 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCan Adversarial Examples Be Parsed to Reveal Victim Model Information?
Mar 15, 2023Numerous adversarial attack methods have been developed to generate imperceptible image perturbations that can cause erroneous predictions of state-of-the-art machine learning (ML) models, in particular, deep neural networks (DNNs). Despite intense research on adversarial attacks, little effort was made to uncover 'arcana' carried in adversarial attacks. In this work, we ask whether it is possible to infer data-agnostic victim model (VM) information (i.e., characteristics of the ML model or DNN used to generate adversarial attacks) from data-specific adversarial instances. We call this 'model parsing of adversarial attacks' - a task to uncover 'arcana' in terms of the concealed VM information in attacks. We approach model parsing via supervised learning, which correctly assigns classes of VM's model attributes (in terms of architecture type, kernel size, activation function, and weight sparsity) to an attack instance generated from this VM. We collect a dataset of adversarial attacks across 7 attack types generated from 135 victim models (configured by 5 architecture types, 3 kernel size setups, 3 activation function types, and 3 weight sparsity ratios). We show that a simple, supervised model parsing network (MPN) is able to infer VM attributes from unseen adversarial attacks if their attack settings are consistent with the training setting (i.e., in-distribution generalization assessment). We also provide extensive experiments to justify the feasibility of VM parsing from adversarial attacks, and the influence of training and evaluation factors in the parsing performance (e.g., generalization challenge raised in out-of-distribution evaluation). We further demonstrate how the proposed MPN can be used to uncover the source VM attributes from transfer attacks, and shed light on a potential connection between model parsing and attack transferability.
Less is More: Data Pruning for Faster Adversarial Training
Feb 28, 2023Deep neural networks (DNNs) are sensitive to adversarial examples, resulting in fragile and unreliable performance in the real world. Although adversarial training (AT) is currently one of the most effective methodologies to robustify DNNs, it is computationally very expensive (e.g., 5-10X costlier than standard training). To address this challenge, existing approaches focus on single-step AT, referred to as Fast AT, reducing the overhead of adversarial example generation. Unfortunately, these approaches are known to fail against stronger adversaries. To make AT computationally efficient without compromising robustness, this paper takes a different view of the efficient AT problem. Specifically, we propose to minimize redundancies at the data level by leveraging data pruning. Extensive experiments demonstrate that the data pruning based AT can achieve similar or superior robust (and clean) accuracy as its unpruned counterparts while being significantly faster. For instance, proposed strategies accelerate CIFAR-10 training up to 3.44X and CIFAR-100 training to 2.02X. Additionally, the data pruning methods can readily be reconciled with existing adversarial acceleration tricks to obtain the striking speed-ups of 5.66X and 5.12X on CIFAR-10, 3.67X and 3.07X on CIFAR-100 with TRADES and MART, respectively.
ASSET: Robust Backdoor Data Detection Across a Multiplicity of Deep Learning Paradigms
Feb 22, 2023



Backdoor data detection is traditionally studied in an end-to-end supervised learning (SL) setting. However, recent years have seen the proliferating adoption of self-supervised learning (SSL) and transfer learning (TL), due to their lesser need for labeled data. Successful backdoor attacks have also been demonstrated in these new settings. However, we lack a thorough understanding of the applicability of existing detection methods across a variety of learning settings. By evaluating 56 attack settings, we show that the performance of most existing detection methods varies significantly across different attacks and poison ratios, and all fail on the state-of-the-art clean-label attack. In addition, they either become inapplicable or suffer large performance losses when applied to SSL and TL. We propose a new detection method called Active Separation via Offset (ASSET), which actively induces different model behaviors between the backdoor and clean samples to promote their separation. We also provide procedures to adaptively select the number of suspicious points to remove. In the end-to-end SL setting, ASSET is superior to existing methods in terms of consistency of defensive performance across different attacks and robustness to changes in poison ratios; in particular, it is the only method that can detect the state-of-the-art clean-label attack. Moreover, ASSET's average detection rates are higher than the best existing methods in SSL and TL, respectively, by 69.3% and 33.2%, thus providing the first practical backdoor defense for these new DL settings. We open-source the project to drive further development and encourage engagement: https://github.com/ruoxi-jia-group/ASSET.
HeatViT: Hardware-Efficient Adaptive Token Pruning for Vision Transformers
Nov 15, 2022



While vision transformers (ViTs) have continuously achieved new milestones in the field of computer vision, their sophisticated network architectures with high computation and memory costs have impeded their deployment on resource-limited edge devices. In this paper, we propose a hardware-efficient image-adaptive token pruning framework called HeatViT for efficient yet accurate ViT acceleration on embedded FPGAs. By analyzing the inherent computational patterns in ViTs, we first design an effective attention-based multi-head token selector, which can be progressively inserted before transformer blocks to dynamically identify and consolidate the non-informative tokens from input images. Moreover, we implement the token selector on hardware by adding miniature control logic to heavily reuse existing hardware components built for the backbone ViT. To improve the hardware efficiency, we further employ 8-bit fixed-point quantization, and propose polynomial approximations with regularization effect on quantization error for the frequently used nonlinear functions in ViTs. Finally, we propose a latency-aware multi-stage training strategy to determine the transformer blocks for inserting token selectors and optimize the desired (average) pruning rates for inserted token selectors, in order to improve both the model accuracy and inference latency on hardware. Compared to existing ViT pruning studies, under the similar computation cost, HeatViT can achieve 0.7%$\sim$8.9% higher accuracy; while under the similar model accuracy, HeatViT can achieve more than 28.4%$\sim$65.3% computation reduction, for various widely used ViTs, including DeiT-T, DeiT-S, DeiT-B, LV-ViT-S, and LV-ViT-M, on the ImageNet dataset. Compared to the baseline hardware accelerator, our implementations of HeatViT on the Xilinx ZCU102 FPGA achieve 3.46$\times$$\sim$4.89$\times$ speedup.
Efficient Multi-Prize Lottery Tickets: Enhanced Accuracy, Training, and Inference Speed
Sep 26, 2022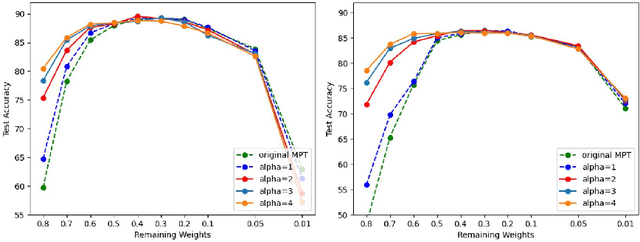
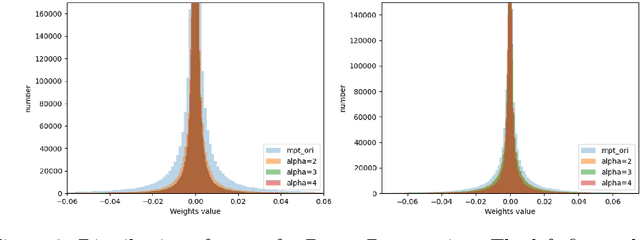

Recently, Diffenderfer and Kailkhura proposed a new paradigm for learning compact yet highly accurate binary neural networks simply by pruning and quantizing randomly weighted full precision neural networks. However, the accuracy of these multi-prize tickets (MPTs) is highly sensitive to the optimal prune ratio, which limits their applicability. Furthermore, the original implementation did not attain any training or inference speed benefits. In this report, we discuss several improvements to overcome these limitations. We show the benefit of the proposed techniques by performing experiments on CIFAR-10.
Auto-ViT-Acc: An FPGA-Aware Automatic Acceleration Framework for Vision Transformer with Mixed-Scheme Quantization
Aug 10, 2022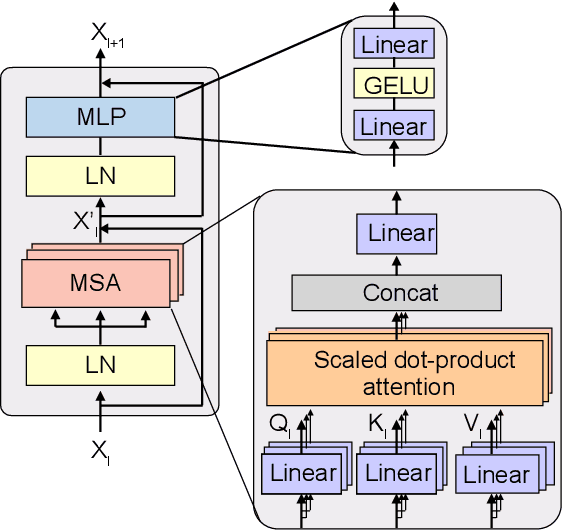
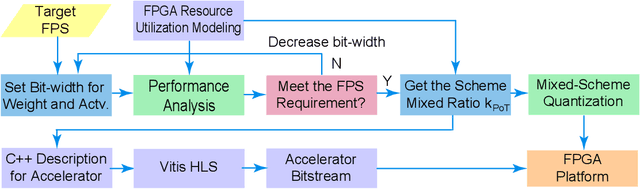
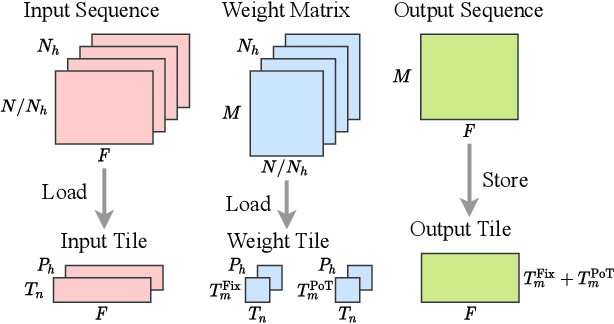
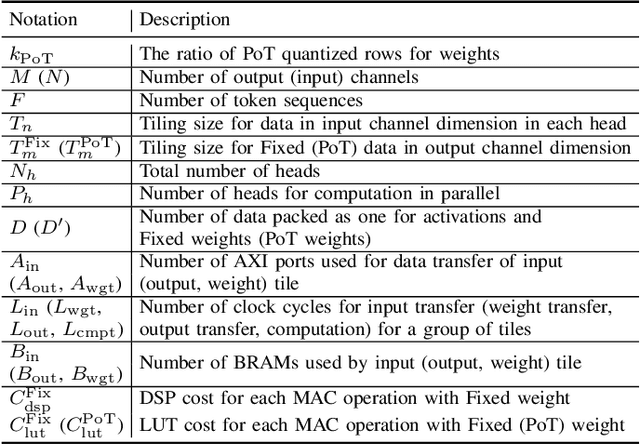
Vision transformers (ViTs) are emerging with significantly improved accuracy in computer vision tasks. However, their complex architecture and enormous computation/storage demand impose urgent needs for new hardware accelerator design methodology. This work proposes an FPGA-aware automatic ViT acceleration framework based on the proposed mixed-scheme quantization. To the best of our knowledge, this is the first FPGA-based ViT acceleration framework exploring model quantization. Compared with state-of-the-art ViT quantization work (algorithmic approach only without hardware acceleration), our quantization achieves 0.47% to 1.36% higher Top-1 accuracy under the same bit-width. Compared with the 32-bit floating-point baseline FPGA accelerator, our accelerator achieves around 5.6x improvement on the frame rate (i.e., 56.8 FPS vs. 10.0 FPS) with 0.71% accuracy drop on ImageNet dataset for DeiT-base.
FAIVConf: Face enhancement for AI-based Video Conference with Low Bit-rate
Jul 08, 2022
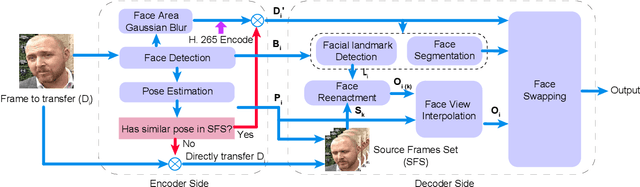
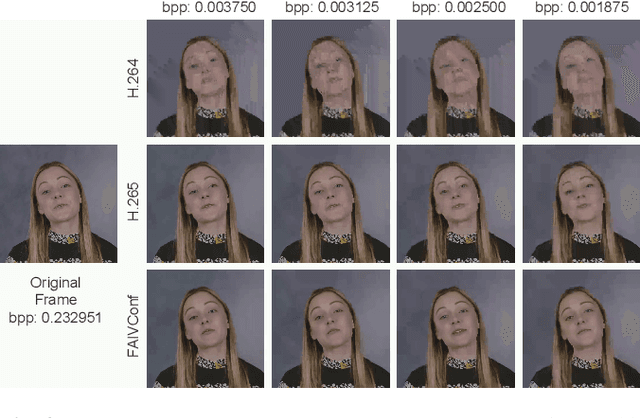
Recently, high-quality video conferencing with fewer transmission bits has become a very hot and challenging problem. We propose FAIVConf, a specially designed video compression framework for video conferencing, based on the effective neural human face generation techniques. FAIVConf brings together several designs to improve the system robustness in real video conference scenarios: face-swapping to avoid artifacts in background animation; facial blurring to decrease transmission bit-rate and maintain the quality of extracted facial landmarks; and dynamic source update for face view interpolation to accommodate a large range of head poses. Our method achieves a significant bit-rate reduction in the video conference and gives much better visual quality under the same bit-rate compared with H.264 and H.265 coding schemes.
Pruning-as-Search: Efficient Neural Architecture Search via Channel Pruning and Structural Reparameterization
Jun 02, 2022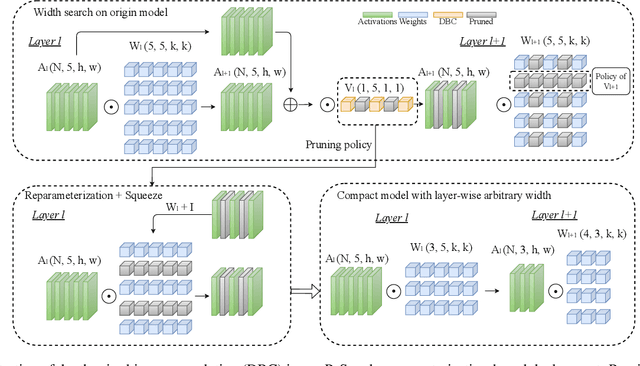
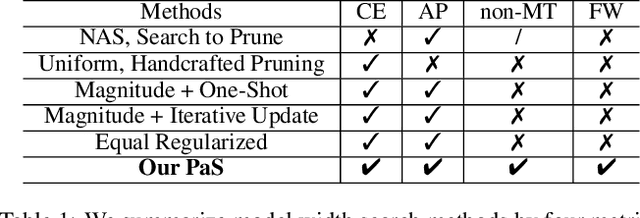

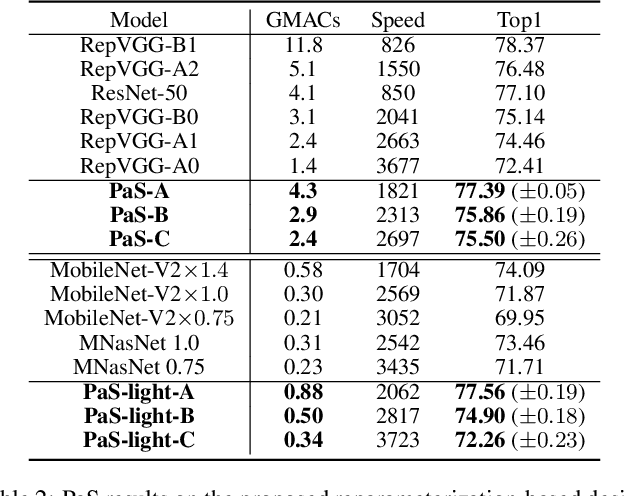
Neural architecture search (NAS) and network pruning are widely studied efficient AI techniques, but not yet perfect. NAS performs exhaustive candidate architecture search, incurring tremendous search cost. Though (structured) pruning can simply shrink model dimension, it remains unclear how to decide the per-layer sparsity automatically and optimally. In this work, we revisit the problem of layer-width optimization and propose Pruning-as-Search (PaS), an end-to-end channel pruning method to search out desired sub-network automatically and efficiently. Specifically, we add a depth-wise binary convolution to learn pruning policies directly through gradient descent. By combining the structural reparameterization and PaS, we successfully searched out a new family of VGG-like and lightweight networks, which enable the flexibility of arbitrary width with respect to each layer instead of each stage. Experimental results show that our proposed architecture outperforms prior arts by around $1.0\%$ top-1 accuracy under similar inference speed on ImageNet-1000 classification task. Furthermore, we demonstrate the effectiveness of our width search on complex tasks including instance segmentation and image translation. Code and models are released.
Location-free Human Pose Estimation
May 25, 2022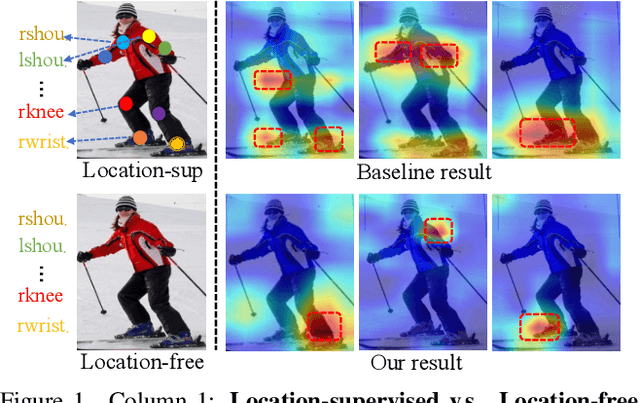
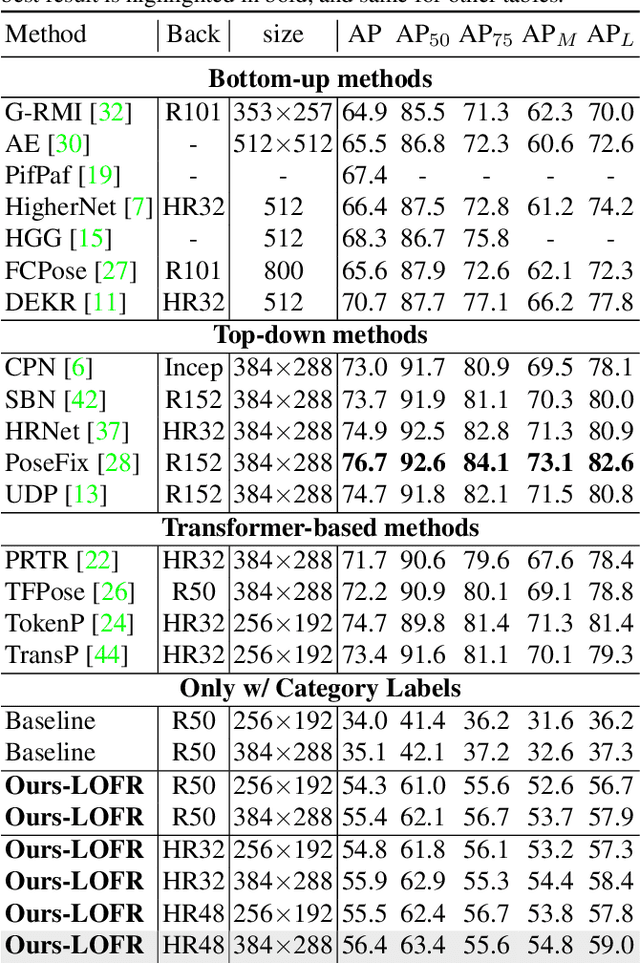
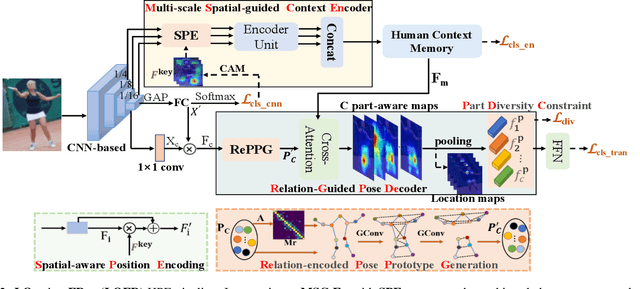
Human pose estimation (HPE) usually requires large-scale training data to reach high performance. However, it is rather time-consuming to collect high-quality and fine-grained annotations for human body. To alleviate this issue, we revisit HPE and propose a location-free framework without supervision of keypoint locations. We reformulate the regression-based HPE from the perspective of classification. Inspired by the CAM-based weakly-supervised object localization, we observe that the coarse keypoint locations can be acquired through the part-aware CAMs but unsatisfactory due to the gap between the fine-grained HPE and the object-level localization. To this end, we propose a customized transformer framework to mine the fine-grained representation of human context, equipped with the structural relation to capture subtle differences among keypoints. Concretely, we design a Multi-scale Spatial-guided Context Encoder to fully capture the global human context while focusing on the part-aware regions and a Relation-encoded Pose Prototype Generation module to encode the structural relations. All these works together for strengthening the weak supervision from image-level category labels on locations. Our model achieves competitive performance on three datasets when only supervised at a category-level and importantly, it can achieve comparable results with fully-supervised methods with only 25\% location labels on MS-COCO and MPII.
Reverse Engineering of Imperceptible Adversarial Image Perturbations
Apr 01, 2022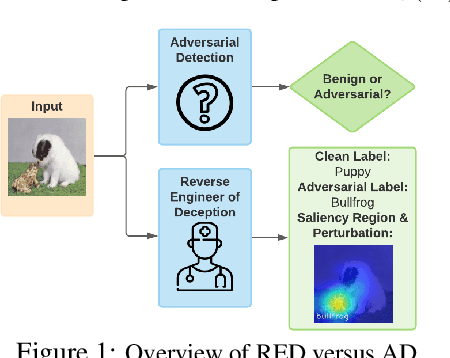
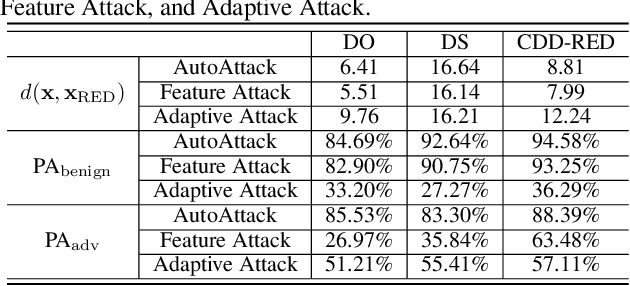
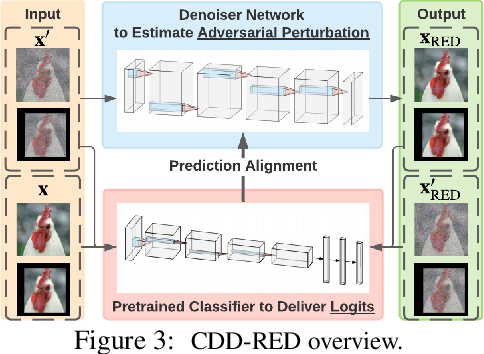
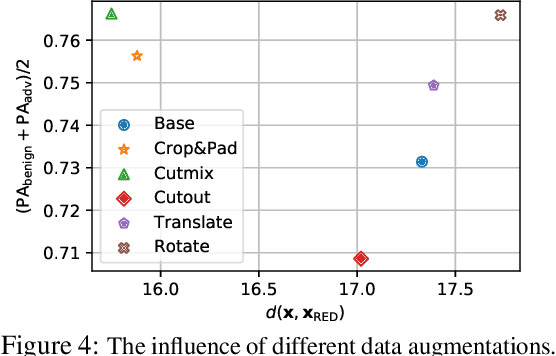
It has been well recognized that neural network based image classifiers are easily fooled by images with tiny perturbations crafted by an adversary. There has been a vast volume of research to generate and defend such adversarial attacks. However, the following problem is left unexplored: How to reverse-engineer adversarial perturbations from an adversarial image? This leads to a new adversarial learning paradigm--Reverse Engineering of Deceptions (RED). If successful, RED allows us to estimate adversarial perturbations and recover the original images. However, carefully crafted, tiny adversarial perturbations are difficult to recover by optimizing a unilateral RED objective. For example, the pure image denoising method may overfit to minimizing the reconstruction error but hardly preserve the classification properties of the true adversarial perturbations. To tackle this challenge, we formalize the RED problem and identify a set of principles crucial to the RED approach design. Particularly, we find that prediction alignment and proper data augmentation (in terms of spatial transformations) are two criteria to achieve a generalizable RED approach. By integrating these RED principles with image denoising, we propose a new Class-Discriminative Denoising based RED framework, termed CDD-RED. Extensive experiments demonstrate the effectiveness of CDD-RED under different evaluation metrics (ranging from the pixel-level, prediction-level to the attribution-level alignment) and a variety of attack generation methods (e.g., FGSM, PGD, CW, AutoAttack, and adaptive attacks).