived via DBSCAN. Our validation-stage analysis shows that point-based event modeling is a strong baseline, while simple IMU conditioning provides only marginal aggregate gains. Under the train/validation split, M$^2$E-Point achieves 0.9673 F1 and 0.5501 mAP50-95, while the IMU-conditioned variant reaches 0.5561 mAP50-95 with only marginal aggregate changes, serving as an initial baseline for future exploration in this domain. Code will be ready in https://github.com/Wickyan/M2E-UAV.
COREY: A Prototype Study of Entropy-Guided Operator Fusion with Hadamard Reparameterization for Selective State Space Models
Apr 12, 2026State Space Models (SSMs), represented by the Mamba family, provide linear-time sequence modeling and are attractive for long-context inference. Yet practical deployments remain memory-bandwidth limited because selective state updates are often decomposed into fragmented kernels with repeated intermediate tensor materialization. We present COREY, a prototype framework that combines memory-aware operator fusion with Hadamard-based feature reparameterization. Activation entropy, estimated with fixed-width histograms, is used as a runtime scheduling statistic to place fusion boundaries and choose tile sizes. To regularize heavy-tailed activations, we absorb normalized Hadamard transforms into linear projections, preserving functional equivalence while reducing peak-coordinate concentration. In a controlled prototype study over heavy-tailed SSM activations, COREY consistently reduces proxy latency, improves throughput, and lowers DRAM traffic relative to unfused and fixed-depth baselines. Low-bit results are reported only through a hand-crafted stability proxy and are intended as diagnostic evidence rather than checkpoint-level quality claims. Code repository: https://github.com/mabo1215/COREY_Transformer.git.
BodhiPromptShield: Pre-Inference Prompt Mediation for Suppressing Privacy Propagation in LLM/VLM Agents
Apr 07, 2026In LLM/VLM agents, prompt privacy risk propagates beyond a single model call because raw user content can flow into retrieval queries, memory writes, tool calls, and logs. Existing de-identification pipelines address document boundaries but not this cross-stage propagation. We propose BodhiPromptShield, a policy-aware framework that detects sensitive spans, routes them via typed placeholders, semantic abstraction, or secure symbolic mapping, and delays restoration to authorized boundaries. Relative to enterprise redaction, this adds explicit propagation-aware mediation and restoration timing as a security variable. Under controlled evaluation on the Controlled Prompt-Privacy Benchmark (CPPB), stage-wise propagation suppresses from 10.7\% to 7.1\% across retrieval, memory, and tool stages; PER reaches 9.3\% with 0.94 AC and 0.92 TSR, outperforming generic de-identification. These are controlled systems results on CPPB rather than formal privacy guarantees or public-benchmark transfer claims. The project repository is available at https://github.com/mabo1215/BodhiPromptShield.git.
CT-to-X-ray Distillation Under Tiny Paired Cohorts: An Evidence-Bounded Reproducible Pilot Study
Mar 31, 2026Chest X-ray and computed tomography (CT) provide complementary views of thoracic disease, yet most computer-aided diagnosis models are trained and deployed within a single imaging modality. The concrete question studied here is narrower and deployment-oriented: on a patient-level paired chest cohort, can CT act as training-only supervision for a binary disease versus non-disease X-ray classifier without requiring CT at inference time? We study this setting as a cross-modality teacher--student distillation problem and use JDCNet as an executable pilot scaffold rather than as a validated superior architecture. On the original patient-level paired split from a public paired chest imaging cohort, a stripped-down plain cross-modal logit-KD control attains the highest mean result on the four-image validation subset (0.875 accuracy and 0.714 macro-F1), whereas the full module-augmented JDCNet variant remains at 0.750 accuracy and 0.429 macro-F1. To test whether that ranking is a split artifact, we additionally run eight patient-level Monte Carlo resamples with same-case comparisons, stronger mechanism controls based on attention transfer and feature hints, and imbalance-sensitive analyses. Under this resampled protocol, late fusion attains the highest mean accuracy (0.885), same-modality distillation attains the highest mean macro-F1 (0.554) and balanced accuracy (0.660), the plain cross-modal control drops to 0.500 mean balanced accuracy, and neither attention transfer nor feature hints recover a robust cross-modality advantage. The contribution of this study is therefore not a validated CT-to-X-ray architecture, but a reproducible and evidence-bounded pilot protocol that makes the exact task definition, failure modes, ranking instability, and the minimum requirements for future credible CT-to-X-ray transfer claims explicit.
TSDCRF: Balancing Privacy and Multi-Object Tracking via Time-Series CRF and Normalized Control Penalty
Mar 14, 2026Multi-object tracking in video often requires appearance or location cues that can reveal sensitive identity information, while adding privacy-preserving noise typically disrupts cross-frame association and causes ID switches or target loss. We propose TSDCRF, a plug-in refinement framework that balances privacy and tracking by combining three components: (i) $(\varepsilon,δ)$-differential privacy via calibrated Gaussian noise on sensitive regions under a configurable privacy budget; (ii) a Normalized Control Penalty (NCP) that down-weights unstable or conflicting class predictions before noise injection to stabilize association; and (iii) a time-series dynamic conditional random field (DCRF) that enforces temporal consistency and corrects trajectory deviation after noise, mitigating ID switches and resilience to trajectory hijacking. The pipeline is agnostic to the choice of detector and tracker (e.g., YOLOv4 and DeepSORT). We evaluate on MOT16, MOT17, Cityscapes, and KITTI. Results show that TSDCRF achieves a better privacy--utility trade-off than white noise and prior methods (NTPD, PPDTSA): lower KL-divergence shift, lower tracking RMSE, and improved robustness under trajectory hijacking while preserving privacy. Source code in https://github.com/mabo1215/TSDCRF.git
PPEDCRF: Privacy-Preserving Enhanced Dynamic CRF for Location-Privacy Protection for Sequence Videos with Minimal Detection Degradation
Mar 02, 2026Dashcam videos collected by autonomous or assisted-driving systems are increasingly shared for safety auditing and model improvement. Even when explicit GPS metadata are removed, an attacker can still infer the recording location by matching background visual cues (e.g., buildings and road layouts) against large-scale street-view imagery. This paper studies location-privacy leakage under a background-based retrieval attacker, and proposes PPEDCRF, a privacy-preserving enhanced dynamic conditional random field framework that injects calibrated perturbations only into inferred location-sensitive background regions while preserving foreground detection utility. PPEDCRF consists of three components: (i) a dynamic CRF that enforces temporal consistency to discover and track location sensitive regions across frames, (ii) a normalized control penalty (NCP) that allocates perturbation strength according to a hierarchical sensitivity model, and (iii) a utility-preserving noise injection module that minimizes interference to object detection and segmentation. Experiments on public driving datasets demonstrate that PPEDCRF significantly reduces location-retrieval attack success (e.g., Top-k retrieval accuracy) while maintaining competitive detection performance (e.g., mAP and segmentation metrics) compared with common baselines such as global noise, white-noise masking, and feature-based anonymization. The source code is in https://github.com/mabo1215/PPEDCRF.git
KVSlimmer: Theoretical Insights and Practical Optimizations for Asymmetric KV Merging
Mar 01, 2026The growing computational and memory demands of the Key-Value (KV) cache significantly limit the ability of Large Language Models (LLMs). While KV merging has emerged as a promising solution, existing methods that rely on empirical observations of KV asymmetry and gradient-based Hessian approximations lack a theoretical foundation and incur suboptimal compression and inference overhead. To bridge these gaps, we establish a theoretical framework that characterizes this asymmetry through the spectral energy distribution of projection weights, demonstrating that concentrated spectra in Query/Key weights induce feature homogeneity, whereas dispersed spectra in Value weights preserve heterogeneity. Then, we introduce KVSlimmer, an efficient algorithm that captures exact Hessian information through a mathematically exact formulation, and derives a closed-form solution utilizing only forward-pass variables, resulting in a gradient-free approach that is both memory- and time-efficient. Extensive experiments across various models and benchmarks demonstrate that KVSlimmer consistently outperforms SOTA methods. For instance, on Llama3.1-8B-Instruct, it improves the LongBench average score by 0.92 while reducing memory costs and latency by 29% and 28%, respectively.
SCOUT: Semi-supervised Camouflaged Object Detection by Utilizing Text and Adaptive Data Selection
Aug 25, 2025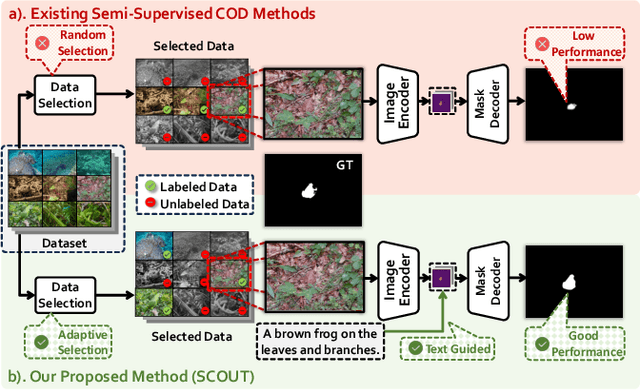

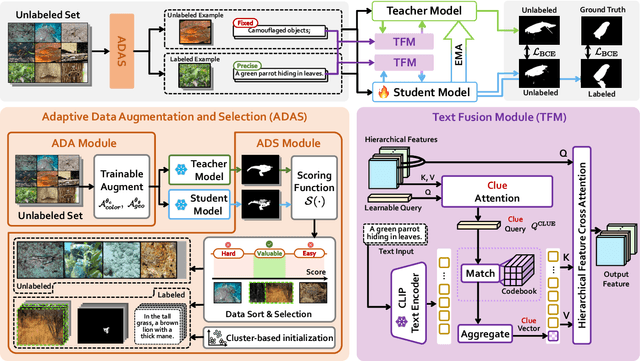

The difficulty of pixel-level annotation has significantly hindered the development of the Camouflaged Object Detection (COD) field. To save on annotation costs, previous works leverage the semi-supervised COD framework that relies on a small number of labeled data and a large volume of unlabeled data. We argue that there is still significant room for improvement in the effective utilization of unlabeled data. To this end, we introduce a Semi-supervised Camouflaged Object Detection by Utilizing Text and Adaptive Data Selection (SCOUT). It includes an Adaptive Data Augment and Selection (ADAS) module and a Text Fusion Module (TFM). The ADSA module selects valuable data for annotation through an adversarial augment and sampling strategy. The TFM module further leverages the selected valuable data by combining camouflage-related knowledge and text-visual interaction. To adapt to this work, we build a new dataset, namely RefTextCOD. Extensive experiments show that the proposed method surpasses previous semi-supervised methods in the COD field and achieves state-of-the-art performance. Our code will be released at https://github.com/Heartfirey/SCOUT.
UCOD-DPL: Unsupervised Camouflaged Object Detection via Dynamic Pseudo-label Learning
Jun 08, 2025Unsupervised Camoflaged Object Detection (UCOD) has gained attention since it doesn't need to rely on extensive pixel-level labels. Existing UCOD methods typically generate pseudo-labels using fixed strategies and train 1 x1 convolutional layers as a simple decoder, leading to low performance compared to fully-supervised methods. We emphasize two drawbacks in these approaches: 1). The model is prone to fitting incorrect knowledge due to the pseudo-label containing substantial noise. 2). The simple decoder fails to capture and learn the semantic features of camouflaged objects, especially for small-sized objects, due to the low-resolution pseudo-labels and severe confusion between foreground and background pixels. To this end, we propose a UCOD method with a teacher-student framework via Dynamic Pseudo-label Learning called UCOD-DPL, which contains an Adaptive Pseudo-label Module (APM), a Dual-Branch Adversarial (DBA) decoder, and a Look-Twice mechanism. The APM module adaptively combines pseudo-labels generated by fixed strategies and the teacher model to prevent the model from overfitting incorrect knowledge while preserving the ability for self-correction; the DBA decoder takes adversarial learning of different segmentation objectives, guides the model to overcome the foreground-background confusion of camouflaged objects, and the Look-Twice mechanism mimics the human tendency to zoom in on camouflaged objects and performs secondary refinement on small-sized objects. Extensive experiments show that our method demonstrates outstanding performance, even surpassing some existing fully supervised methods. The code is available now.