 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMuseformer: Transformer with Fine- and Coarse-Grained Attention for Music Generation
Oct 19, 2022
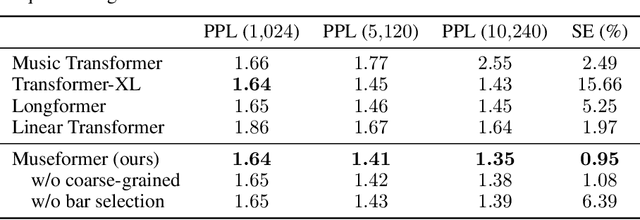
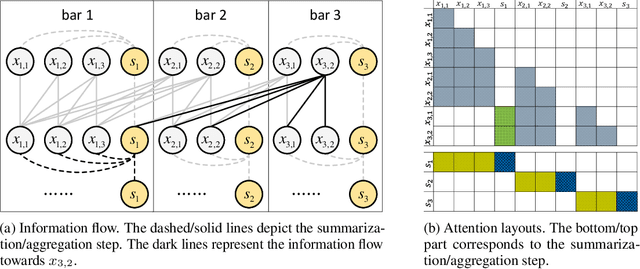
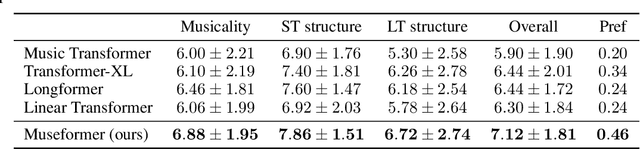
Symbolic music generation aims to generate music scores automatically. A recent trend is to use Transformer or its variants in music generation, which is, however, suboptimal, because the full attention cannot efficiently model the typically long music sequences (e.g., over 10,000 tokens), and the existing models have shortcomings in generating musical repetition structures. In this paper, we propose Museformer, a Transformer with a novel fine- and coarse-grained attention for music generation. Specifically, with the fine-grained attention, a token of a specific bar directly attends to all the tokens of the bars that are most relevant to music structures (e.g., the previous 1st, 2nd, 4th and 8th bars, selected via similarity statistics); with the coarse-grained attention, a token only attends to the summarization of the other bars rather than each token of them so as to reduce the computational cost. The advantages are two-fold. First, it can capture both music structure-related correlations via the fine-grained attention, and other contextual information via the coarse-grained attention. Second, it is efficient and can model over 3X longer music sequences compared to its full-attention counterpart. Both objective and subjective experimental results demonstrate its ability to generate long music sequences with high quality and better structures.
MeloForm: Generating Melody with Musical Form based on Expert Systems and Neural Networks
Aug 30, 2022
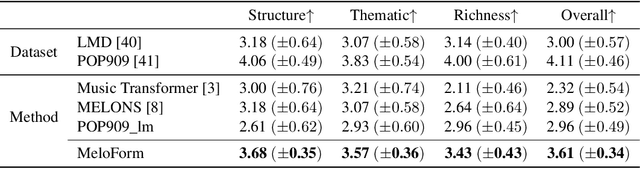
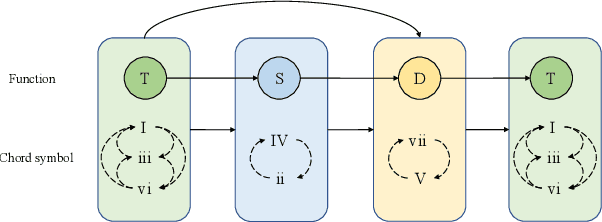
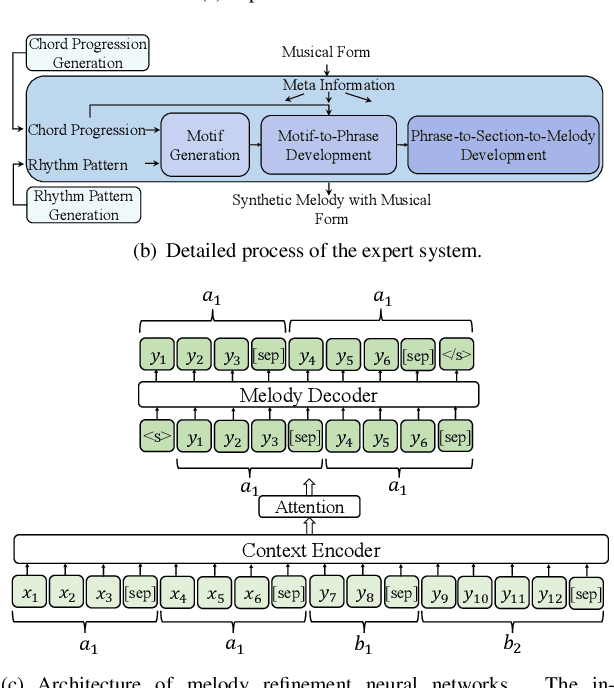
Human usually composes music by organizing elements according to the musical form to express music ideas. However, for neural network-based music generation, it is difficult to do so due to the lack of labelled data on musical form. In this paper, we develop MeloForm, a system that generates melody with musical form using expert systems and neural networks. Specifically, 1) we design an expert system to generate a melody by developing musical elements from motifs to phrases then to sections with repetitions and variations according to pre-given musical form; 2) considering the generated melody is lack of musical richness, we design a Transformer based refinement model to improve the melody without changing its musical form. MeloForm enjoys the advantages of precise musical form control by expert systems and musical richness learning via neural models. Both subjective and objective experimental evaluations demonstrate that MeloForm generates melodies with precise musical form control with 97.79% accuracy, and outperforms baseline systems in terms of subjective evaluation score by 0.75, 0.50, 0.86 and 0.89 in structure, thematic, richness and overall quality, without any labelled musical form data. Besides, MeloForm can support various kinds of forms, such as verse and chorus form, rondo form, variational form, sonata form, etc.
StableFace: Analyzing and Improving Motion Stability for Talking Face Generation
Aug 29, 2022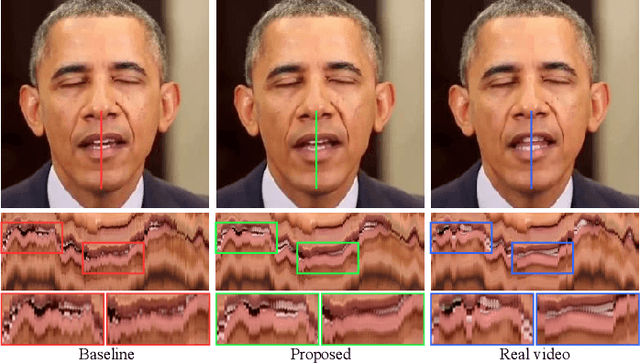
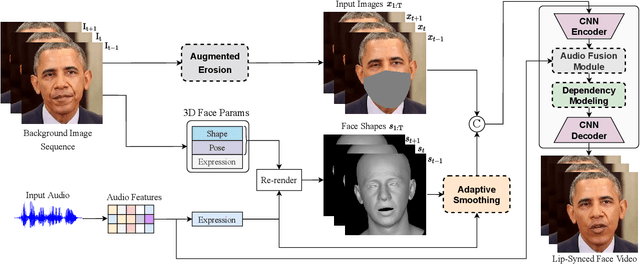
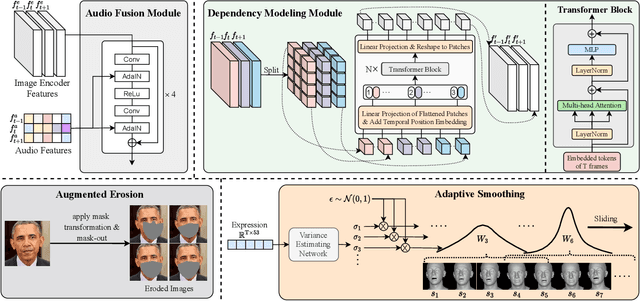

While previous speech-driven talking face generation methods have made significant progress in improving the visual quality and lip-sync quality of the synthesized videos, they pay less attention to lip motion jitters which greatly undermine the realness of talking face videos. What causes motion jitters, and how to mitigate the problem? In this paper, we conduct systematic analyses on the motion jittering problem based on a state-of-the-art pipeline that uses 3D face representations to bridge the input audio and output video, and improve the motion stability with a series of effective designs. We find that several issues can lead to jitters in synthesized talking face video: 1) jitters from the input 3D face representations; 2) training-inference mismatch; 3) lack of dependency modeling among video frames. Accordingly, we propose three effective solutions to address this issue: 1) we propose a gaussian-based adaptive smoothing module to smooth the 3D face representations to eliminate jitters in the input; 2) we add augmented erosions on the input data of the neural renderer in training to simulate the distortion in inference to reduce mismatch; 3) we develop an audio-fused transformer generator to model dependency among video frames. Besides, considering there is no off-the-shelf metric for measuring motion jitters in talking face video, we devise an objective metric (Motion Stability Index, MSI), to quantitatively measure the motion jitters by calculating the reciprocal of variance acceleration. Extensive experimental results show the superiority of our method on motion-stable face video generation, with better quality than previous systems.
Re-creation of Creations: A New Paradigm for Lyric-to-Melody Generation
Aug 18, 2022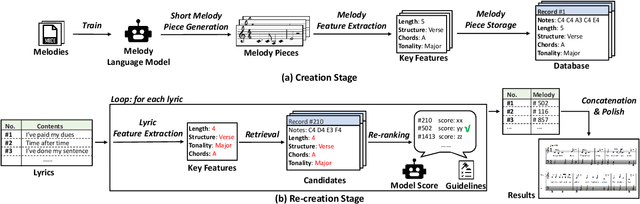
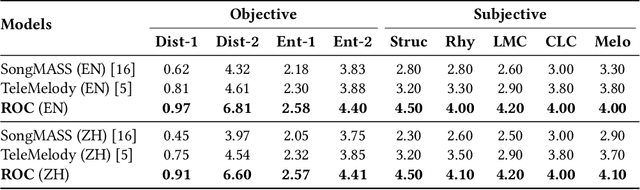
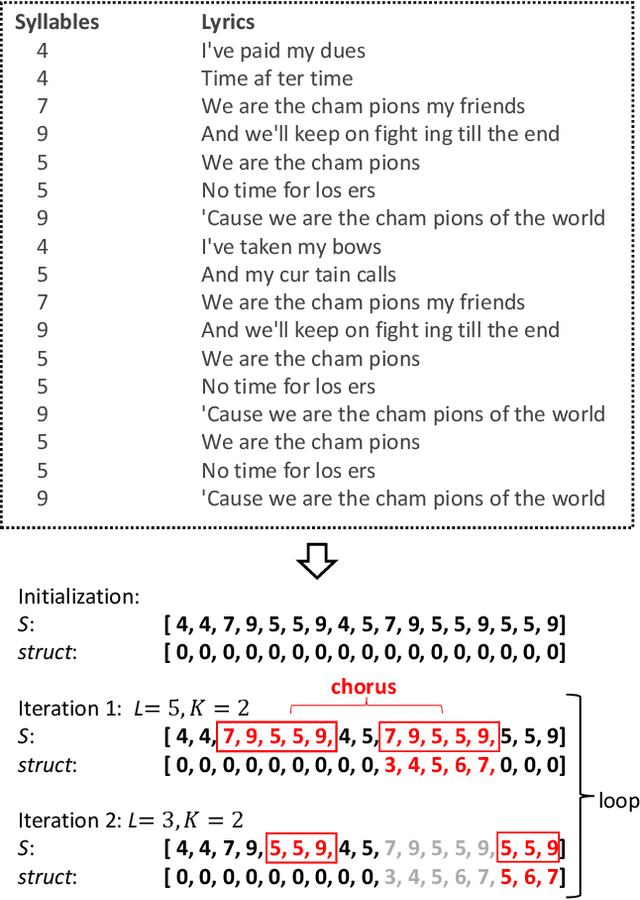
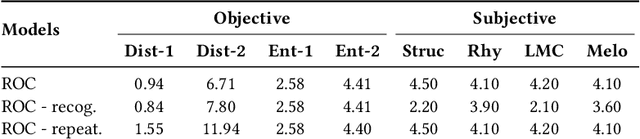
Lyric-to-melody generation is an important task in songwriting, and is also quite challenging due to its distinctive characteristics: the generated melodies should not only follow good musical patterns, but also align with features in lyrics such as rhythms and structures. These characteristics cannot be well handled by neural generation models that learn lyric-to-melody mapping in an end-to-end way, due to several issues: (1) lack of aligned lyric-melody training data to sufficiently learn lyric-melody feature alignment; (2) lack of controllability in generation to explicitly guarantee the lyric-melody feature alignment. In this paper, we propose Re-creation of Creations (ROC), a new paradigm for lyric-to-melody generation that addresses the above issues through a generation-retrieval pipeline. Specifically, our paradigm has two stages: (1) creation stage, where a huge amount of music pieces are generated by a neural-based melody language model and indexed in a database through several key features (e.g., chords, tonality, rhythm, and structural information including chorus or verse); (2) re-creation stage, where melodies are recreated by retrieving music pieces from the database according to the key features from lyrics and concatenating best music pieces based on composition guidelines and melody language model scores. Our new paradigm has several advantages: (1) It only needs unpaired melody data to train melody language model, instead of paired lyric-melody data in previous models. (2) It achieves good lyric-melody feature alignment in lyric-to-melody generation. Experiments on English and Chinese datasets demonstrate that ROC outperforms previous neural based lyric-to-melody generation models on both objective and subjective metrics.
ReLyMe: Improving Lyric-to-Melody Generation by Incorporating Lyric-Melody Relationships
Jul 12, 2022
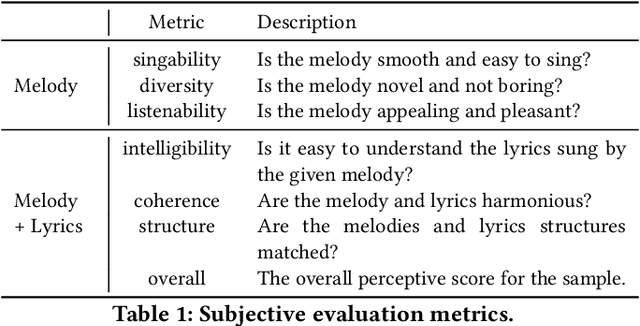
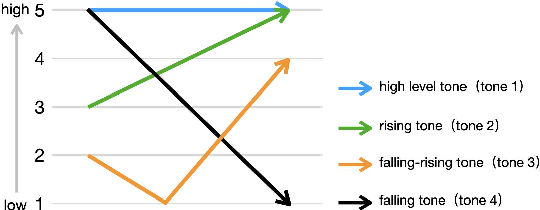
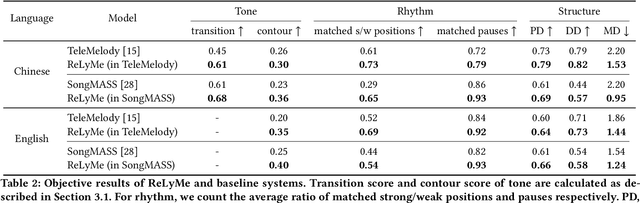
Lyric-to-melody generation, which generates melody according to given lyrics, is one of the most important automatic music composition tasks. With the rapid development of deep learning, previous works address this task with end-to-end neural network models. However, deep learning models cannot well capture the strict but subtle relationships between lyrics and melodies, which compromises the harmony between lyrics and generated melodies. In this paper, we propose ReLyMe, a method that incorporates Relationships between Lyrics and Melodies from music theory to ensure the harmony between lyrics and melodies. Specifically, we first introduce several principles that lyrics and melodies should follow in terms of tone, rhythm, and structure relationships. These principles are then integrated into neural network lyric-to-melody models by adding corresponding constraints during the decoding process to improve the harmony between lyrics and melodies. We use a series of objective and subjective metrics to evaluate the generated melodies. Experiments on both English and Chinese song datasets show the effectiveness of ReLyMe, demonstrating the superiority of incorporating lyric-melody relationships from the music domain into neural lyric-to-melody generation.
DelightfulTTS 2: End-to-End Speech Synthesis with Adversarial Vector-Quantized Auto-Encoders
Jul 11, 2022
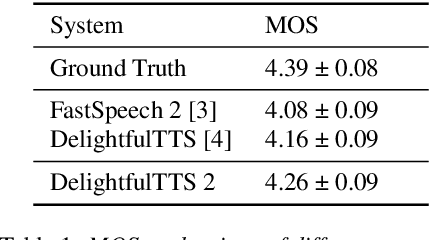
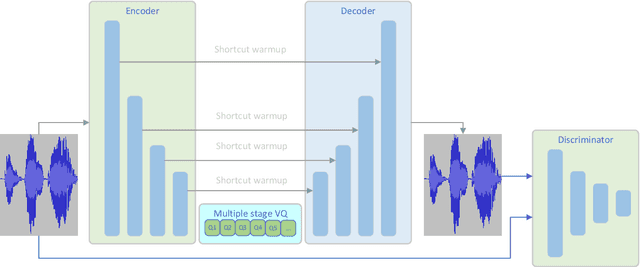
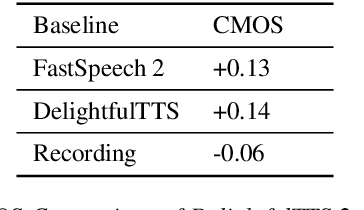
Current text to speech (TTS) systems usually leverage a cascaded acoustic model and vocoder pipeline with mel-spectrograms as the intermediate representations, which suffer from two limitations: 1) the acoustic model and vocoder are separately trained instead of jointly optimized, which incurs cascaded errors; 2) the intermediate speech representations (e.g., mel-spectrogram) are pre-designed and lose phase information, which are sub-optimal. To solve these problems, in this paper, we develop DelightfulTTS 2, a new end-to-end speech synthesis system with automatically learned speech representations and jointly optimized acoustic model and vocoder. Specifically, 1) we propose a new codec network based on vector-quantized auto-encoders with adversarial training (VQ-GAN) to extract intermediate frame-level speech representations (instead of traditional representations like mel-spectrograms) and reconstruct speech waveform; 2) we jointly optimize the acoustic model (based on DelightfulTTS) and the vocoder (the decoder of VQ-GAN), with an auxiliary loss on the acoustic model to predict intermediate speech representations. Experiments show that DelightfulTTS 2 achieves a CMOS gain +0.14 over DelightfulTTS, and more method analyses further verify the effectiveness of the developed system.
A Study of Syntactic Multi-Modality in Non-Autoregressive Machine Translation
Jul 09, 2022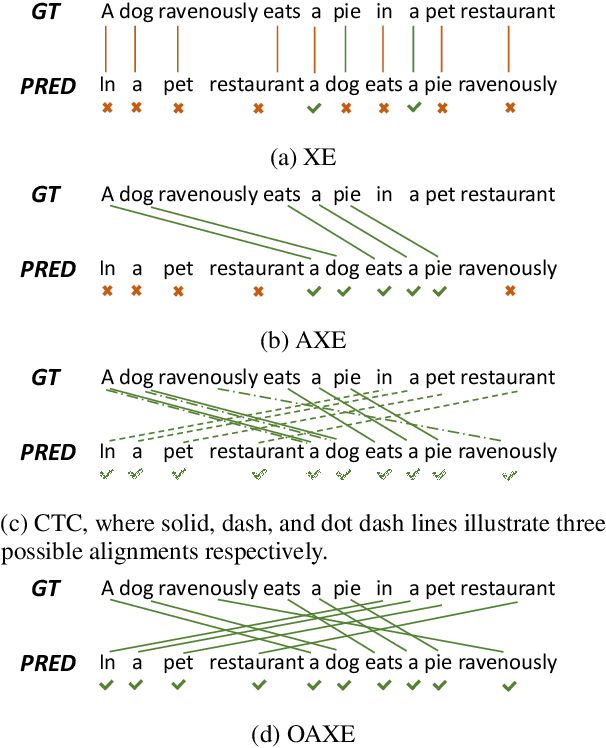
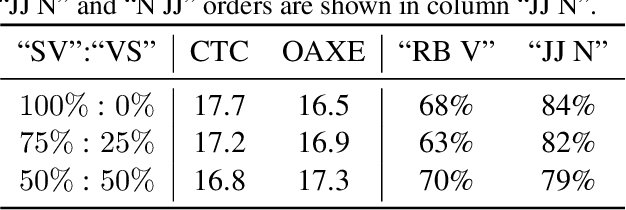
It is difficult for non-autoregressive translation (NAT) models to capture the multi-modal distribution of target translations due to their conditional independence assumption, which is known as the "multi-modality problem", including the lexical multi-modality and the syntactic multi-modality. While the first one has been well studied, the syntactic multi-modality brings severe challenge to the standard cross entropy (XE) loss in NAT and is under studied. In this paper, we conduct a systematic study on the syntactic multi-modality problem. Specifically, we decompose it into short- and long-range syntactic multi-modalities and evaluate several recent NAT algorithms with advanced loss functions on both carefully designed synthesized datasets and real datasets. We find that the Connectionist Temporal Classification (CTC) loss and the Order-Agnostic Cross Entropy (OAXE) loss can better handle short- and long-range syntactic multi-modalities respectively. Furthermore, we take the best of both and design a new loss function to better handle the complicated syntactic multi-modality in real-world datasets. To facilitate practical usage, we provide a guide to use different loss functions for different kinds of syntactic multi-modality.
Transcormer: Transformer for Sentence Scoring with Sliding Language Modeling
Jun 05, 2022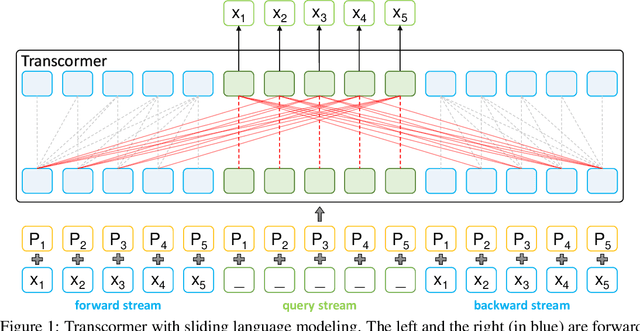

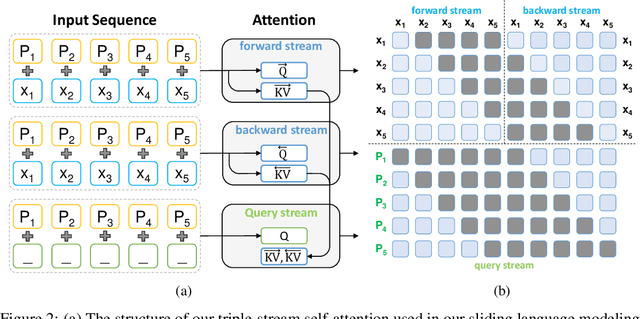
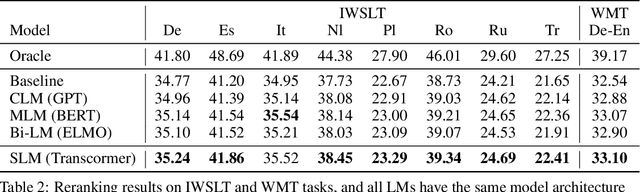
Sentence scoring aims at measuring the likelihood score of a sentence and is widely used in many natural language processing scenarios, like reranking, which is to select the best sentence from multiple candidates. Previous works on sentence scoring mainly adopted either causal language modeling (CLM) like GPT or masked language modeling (MLM) like BERT, which have some limitations: 1) CLM only utilizes unidirectional information for the probability estimation of a sentence without considering bidirectional context, which affects the scoring quality; 2) MLM can only estimate the probability of partial tokens at a time and thus requires multiple forward passes to estimate the probability of the whole sentence, which incurs large computation and time cost. In this paper, we propose \textit{Transcormer} -- a Transformer model with a novel \textit{sliding language modeling} (SLM) for sentence scoring. Specifically, our SLM adopts a triple-stream self-attention mechanism to estimate the probability of all tokens in a sentence with bidirectional context and only requires a single forward pass. SLM can avoid the limitations of CLM (only unidirectional context) and MLM (multiple forward passes) and inherit their advantages, and thus achieve high effectiveness and efficiency in scoring. Experimental results on multiple tasks demonstrate that our method achieves better performance than other language modelings.
BinauralGrad: A Two-Stage Conditional Diffusion Probabilistic Model for Binaural Audio Synthesis
May 30, 2022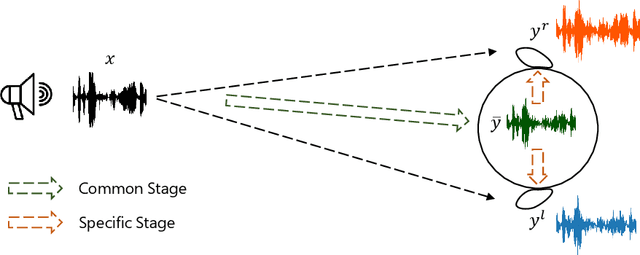

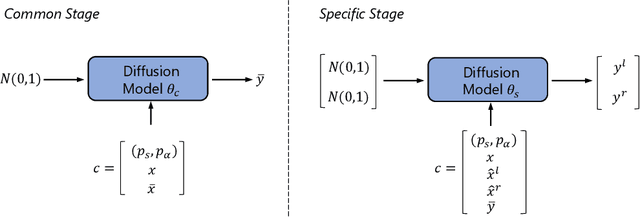

Binaural audio plays a significant role in constructing immersive augmented and virtual realities. As it is expensive to record binaural audio from the real world, synthesizing them from mono audio has attracted increasing attention. This synthesis process involves not only the basic physical warping of the mono audio, but also room reverberations and head/ear related filtrations, which, however, are difficult to accurately simulate in traditional digital signal processing. In this paper, we formulate the synthesis process from a different perspective by decomposing the binaural audio into a common part that shared by the left and right channels as well as a specific part that differs in each channel. Accordingly, we propose BinauralGrad, a novel two-stage framework equipped with diffusion models to synthesize them respectively. Specifically, in the first stage, the common information of the binaural audio is generated with a single-channel diffusion model conditioned on the mono audio, based on which the binaural audio is generated by a two-channel diffusion model in the second stage. Combining this novel perspective of two-stage synthesis with advanced generative models (i.e., the diffusion models),the proposed BinauralGrad is able to generate accurate and high-fidelity binaural audio samples. Experiment results show that on a benchmark dataset, BinauralGrad outperforms the existing baselines by a large margin in terms of both object and subject evaluation metrics (Wave L2: 0.128 vs. 0.157, MOS: 3.80 vs. 3.61). The generated audio samples are available online.
NaturalSpeech: End-to-End Text to Speech Synthesis with Human-Level Quality
May 10, 2022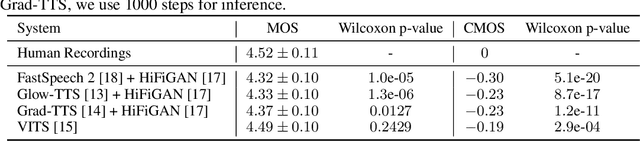
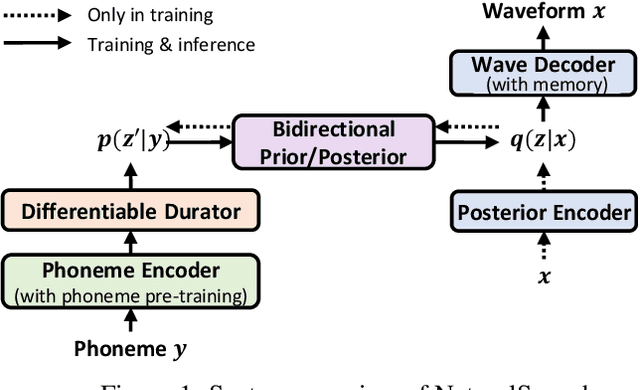
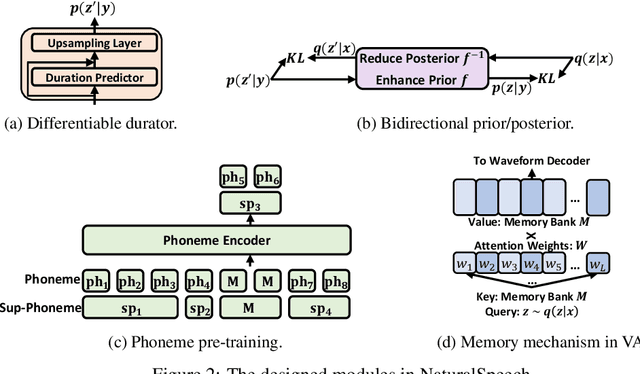
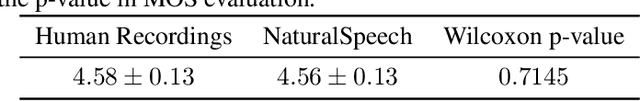
Text to speech (TTS) has made rapid progress in both academia and industry in recent years. Some questions naturally arise that whether a TTS system can achieve human-level quality, how to define/judge that quality and how to achieve it. In this paper, we answer these questions by first defining the human-level quality based on the statistical significance of subjective measure and introducing appropriate guidelines to judge it, and then developing a TTS system called NaturalSpeech that achieves human-level quality on a benchmark dataset. Specifically, we leverage a variational autoencoder (VAE) for end-to-end text to waveform generation, with several key modules to enhance the capacity of the prior from text and reduce the complexity of the posterior from speech, including phoneme pre-training, differentiable duration modeling, bidirectional prior/posterior modeling, and a memory mechanism in VAE. Experiment evaluations on popular LJSpeech dataset show that our proposed NaturalSpeech achieves -0.01 CMOS (comparative mean opinion score) to human recordings at the sentence level, with Wilcoxon signed rank test at p-level p >> 0.05, which demonstrates no statistically significant difference from human recordings for the first time on this dataset.