 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Memetic Walrus Algorithm with Expert-guided Strategy for Adaptive Curriculum Sequencing
Jun 16, 2025Adaptive Curriculum Sequencing (ACS) is essential for personalized online learning, yet current approaches struggle to balance complex educational constraints and maintain optimization stability. This paper proposes a Memetic Walrus Optimizer (MWO) that enhances optimization performance through three key innovations: (1) an expert-guided strategy with aging mechanism that improves escape from local optima; (2) an adaptive control signal framework that dynamically balances exploration and exploitation; and (3) a three-tier priority mechanism for generating educationally meaningful sequences. We formulate ACS as a multi-objective optimization problem considering concept coverage, time constraints, and learning style compatibility. Experiments on the OULAD dataset demonstrate MWO's superior performance, achieving 95.3% difficulty progression rate (compared to 87.2% in baseline methods) and significantly better convergence stability (standard deviation of 18.02 versus 28.29-696.97 in competing algorithms). Additional validation on benchmark functions confirms MWO's robust optimization capability across diverse scenarios. The results demonstrate MWO's effectiveness in generating personalized learning sequences while maintaining computational efficiency and solution quality.
Pushing the Limits of Safety: A Technical Report on the ATLAS Challenge 2025
Jun 14, 2025Multimodal Large Language Models (MLLMs) have enabled transformative advancements across diverse applications but remain susceptible to safety threats, especially jailbreak attacks that induce harmful outputs. To systematically evaluate and improve their safety, we organized the Adversarial Testing & Large-model Alignment Safety Grand Challenge (ATLAS) 2025}. This technical report presents findings from the competition, which involved 86 teams testing MLLM vulnerabilities via adversarial image-text attacks in two phases: white-box and black-box evaluations. The competition results highlight ongoing challenges in securing MLLMs and provide valuable guidance for developing stronger defense mechanisms. The challenge establishes new benchmarks for MLLM safety evaluation and lays groundwork for advancing safer multimodal AI systems. The code and data for this challenge are openly available at https://github.com/NY1024/ATLAS_Challenge_2025.
Proxy-Free GFlowNet
May 26, 2025Generative Flow Networks (GFlowNets) are a promising class of generative models designed to sample diverse, high-reward structures by modeling distributions over compositional objects. In many real-world applications, obtaining the reward function for such objects is expensive, time-consuming, or requires human input, making it necessary to train GFlowNets from historical datasets. Most existing methods adopt a model-based approach, learning a proxy model from the dataset to approximate the reward function. However, this strategy inherently ties the quality of the learned policy to the accuracy of the proxy, introducing additional complexity and uncertainty into the training process. To overcome these limitations, we propose \textbf{Trajectory-Distilled GFlowNet (TD-GFN)}, a \emph{proxy-free} training framework that eliminates the need for out-of-dataset reward queries. Our method is motivated by the key observation that different edges in the associated directed acyclic graph (DAG) contribute unequally to effective policy learning. TD-GFN leverages inverse reinforcement learning to estimate edge-level rewards from the offline dataset, which are then used to ingeniously prune the DAG and guide backward trajectory sampling during training. This approach directs the policy toward high-reward regions while reducing the complexity of model fitting. Empirical results across multiple tasks show that TD-GFN trains both efficiently and reliably, significantly outperforming existing baselines in convergence speed and sample quality.
Mogao: An Omni Foundation Model for Interleaved Multi-Modal Generation
May 08, 2025Recent progress in unified models for image understanding and generation has been impressive, yet most approaches remain limited to single-modal generation conditioned on multiple modalities. In this paper, we present Mogao, a unified framework that advances this paradigm by enabling interleaved multi-modal generation through a causal approach. Mogao integrates a set of key technical improvements in architecture design, including a deep-fusion design, dual vision encoders, interleaved rotary position embeddings, and multi-modal classifier-free guidance, which allow it to harness the strengths of both autoregressive models for text generation and diffusion models for high-quality image synthesis. These practical improvements also make Mogao particularly effective to process interleaved sequences of text and images arbitrarily. To further unlock the potential of unified models, we introduce an efficient training strategy on a large-scale, in-house dataset specifically curated for joint text and image generation. Extensive experiments show that Mogao not only achieves state-of-the-art performance in multi-modal understanding and text-to-image generation, but also excels in producing high-quality, coherent interleaved outputs. Its emergent capabilities in zero-shot image editing and compositional generation highlight Mogao as a practical omni-modal foundation model, paving the way for future development and scaling the unified multi-modal systems.
Seedream 3.0 Technical Report
Apr 16, 2025



We present Seedream 3.0, a high-performance Chinese-English bilingual image generation foundation model. We develop several technical improvements to address existing challenges in Seedream 2.0, including alignment with complicated prompts, fine-grained typography generation, suboptimal visual aesthetics and fidelity, and limited image resolutions. Specifically, the advancements of Seedream 3.0 stem from improvements across the entire pipeline, from data construction to model deployment. At the data stratum, we double the dataset using a defect-aware training paradigm and a dual-axis collaborative data-sampling framework. Furthermore, we adopt several effective techniques such as mixed-resolution training, cross-modality RoPE, representation alignment loss, and resolution-aware timestep sampling in the pre-training phase. During the post-training stage, we utilize diversified aesthetic captions in SFT, and a VLM-based reward model with scaling, thereby achieving outputs that well align with human preferences. Furthermore, Seedream 3.0 pioneers a novel acceleration paradigm. By employing consistent noise expectation and importance-aware timestep sampling, we achieve a 4 to 8 times speedup while maintaining image quality. Seedream 3.0 demonstrates significant improvements over Seedream 2.0: it enhances overall capabilities, in particular for text-rendering in complicated Chinese characters which is important to professional typography generation. In addition, it provides native high-resolution output (up to 2K), allowing it to generate images with high visual quality.
SimpleAR: Pushing the Frontier of Autoregressive Visual Generation through Pretraining, SFT, and RL
Apr 15, 2025This work presents SimpleAR, a vanilla autoregressive visual generation framework without complex architecure modifications. Through careful exploration of training and inference optimization, we demonstrate that: 1) with only 0.5B parameters, our model can generate 1024x1024 resolution images with high fidelity, and achieve competitive results on challenging text-to-image benchmarks, e.g., 0.59 on GenEval and 79.66 on DPG; 2) both supervised fine-tuning (SFT) and Group Relative Policy Optimization (GRPO) training could lead to significant improvements on generation aesthectics and prompt alignment; and 3) when optimized with inference acceleraton techniques like vLLM, the time for SimpleAR to generate an 1024x1024 image could be reduced to around 14 seconds. By sharing these findings and open-sourcing the code, we hope to reveal the potential of autoregressive visual generation and encourage more participation in this research field. Code is available at https://github.com/wdrink/SimpleAR.
Machine Learning-Based Genomic Linguistic Analysis (Gene Sequence Feature Learning): A Case Study on Predicting Heavy Metal Response Genes in Rice
Mar 20, 2025This study explores the application of machine learning-based genetic linguistics for identifying heavy metal response genes in rice (Oryza sativa). By integrating convolutional neural networks and random forest algorithms, we developed a hybrid model capable of extracting and learning meaningful features from gene sequences, such as k-mer frequencies and physicochemical properties. The model was trained and tested on datasets of genes, achieving high predictive performance (precision: 0.89, F1-score: 0.82). RNA-seq and qRT-PCR experiments conducted on rice leaves which exposed to Hg0, revealed differential expression of genes associated with heavy metal responses, which validated the model's predictions. Co-expression network analysis identified 103 related genes, and a literature review indicated that these genes are highly likely to be involved in heavy metal-related biological processes. By integrating and comparing the analysis results with those of differentially expressed genes (DEGs), the validity of the new machine learning method was further demonstrated. This study highlights the efficacy of combining machine learning with genetic linguistics for large-scale gene prediction. It demonstrates a cost-effective and efficient approach for uncovering molecular mechanisms underlying heavy metal responses, with potential applications in developing stress-tolerant crop varieties.
Seedream 2.0: A Native Chinese-English Bilingual Image Generation Foundation Model
Mar 10, 2025Rapid advancement of diffusion models has catalyzed remarkable progress in the field of image generation. However, prevalent models such as Flux, SD3.5 and Midjourney, still grapple with issues like model bias, limited text rendering capabilities, and insufficient understanding of Chinese cultural nuances. To address these limitations, we present Seedream 2.0, a native Chinese-English bilingual image generation foundation model that excels across diverse dimensions, which adeptly manages text prompt in both Chinese and English, supporting bilingual image generation and text rendering. We develop a powerful data system that facilitates knowledge integration, and a caption system that balances the accuracy and richness for image description. Particularly, Seedream is integrated with a self-developed bilingual large language model as a text encoder, allowing it to learn native knowledge directly from massive data. This enable it to generate high-fidelity images with accurate cultural nuances and aesthetic expressions described in either Chinese or English. Beside, Glyph-Aligned ByT5 is applied for flexible character-level text rendering, while a Scaled ROPE generalizes well to untrained resolutions. Multi-phase post-training optimizations, including SFT and RLHF iterations, further improve the overall capability. Through extensive experimentation, we demonstrate that Seedream 2.0 achieves state-of-the-art performance across multiple aspects, including prompt-following, aesthetics, text rendering, and structural correctness. Furthermore, Seedream 2.0 has been optimized through multiple RLHF iterations to closely align its output with human preferences, as revealed by its outstanding ELO score. In addition, it can be readily adapted to an instruction-based image editing model, such as SeedEdit, with strong editing capability that balances instruction-following and image consistency.
MPO: Boosting LLM Agents with Meta Plan Optimization
Mar 04, 2025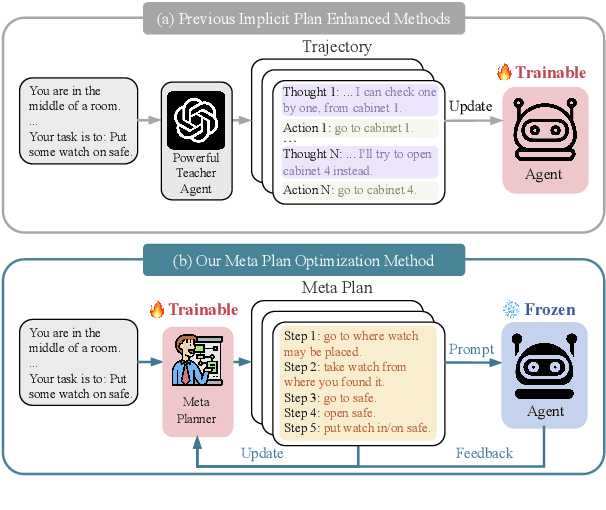

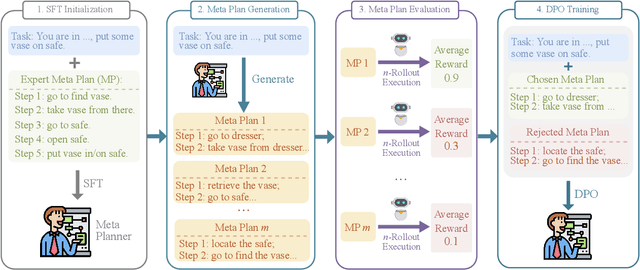
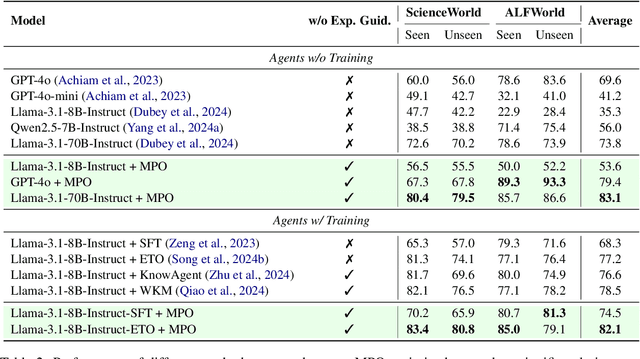
Recent advancements in large language models (LLMs) have enabled LLM-based agents to successfully tackle interactive planning tasks. However, despite their successes, existing approaches often suffer from planning hallucinations and require retraining for each new agent. To address these challenges, we propose the Meta Plan Optimization (MPO) framework, which enhances agent planning capabilities by directly incorporating explicit guidance. Unlike previous methods that rely on complex knowledge, which either require significant human effort or lack quality assurance, MPO leverages high-level general guidance through meta plans to assist agent planning and enables continuous optimization of the meta plans based on feedback from the agent's task execution. Our experiments conducted on two representative tasks demonstrate that MPO significantly outperforms existing baselines. Moreover, our analysis indicates that MPO provides a plug-and-play solution that enhances both task completion efficiency and generalization capabilities in previous unseen scenarios.
Fine-Grained Controllable Apparel Showcase Image Generation via Garment-Centric Outpainting
Mar 03, 2025In this paper, we propose a novel garment-centric outpainting (GCO) framework based on the latent diffusion model (LDM) for fine-grained controllable apparel showcase image generation. The proposed framework aims at customizing a fashion model wearing a given garment via text prompts and facial images. Different from existing methods, our framework takes a garment image segmented from a dressed mannequin or a person as the input, eliminating the need for learning cloth deformation and ensuring faithful preservation of garment details. The proposed framework consists of two stages. In the first stage, we introduce a garment-adaptive pose prediction model that generates diverse poses given the garment. Then, in the next stage, we generate apparel showcase images, conditioned on the garment and the predicted poses, along with specified text prompts and facial images. Notably, a multi-scale appearance customization module (MS-ACM) is designed to allow both overall and fine-grained text-based control over the generated model's appearance. Moreover, we leverage a lightweight feature fusion operation without introducing any extra encoders or modules to integrate multiple conditions, which is more efficient. Extensive experiments validate the superior performance of our framework compared to state-of-the-art methods.